U bent hier
Beschikbaarstellen
Meet the Librarians: Catherine Falls, Community Webs
To celebrate National Library Week 2022, we are taking readers behind the scenes to Meet the Librarians who work at the Internet Archive and in associated programs.
In the spring of 2021, Catherine Falls was hired by the Internet Archive to launch the Community Webs program in Canada. She was excited about the prospect of helping public libraries, museums, local historical societies and archives digitally preserve important material.
 Catherine Falls
Catherine Falls
“Most web archiving happens at really large institutions, so much of the experience of local communities is missing from the historic record. It’s giving us a biased view of contemporary society,” Falls said. “The more of these local organizations that we can get to do this archiving, the more the historic record will be brought into balance.”
Since her efforts began, the Internet Archive has partnered with 43 institutions and organizations in Canada to build community-based collections. Falls said it’s been rewarding to follow the growth and variety of web-archiving projects . For example, the Milton Public Library in Ontario is working with the Halton Black History Awareness Society and other organizations to document items that may not otherwise be captured on the web. Meanwhile, the ArQuives: Canada’s LGBTQ2+ Archives is working with its community members to build web archive collections that capture the community’s web presence.
Falls earned bachelor’s degrees in commerce and art history from the University of British Columbia. She also has a master’s degree in library science and a master’s degree in art history from the University of Toronto. Before coming to the Internet Archive, she worked as an archivist in Canada at several institutions including York University and the Archives of Ontario.
“I’m interested in the free circulation of ideas and the library as a place where public knowledge is accessible.”
Catherine Falls, Community Webs“I was drawn to libraries as a kind of place that facilitates research–which for me is the most exciting phase of any project,” Falls said. “I’m interested in the free circulation of ideas and the library as a place where public knowledge is accessible. I like how the intellectual possibilities of a library intersect with the library as a community space.”
 Catherine Falls
Catherine Falls
Falls says her background gives her a solid understanding of the basic functions of the library and the common language used within the profession. With that theoretical grounding, she said she can approach her work from a critical perspective to make improvements.
“It’s important to keep in mind that libraries are not infallible institutions. We need to be constantly questioning our practice and finding ways to be better,” Falls said. “It’s easy to say libraries are these beautiful, idyllic institutions. But I think it’s healthy to take a critical eye toward the work we do so that we can try to live up to our ideals in terms of whose stories we tell, who has access to our services, and what is preserved for the long term.”
Falls said she enjoys the mission-driven focus of the Internet Archive. Operating in the library, technology and archival world, it has a dynamic, nimble culture that provides fertile ground in which to explore new ideas, she said.
Falls’ favorite holdings are among some of the quirkier arts-related web archive collections in the Internet Archive: University of Michigan, School of Information, 20th Century Minimalist Music, Dalhousie University, Artist-Run Centres in Halifax, Nova Scotia, and Corning Museum of Glass, Contemporary Glass Podcasts.
The post Meet the Librarians: Catherine Falls, Community Webs appeared first on Internet Archive Blogs.
Meet the Librarians: Jessamyn West, Accessibility
To celebrate National Library Week 2022, we are taking readers behind the scenes to Meet the Librarians who work at the Internet Archive and associated programs.
In her work, Jessamyn West is driven by a desire to help people and remove barriers to access.
“When I went to library school, I realized a lot of the things that were important to me lined up with library values,” West said. “Anti-censorship, intellectual freedom, and serving all the people — not just the people who can afford it, not just the people who can make it up two flights of stairs, not just people who can read small print. All the people.”
 Jessamyn West
Jessamyn West
West is living out her values, processing requests from individuals to participate in the Internet Archive’s program for users with print disabilities. She receives emails from people around the world with blindness, low-vision, dyslexia, brain injuries and other cognition problems who need accessible content. In her role, West has helped qualify thousands of patrons to receive materials in alternative digital formats.
Her qualifying work for the Internet Archive is among a variety of activities that keeps West busy with the Vermont Mutual Aid Society. West works part-time at the Kimball Library in Randolph, Vermont, where she helps adults in her community learn to use technology. She also does public speaking on the digital divide and other technology access issues, as well as writes a monthly column for Computers in Libraries Magazine.
“All I want to do is to get as much knowledge, to the most people, in as easy a way as possible.”
Jessamyn West, Vermont Mutual Aid SocietyWest grew up in Boxborough, Massachusetts, where she learned about computers from her dad and her mother introduced her to the importance of civic engagement and volunteerism. At Hampshire College, she earned a bachelor’s degree in linguistics and then moved to Seattle.
In 1994, West enrolled in the Graduate School of Library and Information Science (GSLIS) at the University of Washington. The shift to online information and the emergence of the web was presenting an opportunity and a challenge for libraries, which West said was exciting to be a part of at the time.
 Jessamyn West
Jessamyn West
Her first job after graduation in 1996 was with AmeriCorps at the Seattle Public Library helping adults learn to use computers. She later pivoted working for an internet service provider before moving back East. In Vermont, she continued working with libraries and set up her own tech consultancy. West has worked as a tech liaison for Open Library and has been a qualifying authority for the Internet Archive since 2018
“All I want to do is to get as much knowledge, to the most people, in as easy a way as possible,” West said. “I think it’s important that we have all kinds of libraries. I wouldn’t want a world that was only digital libraries and I certainly wouldn’t want a world that was only physical libraries. It’s really nice that many people, depending where you are, can have access to either or both in the way that makes the most sense for them.”
West maintains a professional website (jessamyn.info), a personal website (jessamyn.com and blogs at librarian.net. When she’s not working, she enjoys editing articles about librarians and library topics on Wikipedia, playing pub trivia, creating moss terrariums, and writing postcards.
Among West’s favorite items at the Internet Archive: The Middlebury College collection of Vermont Life Magazine and The Great 78 Project.
The post Meet the Librarians: Jessamyn West, Accessibility appeared first on Internet Archive Blogs.
Meet the Librarians of the Internet Archive
In celebration of National Library Week, we’d like to introduce you to some of the professional librarians who work at the Internet Archive and in projects closely associated with our programs. Over the next two weeks, you’ll hear from librarians and other information professionals who are using their education and training in library science and related fields to support the Internet Archive’s patrons.
 Jessamyn West
Jessamyn West
 Catherine Falls (4/6)
Catherine Falls (4/6)
 Sawood Alam (4/8)
Sawood Alam (4/8)
 Lisa Seaberg (4/12)
Lisa Seaberg (4/12)
 Alexis Rossi (4/14)
Alexis Rossi (4/14)
What draws librarians to work at the Internet Archive? From patron services to collection management to web archiving, the answers are as varied as the departments in which these professionals work. But a common theme emerges from the profiles—that of professionals wanting to use their skills and knowledge in support of the Internet Archive’s mission, “Universal Access to All Knowledge.”
We hope that over these next two weeks you’ll learn something about the librarians working behind the scenes at the Internet Archive, and you’ll come to appreciate the training and dedication that influence their daily work. We’re pleased to help you “Meet the Librarians” during this National Library Week and beyond:
- Jessamyn West, accessibility – Vermont Mutual Aid Society
- Catherine Falls, Community Webs – Internet Archive (Online April 6)
- Sawood Alam, web archiving – Internet Archive (Online April 8)
- Lisa Seaberg, patron services – Internet Archive (Online April 12)
- Alexis Rossi, media and access – Internet Archive (Online April 14)
The post Meet the Librarians of the Internet Archive appeared first on Internet Archive Blogs.
Internet Archive Joins Opposition to the “SMART Copyright Act”
In the past few weeks, governments around the world have renewed their efforts to restrain free expression online. In Canada, a revised “Online Streaming Act” comes as the latest in a long-running attempt to bring streaming under a restrictive regulatory regime. In the UK, a new “Online Safety Bill” seeks to censor “legal but harmful content” in a way that would threaten open digital spaces. And in the USA, content filtering is once again being floated as the answer to online copyright infringement, this time via the “SMART Copyright Act of 2022“.
If the SMART Copyright Act were to pass, the Copyright Office would select a “technical measure” every three years that online service providers would be required to implement. The intent, as supporters have made clear, is for the Copyright Office to mandate technical measures that would automatically “filter out” allegedly infringing material. Lobbyists and lawyers for the owners of these technologies would be allowed to petition the Copyright Office to require the adoption of their own products. Whatever technology is adopted would then have to be purchased and implemented by anyone swept up by the law—from big tech platforms to your local research library. Failure to do so could be punishable by millions of dollars in civil penalties, among other things. As Professor Eric Goldman has written:
The SMART Copyright Act is a thinly veiled proxy war over mandatory filtering of copyrighted works. . . mandatory filters are error-prone in ways that hurt consumers, and they raise entry barriers in ways that reduce competition.
More generally, the SMART Copyright Act would give the Copyright Office a truly extraordinary power–the ability to force thousands of businesses to adopt, at their expense, technology they don’t want and may not need, and the mandated technologies could reshape how the Internet works.
Wouldn’t It Be Great if Internet Services Had to License Technologies Selected by Hollywood? (Comments on the Very Dumb “SMART Copyright Act”), from Eric Goldman’s Technology & Marketing Law Blog on March 23, 2022This bill and its supporters do not represent the public’s interest in fair copyright policy and a robust and accessible public domain. That is a shame, because much good could be done if policymakers would put the public’s interest first. For example, the Copyright Office—which holds records of every copyright ever registered, including all those works which have passed into the public domain—could help catalogue the public domain and prevent it from being swept up by today’s already-overzealous automated filtering technologies (an idea inspired by this white paper from Paul Keller and Felix Reda). Instead, the public domain continues to be treated as acceptable collateral damage in the quest to impose ever-greater restrictions on free expression online.
It is no surprise that the Electronic Frontier Foundation, Public Knowledge, the Library Copyright Alliance, and many others have voiced criticism of this harmful bill. Today, Internet Archive joins these and other signatories in a joint letter to the bill’s cosponsors, Senators Tillis and Leahy, expressing opposition and concern. You can read the letter here.
The post Internet Archive Joins Opposition to the “SMART Copyright Act” appeared first on Internet Archive Blogs.
Ukrainian Book Drive: Please Contribute

The Internet Archive is requesting donations of Ukrainian books and books useful to Ukrainians. The books will be preserved, digitized and lent (for free to one user at a time) over the Internet. The Internet Archive is prioritizing the digitization and hosting of relevant materials for Ukrainians.
Already the University of Toronto and University of Alberta has sponsored the digitization of sizable Ukrainian collections, where the total collections on archive.org total over 8,000 items in Ukrainian.
But we need much more to support Ukrainians, many of whom are displaced and do not have access to their schools and libraries.
We need your help. Together we can preserve all published works and make them as widely available as we can.
The Internet Archive provides free downloading of public domain materials, services for those with print disabilities, free Controlled Digital Lending of books, free interlibrary loan services, free hosting for materials that are uploaded to archive.org, and supports web archiving efforts. These services can be more relevant to Ukrainians with your help.
Please donate physical books and other materials, upload relevant materials to archive.org, and also consider financial support for our activities.
The post Ukrainian Book Drive: Please Contribute appeared first on Internet Archive Blogs.
Mission Impossible: The Compuserve Chapter
There are parts of technology history (frankly, any history) that are thought to be critical to telling the story, and utterly lost. Pieces and fragments will rise up out of the darkness, but a cohesive collection of what once made up a chapter will be thought gone forever.

Sadly, this happens a lot.
But in one special exception, the Computer History Museum found itself with an opportunity to seize the moment.
Compuserve is considered to be the first major online service in the United States. Founded in the era of “time-sharing” services (paying to use a computer during the main owner’s quiet hours), this subsidiary of Golden United Life Insurance moved from 1969 to 1979 in the kind of obscurity befitting a simple business-to-business service providing access to PDP mainframes.
This all changed in 1979 with the rebranding of Compuserve Information Service (CIS), which marketed itself to mainstream computer users, providing chat, games, and storehouses of information for an hourly fee to who ever could afford the phone bills and equipment to do so. It is here that Compuserve (and later services like The Source, America On-Line and Prodigy) brought a bulk of folks online for the first time.
This service flourished through the 1980s and 1990s, and in what should be considered a reductive and surface description of the situation, slowly broke apart via acquisitions, shifting priorities and the dominance of the World Wide Web providing many aspects of what Compuserve had previously done exclusively.
By the time this 2000s-era chapter was over, Compuserve was more a brand and a memory. But it had still reigned in the minds of many as the beginning, the launching pad for a lot of what people came to expect the online world to provide.
It was assumed most of the history of Compuserve was gone – the hardware, software and documentation scattered to the winds.
Not so.
As explained in this blog entry that literally reads like a movie script, the Computer History Museum has acquired, sorted, and added a major amount of Compuserve’s archives to their stacks. The collection had been sitting for decades, and was soon to be disposed of, when it was offered to CHM and they accepted.
Among these items that have been recovered are documents that are being given to the Internet Archive to scan and place online – instructions on how to operate a Compuserve service.
These opportunities to recover assumed-lost materials are extremely rare, but hope springs eternal that in rooms, attics and file cabinets around the world, there possibly lurk further discoveries, and happy endings. Almost like a movie.
The post Mission Impossible: The Compuserve Chapter appeared first on Internet Archive Blogs.
Join us April 5 for WHOLE EARTH: A Conversation with John Markoff

Join us on Tuesday, April 5 at 11am PT / 2pm ET for a book talk with John Markoff in conversation with journalist Steven Levy (Facebook: The Inside Story), on the occasion of Markoff’s new biography, WHOLE EARTH: The Many Lives of Stewart Brand.
Register nowFor decades Pulitzer Prize-winning New York Times reporter John Markoff has chronicled how technology has shaped our society. In his latest book, WHOLE EARTH: The Many Lives of Stewart Brand (on-sale now), Markoff delivers the definitive biography of one of the most influential visionaries to inspire the technological, environmental, and cultural revolutions of the last six decades.
 Purchase your copy today
Purchase your copy today
Today Stewart Brand is largely known as the creator of The Whole Earth Catalog, a compendium of tools, books, and other intriguing ephemera that became a counterculture bible for a generation of young Americans during the 1960s. He was labeled a “techno-utopian” and a “hippie prince”, but Markoff’s WHOLE EARTH shows that Brand’s life’s work is far more. In 1966, Brand asked a simple question—why we had not yet seen a photograph of the whole earth? The whole earth image became an optimistic symbol for environmentalists and replaced the 1950s’ mushroom cloud with the ideal of a unified planetary consciousness. But after the catalog, Brand went on to greatly influence the ‘70s environmental movement and the computing world of the ‘80s. Steve Jobs adopted Brand’s famous mantra, “Stay Hungry, Stay Foolish” as his code to live by, and to this day Brand epitomizes what Markoff calls “that California state of mind.”
Register nowBrand has always had an “eerie knack for showing up first at the onset of some social movement or technological inflection point,” Markoff writes, “and then moving on just when everyone else catches up.” Brand’s uncanny ahead-of-the-curveness is what makes John Markoff his ideal biographer. Markoff has covered Silicon Valley since 1977, and his reporting has always been at the cutting edge of tech revolutions—he wrote the first account of the World Wide Web in 1993 and broke the story of Google’s self-driving car in 2010. Stewart Brand gave Markoff carte blanche access in interviews for the book, so Markoff gets a clearer story than has ever been set down before, ranging across Brand’s time with the Merry Pranksters and his generation-defining Whole Earth Catalog, to his fostering of the marriage of environmental consciousness with hacker capitalism and the rise of a new planetary culture.
Above all, John Markoff’s WHOLE EARTH reminds us how today, amid the growing backlash against Big Tech, Stewart Brand’s original technological optimism might offer a roadmap for Silicon Valley to find its way back to its early, most promising vision.
Purchase your copy of WHOLE EARTH: The Many Lives of Stewart Brand via the Booksmith, our local bookstore.
EVENT DETAILS
WHOLE EARTH: A conversation with John Markoff
April 5 @ 11am PT / 2pm ET
Register now
The post Join us April 5 for WHOLE EARTH: A Conversation with John Markoff appeared first on Internet Archive Blogs.
Volunteers Rally to Archive Ukrainian Web Sites
As the war intensifies in Ukraine, volunteers from around the world are working to archive digital content at risk of destruction or manipulation. The Internet Archive is supporting several preservation efforts including the Saving Ukrainian Cultural Heritage Online (SUCHO) initiative launched in early March.

“When we think about the internet, we think the data is always going to be there. But all this data exists on physical servers and they can get destroyed just like buildings and monuments,” said Quinn Dombrowski, academic technology specialist at Stanford University and co-founder of SUCHO. “A tremendous amount of effort and energy has gone into the development of these websites and digitized collections. The people of Ukraine put them together for a reason. They wanted to share their history, culture, language and literature with the world.”
Watch:
More than 1,200 volunteers with SUCHO have saved 10 terabytes of data including 14,000 uploaded items (images and PDFs) and captured parts of 2,300 websites so far. This includes material from Ukrainian museums, library websites, digital exhibits, open access publications and elsewhere.
The initiative is using a combination of technologies to crawl and archive sites and content. Some of the information is stored at the Internet Archive, where it can be discovered and accessed using open-source software.
Staff at the Internet Archive are committed to assisting with the effort, which aligns with the organization’s mission of universal access to knowledge, and aim to make the web more useful and reliable, said Mark Graham, director of the Wayback Machine.
“This is a pivotal time in history,” he said. “We’re seeing major powers engaged in a war and it’s happening in the internet age where the platforms for information sharing and access we have built, and rely on, the Internet and the Web, are at risk.”
The Internet Archive is documenting and making information accessible that might not otherwise be available, Graham said. For years, the Wayback Machine has been archiving about 950 Russian news sites and 350 Ukrainian news sites. Stories that are deleted or altered are being archived for the historical record.
“We’re seeing major powers engaged in a war and it’s happening in the internet age where the platforms for information sharing and access…are at risk.”
Mark Graham, director, Wayback MachineRecognizing the urgency of this moment, Dombrowski has been stunned by the response to help from archivists, scholars, librarians involved in cultural heritage and the general public. Volunteers need not have technical expertise or special language skills to be of value in the project.
“Many people were spending the days before they got involved with SUCHO scrolling the news and feeling helpless and wishing they could do something to contribute more directly towards helping out with the situation,” Dombrowski said. “It’s been really inspiring hearing the stories that people have told about what it’s meant to them to be able to be part of something like this.”

Gudrun Wirtz, head of the East European Department of the Bavarian State Library (Bayerische Staatsbibliothek) in Munich, was archiving on a smaller scale when she and other colleagues began to collaborate with SUCHO.
“We are committed to Ukraine’s heritage and horrified by this war against the people and their rich culture and the distorting of history going on,” Wirtz said. “As Germans we are especially shocked and reminded of our historical responsibility, because last time Ukraine was invaded it was 1941 by Nazi-Germany. We try to do everything we can at the moment.”
 Anna Kiljas, Tufts University
Anna Kiljas, Tufts University
The invasion of Ukraine hits particularly close to home for Anna Kijas, a librarian at Tufts University and co-founder of SUCHO, who is a Polish immigrant with family members who lived through Soviet occupation following WWII.
“Contributing to the SUCHO effort is something tangible that I can do and bring my expertise as a librarian and digital humanist in order to help preserve as much of the cultural heritage of the Ukrainian people as is possible,” said Kijas.
The third co-founder SUCHO, Sebastian Majstorovic, is with the Austrian Centre for Digital Humanities and Cultural Heritage.
The Internet Archive is providing technical support, tools and training to assist volunteers, including those with SUCHO, who are giving of their time.
Through Archive-It, a customizable self-service web archiving platform that captures, stores, and provides access to web-based content, free online accounts have been offered to volunteer archivists. Mirage Berry, business development manager for Archive-It, has coordinated support with other preservation partners including the Harvard Ukrainian Research Institute, the Center for Urban History of East Central Europe, and East European & Central Asian Studies Collections librarian Liladhar Pendse at University of California, Berkeley.
“It’s so incredible how quickly all of these archivists have pulled together to do this,” Berry said. “Everyone wants to do something. You don’t need to have a ton of technical experience. For anyone who is willing to learn, it’s a great jumping off point for web archiving.”
SUCHO organizers anticipate after the immediate emergency of website archiving is over, there will be an ongoing need to stay vigilant with data curation of Ukrainian material. To learn more and get involved, visit http://www.sucho.org.
The post Volunteers Rally to Archive Ukrainian Web Sites appeared first on Internet Archive Blogs.
Library as Laboratory Recap: Applications of Web Archive Research with the Archive Unleashed Cohort Program

From projects that compare public health misinformation to feminist media tactics, the Internet Archive is providing researchers with vital data to assist them with archival web collection analysis.
In the second of a series of webinars highlighting how the Internet Archive supports digital humanities research, five scholars shared their experience with the Archives Unleashed Project on March 16.
Archives Unleashed was established in 2017 with funding from the Andrew Mellon Foundation. The team developed open-source, user-friendly Archives Research Compute Hub (ARCH) tools to allow researchers to conduct scalable analyses, as well as resources and tutorials. An effort to build and engage a community of users led to a partnership with the Internet Archive.
A cohort program was launched in 2020 to provide researchers with mentoring and technical expertise to conduct analyses of archival web material on a variety of topics. The webinar speakers provided an overview of their innovative projects:

- WATCH: Crisis communication during the COVID-19 pandemic was the focus of an investigation by Tim Ribaric and researchers at Brock University in Ontario, Canada. Using fully extracted texts from websites of municipal governments, community organizations and others, the team compared how well information was conveyed to the public. The analysis assessed four facets of communication: resilience, education, trust and engagement. The data set was used to teach senior communication students at the university about digital scholarship, Ribaric said, and the team is now finalizing a manuscript with the results of the analysis.

- WATCH: Shana MacDonald from the University of Waterloo in Ontario Canada applied archival web data to do a comparative analysis of feminist media tactics over time. The project mapped the presence of feminist key concepts and terms to better understand who is using them and why. The researchers worked with the Archives Unleashed team to capture information from relevant websites, write code and analyze the data. They found the top three terms used were “media, culture and community,” MacDonald said, providing an interesting snapshot into trends with language and feminism.

- WATCH: At the University of Siegen, a public research university in Germany, researchers examined the online commenting system on new websites from 1996 to 2021. Online media outlets started to remove commenting systems in about 2015 and the project was focused on this time of disruption. With the rise of Web 2.0 and social media, commenting is becoming increasingly toxic and taking away from the main text, said the university’s Robert Jansma. Technology providers have begun to offer ways to stem the tide of these unwanted comments and, in general, the team discovered comments are not very well preserved.

- WATCH: Web archives of the COVID-19 crisis through the IIPC Novel Coronavirus dataset was analyzed by a team at the University of Luxembourg led by Valérie Schafer. As a shared, unforeseen, global event, the researchers found vast institutional differences in web archiving. Looking at tracking systems from the U.S. Library of Congress, European libraries and others, the team did not see much overlap in national collections and are in the midst of finalizing the project’s results.

- WATCH: Researchers at Arizona State University worked with ARCH tools to compare health misinformation circulating during the HIV/AIDS crisis and COVID-19 pandemic. ASU’s Shawn Walker did a text analysis to link patterns and examine how gaps in understanding of health crises can fuel misinformation. In both cases, the community was trying to make sense of information in an uncertain environment. However, the government conspiracy theories rampant in the COVID-19 pandemic were not part of the dialogue during the HIV/AIDS crisis, Walker said.
Archives Unleashed is accepting applications for its 2022-23 cohort research teams. For more information, view the application & instructions: https://archivesunleashed.org/cohorts2022-2023/.
Up next in the Library as Laboratory series:

The next webinar in the series, Hundreds of Books, Thousands of Stories: A Guide to the Internet Archive’s African Folktales will be held March 30. Register now
The post Library as Laboratory Recap: Applications of Web Archive Research with the Archive Unleashed Cohort Program appeared first on Internet Archive Blogs.
Integrating Web-Based Content into a Vibrant Local History Collection: South Pasadena Public Library and the Community Webs Program
Guest post by: Olivia Radbill, Adult Services/Local History Librarian, South Pasadena Public Library
This post is part of a series written by members of Internet Archive’s Community Webs program. Community Webs advances the capacity for community-focused memory organizations to build web and digital archives documenting local histories and underrepresented voices. For more information, visit communitywebs.archive-it.org/
The South Pasadena Public Library (SPPL) is a single branch library system located in the small city of South Pasadena, California, just fifteen minutes from downtown Los Angeles. SPPL serves a population of approximately 25,000 residents, many of whom are very dedicated to preservation and local history. As the Adult Services/Local History Librarian at SPPL, I regularly interact with local organizations, City staff, City commissioners, and residents in search of the many little-known details of South Pasadena’s history. My role not only entails organizing, processing, and making accessible local history, but also archiving current events that will inevitably be the subject of future research.
At the onset of the COVID-19 pandemic, when the SPPL building was first shut down and our physical Local History Collection made inaccessible, Library staff sought to provide means of bringing local history to digital platforms in a consistent and manageable way. Our first means of public outreach was through the creation of digital exhibits using ArcGIS Storymaps, an interactive web-mapping tool used to host narrative multimedia displays. Exhibits in the series include Ray Bradbury: Celebrating 100 Years, South Pasadena Public Library: Twelve Decades and Counting, City of Trees: Our Urban Tree Canopy, Summers in SoPas: Highlights of Summers Past, and COVID-19: Living History Project. To date, this series has garnered thousands of views.
 Screenshot of “Summers in SoPas: Highlights of Summers Past” online exhibit.
Screenshot of “Summers in SoPas: Highlights of Summers Past” online exhibit.
While this series did quell some of the community desire to interact with the Local History Collection, it did not address the needs of the community in regards to born-digital content. The COVID-19 pandemic highlighted certain gaps in our collection. One of the most notable gaps was the lack of any born-digital or web-archived content. Previously, SPPL has relied primarily on physical donations and physical City documentation. However, once these objects became inaccessible to both Library staff and patrons during our initial COVID-19 closure in March 2020, we sought means of preserving documentation that has increasingly moved to exclusively web-based platforms. For example, in April 2020 the City of South Pasadena launched “City Hall Scoop”, an online blog intended to provide quick, reliable news updates to local residents. It became imperative for Library staff to actively seek out and ensure preservation of this kind of content.
 The South Pasadena Public Library homepage on Archive-It.
The South Pasadena Public Library homepage on Archive-It.
At the onset of our involvement in the Community Webs program, I strove to ensure that the objective of our internet archiving was specific, consistent, and attainable. After careful consideration, the following categories were determined to be priorities to the SPPL Local History Collection: City Government, Local Newspapers, and Nonprofit Organizations. Based on these categories we have identified many relevant websites, but chose to focus primarily on official websites and social media pages, to add to the Archive-It platform. The Community Webs project has been an invaluable resource for addressing the needs of both the SPPL staff and the community. Online trainings have aided significantly in overcoming learning curves, helped us determine the scope of our archiving project, and have allowed SPPL to create a system in which web-based content is an integral part of our Local History Collection. SPPL, as of March 2022, has archived, either singularly or on a recurring basis, eleven websites. We are hoping to archive 22 new sites by the end of the year, doubling the number we reached last year.
The post Integrating Web-Based Content into a Vibrant Local History Collection: South Pasadena Public Library and the Community Webs Program appeared first on Internet Archive Blogs.
New Project Will Unlock Access to Government Publications on Microfiche
Government documents from microfiche are coming to archive.org based on the combined efforts of the Internet Archive, Stanford University Libraries, and other library partners. The resulting files will be available for free public access to enable new analysis and access techniques.
Microfiche cards, which contain miniaturized thumbnails of the publication’s pages, are starting to be digitized and matched to catalog records by the Internet Archive. Once in a digital format and preserved on archive.org, these documents will be searchable and downloadable by anyone with an Internet connection, since U.S. government publications are in the public domain.
 Sample microfiche card
Sample microfiche card
Seventy million pages on over one million microfiche cards have been contributed for scanning from Claremont Colleges, Evergreen State College, Stanford University, University of Alberta, University of California San Francisco, and the University of South Carolina. Other libraries are welcome to join this project.
The Federal Depository Library Program (FDLP), founded in 1813, provides designated libraries with copies of bills, laws, congressional hearings, regulations, and executive and judicial branch documents and reports to share with the public. Initially, the documents were on paper but in the 1970s, the U.S. Government Publishing Office began to use microfiche.
“While the new format saved space, the viewing and copying issues were exacerbated, so microfiche was never a favorite of the public,” said James Jacobs, the U.S. government information librarian at Stanford University Libraries. Stanford, which joined the FDLP in 1895, is donating approximately 250,000 federal government microfiche documents to the Archive. Stanford will then host digital copies of the documents in its digital repository in order to preserve and broaden digital access to the materials for the Stanford community and beyond. “That was one of the main reasons I was excited to have this content digitized. These important publications will be online and more accessible.”
Before loading up the trucks with the microfiche cabinets, librarians at Stanford are organizing the cards and metadata to more easily share metadata with the Internet Archive and so the digital scans will match up with their cataloging system. Not only will the digitized documents be available through the Archive, but a copy will be added to the Stanford digital repository for accessing and preservation.
Once all the documents are digitized, access will be greatly enhanced, and it will allow people to do broader machine analysis of digital content to track larger trends across years of technical reports or agency activity, Jacobs said.
The collection includes reports from the Environmental Protection Agency (EPA), NASA, the Department of Interior, and other government agencies from the 1970s to the present. There are also transcripts of congressional hearings and other Congressional material that contain discussion of potential laws or issues of concern to the public, Jacobs said.
“From water to nuclear energy to frogs, whatever it is, Congress has a meeting and invites experts to talk about the issues,” Jacobs said. “It’s a way for the public to peek into the legislative process.”
 Laval University, CC BY-SA 4.0, via Wikimedia Commons
Laval University, CC BY-SA 4.0, via Wikimedia Commons
Microfiche is not a format that can be easily read without using a machine in a library building. Many members of the public are not aware of the material available on microfiche so the potential for finding and using them is heightened once these documents are digitized. And as the information is shared with other federal depository libraries, there will be a ripple effect for researchers, academics, students, and the general public in gaining access.
“The Internet Archive is looking for more microform donations and currently has the funding, thanks to a grant from the Kahle/Austin Foundation, to transform the cards into digital documents, opening up a rich collection of public documents to a wider audience,” said Liz Rosenberg, donations manager. “The Archive can also cover the cost of shipping and provide a home for microforms that libraries no longer have the space to store and wish to gain digital access.” Learn more about the Internet Archive’s donations program.
With this expanded access to the workings of government, Jacobs said that digitizing microfiche is helping promote the open sharing of knowledge: “You have to have an informed citizenry in order to have a democracy.”
#
If your library has microfiche collections that you’d like to donate, you can learn more about the Internet Archive’s donations program through our Help Center. Please contact us with inquiries or when you are ready to start a donation.
The post New Project Will Unlock Access to Government Publications on Microfiche appeared first on Internet Archive Blogs.
In an Ever-Expanding Library, Using Decentralized Storage to Keep Your Materials Safe

Memory institutions know the headaches of storing their ever-expanding physical collections: fire, flood, access & space over the long-term. But storing digital assets presents even more diverse challenges: attacks by hackers, deep fakes, censorship, and the unforeseeable cost of storing bits for centuries. Could a new approach—decentralized storage—offer some solutions? That was the focus of an Internet Archive webinar on February 24.
The online event was second in a series of six workshops entitled, “Imagining a Better Online World: Exploring the Decentralized Web,” co-sponsored by DWeb and Library Futures, and presented by the Metropolitan New York Library Council (METRO).
In the utopian version of decentralized storage, there would be collaborative, authenticated, co-hosted collections. Wendy Hanamura, Director of Partnerships at the Internet Archive, said this would make information less prone to censorship and less vulnerable to a security breach. “Taken together, resiliency, persistence, self-certification and interoperability — that is the promise of decentralized storage,” she said.
Librarians and archivists are a key part of creating a solution that is networked, said Jonathan Dotan, Founder of the Starling Lab, the first major research lab devoted to Web 3.0 technologies.
“As a community, if we can all come together to guarantee the integrity of information, we’re in a unique position to create a new foundation of digital trust,” Dotan said. “When we think about decentralization, it’s not a single destination. It’s an unfolding process in which we continually strive to bring more and more diverse nodes into our system. And the more diverse those notes are, the more that they’re going to be able to store and verify information.”
Other speakers at the webinar included Arkadiy Kukarkin, Decentralized Web Lead Engineer for the Internet Archive, and Dominick Marino, Senior Solutions Architect and Ecosystem lead at STORJ.
The series kicked off on January 27 with an introductory session establishing some common vocabulary for this new approach to digital infrastructure.

Download the Session 2 Resource Guide
Register for the next session:
Keeping Your Personal Data Personal: How Decentralized Identity Drives Data Privacy
March 31 @ 1pm PT / 4pm ET
Register here
The post In an Ever-Expanding Library, Using Decentralized Storage to Keep Your Materials Safe appeared first on Internet Archive Blogs.
Guest Blog: An Egyptian Perspective on American Book Banning
 Hassan Said is a third-year law student at Santa Clara University School of Law. Born and raised in Cairo, Egypt, Hassan is currently interning at the Internet Archive for the spring semester.
Hassan Said is a third-year law student at Santa Clara University School of Law. Born and raised in Cairo, Egypt, Hassan is currently interning at the Internet Archive for the spring semester.
I was fourteen years old when I watched the Egyptian revolution unfold before my eyes. One of the main things people protested against was the degree of censorship everyone was subjected to. Book bans in particular were popular for many decades leading up to the revolution. Interestingly, eleven years after the revolution, I am seeing the same arguments the Egyptian government made in Egypt for book bans made here in America by local school boards and politicians. My experience has taught me that, regardless of content, book banning is harmful because it weakens the democratic process and works against making societies cohesive.
The Egyptian government extensively banned books during the latter half of the 20th century. Those in power argued for the need for more parental and educational control. They also made arguments focused on the effect certain books have on polarizing the public on race, politics, religion, or sex and the importance of maintaining social order and decorum. Books discussing political and religious themes were banned with the most frequency, including a novel by Nobel laureate Naguib Mahfouz. Thus, the product of book banning was the revolution—many years later. In essence, the revolution was an amalgamation of a seemingly unidentified people, split among social, religious, and political lines, coming together to reconcile the calamities of over half a century. Namely, the effects of being unable to discuss relevant and pertinent ideas and issues—a side effect of book bans.
As I am wrapping up my last semester in law school I see parallels of what happened in Egypt taking place in America: people split among political, social, and sometimes religious lines. They are divided over issues that have come up partly due to discrimination, police brutality, and more recently and intensely, book bans.
In Florida, a school removed 16 books pending review because they contained “obscene material,” including Khaled Hosseini’s The Kite Runner and Toni Morrison’s Beloved. In Washington, a school district removed Harper Lee’s To Kill a Mockingbird because of its depiction of race relations and use of racist language. And last month, a school board in Tennessee voted unanimously to ban Maus, a Pulitzer Prize-winning graphic novel about the Holocaust. The school board argued this book should not be taught in classrooms because it contains material that is inappropriate for students, specifically because “of its unnecessary use of profanity and nudity and its depiction of violence and suicide.” In other words, people and local governments are making the same arguments I heard growing up supporting book bans. Specifically, they stress the need for more parental control, the inappropriateness of discussing sexuality, and the dangers of debating race. The same harmful effects I saw in Egypt, I see here: book banning is weakening the democratic process and working against making society less tolerant and cohesive.
Perhaps it is necessary to remind ourselves why we read in the first place. We read to empower ourselves and others. We read to learn perspectives and perhaps to develop our own. We read to understand the power of ideas and the effect they had and continue to have on us as a society. We read to open mental doors and windows of tolerance. We read to challenge ourselves, to reach new heights and understanding. We could disagree with many books, sure, but that is precisely why we read: to critically think about issues and better ourselves and our society in the process. Stated differently, we read to maintain and strengthen the social threads that weave our communities tightly together.
Book-banning in today’s online world is largely a political act. Books may not be available in local libraries, but they remain available on the Internet and in online libraries like the Internet Archive’s, where you can borrow them for free. In a way, the Internet Archive plays a similar role to that of the Internet in pre-revolution Egypt: it is a space where people can read, listen, and watch uploaded works and items compiled in one place. But online libraries aren’t completely safe either. For example, the Goliath of the publishing world, Penguin Random House (PRH), used copyright law as an excuse to effectively ban Maus from the Internet Archive’s digital shelves. PRH made it clear that they wanted to assert total control over this banned book in order to maximize its own profits in the wake of the Tennessee School Board’s decision. This has the same impact on society as book banning.
When societies censor books, they threaten to lose their culture and, in time, their identity. By banning books, societies jeopardize their political and social institutions because books are the primary tool to spread and develop ideas. With the fight to ban books extending to the online world, the threat has become as clear as ever. You could argue that book banning is about many things—the illusion of parental control, the polarization of the public, or disagreement on topics like race, politics, or sex. However, the bottom line remains clear: book bans serve no one, and no society can overcome its issues by banning books.
The post Guest Blog: An Egyptian Perspective on American Book Banning appeared first on Internet Archive Blogs.
Introduction to Deep Learning
Instructors: Muhammad Abdul-Mageed, Ganesh Jawahar, and Peter Sullivan; Deep Learning and NLP Group, The University of British Columbia & InterPARES Trust AI
Google Summer of Code is a Win-Win for Contributing Students and Mentoring Organizations: Thank you Google

Lavanya Singh was eager to write lots of code after her freshman year of college, but she knew it was hard to find a place that would give her a chance. Then she landed a spot with the Google Summer of Code (GSoC) program working at the Internet Archive.
Paired with Mark Graham, director of The Wayback Machine, Singh was asked to create a systematic way to archive news sources from all around the world.
 Lavanya Singh, Google Summer of Code contributor.
Lavanya Singh, Google Summer of Code contributor.
“Mark basically gave me that problem and said: ‘Go figure it out,’” she recalls, grateful for the challenge, the tight knit community at the Internet Archive, and the mentorship provided throughout the project. “The Internet Archive really trusts their interns and gives you an opportunity to do huge scale technical projects that are going to be useful in the long run.”
The experience gave Singh skills and confidence that led to other internships and a job as a software engineer, following graduation this spring from Harvard University with a degree in computer science and philosophy.
For 17 years, GSoC has given more than 18,000 students from 112 countries the chance to learn about programming up close. Google selects students (called “contributors”) and matches them with organizations doing open-source projects. All told, the students have created 40 million lines of code since the program’s inception in 2005. It has helped launch careers, like Singh’s, and provided a pipeline of potential employees for the 746 organizations that have participated. Google recently posted its Google Summer of Code timeline for 2022 for applicants for the paid positions, which last 12 weeks.
“It is truly a benefit and service to students. For some, it can be transformational,” said Singh’s mentor, Graham, of the Internet Archive. “But it also helps us. It’s a way to learn about new talent. And it’s a way for the Internet Archive to increase our visibility and demonstrate that we are part of this community of organizations.”
GSoC provides an infrastructure to match promising programmers with projects that can be difficult to find and is especially relevant now with people working remotely, said Brenton Cheng, a senior engineer with the Internet Archive.
“It’s been an incredible way by which people all over the world can get opportunities to work with companies, creating openings that might not be available to them otherwise,” said Cheng, who has mentored several student contributors over the years.
Staff assign mini-projects designed to give students hands-on experience and a sense of accomplishment. Students are also included in team meetings, invited to give input and present their work, said Cheng.
Recent GSoC projects and contributors:
- Rakesh Chinta focused on building advanced features for the existing Chrome extension for the Wayback Machine (2017);
- Zhengyue Cheng created a “map” of the web via the Wayback Machine (2018);
- Salman Shah worked with the Open Library team to modernize and increase the coverage of its book catalog and improve website reliability (2018);
- Kanchan Joshi improved site navigation for Archive.org (2019);
- Giacomo Cignoni made a significant contribution with his BookReader Selection & Dark Mode project. He worked to give public domain works the ability to have text selection over the book page images (2020);
- Tabish Shaikh helped improve the adoption of Open Library with his Adoption of BookLovers project – redesigning the Book Page and making it clearer what services were offered (2020);
- Nolan Windham worked on the Open Book Genome Project. It centered on the ability for computers and machines to read a book on our behalf, and extract metadata that can then be made publicly useful to the world. Through the process, nearly 10,000 new books were added to the lending system (2021);
- Xin Yue Chen focused on linking Wikipedia references to Internet Archive books (2021).
“We’re helping to train the next generation of developers,” Cheng said. “On the flip side, we really believe in our mission. Quite often, the people who work with the Google Summer of Code program continue to contribute with us as volunteers or sometimes even become employees.”
It’s a mutual win and an awesome program that has helped a lot of students find connections with companies, added Cheng. The program is a way for young people to show their initiative and is advertised as a way to “flip bits not burgers” in the summer.
“It’s a chance to contribute to a larger organization and maybe set themselves on a different prospective path to their future,” Cheng said.
Mek, who leads the OpenLibrary team at the Internet Archive, said the four GSoC students he’s worked with have made substantial improvements through their projects.
“We were able to make progress in a variety of different areas that we may not otherwise have had the bandwidth to focus on,” said Mek.
Being involved in GSoC has dramatically increased the number of volunteers who are interested in participating within the Open Library ecosystem. It prompted the Internet Archive to streamline the volunteer page and create an intake form. There has also been an effort to organize and label projects for new volunteers.
The GSoC experience led the Internet Archive to structure its own internship and fellowship opportunities. And it has provided the organization with a means to find qualified staff.
 Anish Kumar Sarangi, Google Summer of Code contributor.
Anish Kumar Sarangi, Google Summer of Code contributor.
Anish Kumar Sarangi, a student GSoC contributor in 2018, joined the Internet Archive as an employee in May 2020. During his summer experience, Sarangi worked on development of the Chrome extension, “Wayback Machine.” Today it is used by thousands of people to help them archive URLs, access archived content from broken links and perform other functions to help make the web more useful and reliable.
“I gained a lot of knowledge and experience. Everyone was very encouraging and supportive,” said Sarangi, of the summer program. He now works from India in software development for the Internet Archive and has been a mentor with the program himself. His advice to others considering applying: “Please get involved in the community. You can get guidance and grow further in the organization.”
The post Google Summer of Code is a Win-Win for Contributing Students and Mentoring Organizations: Thank you Google appeared first on Internet Archive Blogs.
Library as Laboratory Recap: Supporting Computational Use of Web Collections

For scholars, especially those in the humanities, the library is their laboratory. Published works and manuscripts are their materials of science. Today, to do meaningful research, that also means having access to modern datasets that facilitate data mining and machine learning.
On March 2, the Internet Archive launched a new series of webinars highlighting its efforts to support data-intensive scholarship and digital humanities projects. The first session focused on the methods and techniques available for analyzing web archives at scale.
Watch the session recording now:
“If we can have collections of cultural materials that are useful in ways that are easy to use — still respectful of rights holders — then we can start to get a bigger idea of what’s going on in the media ecosystem,” said Internet Archive Founder Brewster Kahle.
Just what can be done with billions of archived web pages? The possibilities are endless.
Jefferson Bailey, Internet Archive’s Director of Web Archiving & Data Services, and Helge Holzmann, Web Data Engineer, shared some of the technical issues libraries should consider and tools available to make large amounts of digital content available to the public.
The Internet Archive gathers information from the web through different methods including global and domain crawling, data partnerships and curation services. It preserves different types of content (text, code, audio-visual) in a variety of formats.
 Learn more about the Library as Laboratory series & register for upcoming sessions.
Learn more about the Library as Laboratory series & register for upcoming sessions.
Social scientists, data analysts, historians and literary scholars make requests for data from the web archive for computational use in their research. Institutions use its service to build small and large collections for a range of purposes. Sometimes the projects can be complex and it can be a challenge to wrangle the volume of data, said Bailey.
The Internet Archive has worked on a project reviewing changes to the content of 800,000 corporate home pages since 1996. It has also done data mining for a language analysis that did custom extractions for Icelandic, Norwegian and Irish translation.
Transforming data into useful information requires data engineering. As librarians consider how to respond to inquiries for data, they should look at their tech resources, workflow and capacity. While more complicated to produce, the potential has expanded given the size, scale and longitudinal analysis that can be done.
“We are getting more and more computational use data requests each year,” Bailey said. “If librarians, archivists, cultural heritage custodians haven’t gotten these requests yet, they will be getting them soon.”
Up next in the Library as Laboratory series:
The next webinar in the series will be held March 16, and will highlight five innovative web archiving research projects from the Archives Unleashed Cohort Program. Register now.
The post Library as Laboratory Recap: Supporting Computational Use of Web Collections appeared first on Internet Archive Blogs.
What’s New in February 2022
Here are some of the notable new additions to the Internet Archive from February 2022. (Logging in might be required to borrow certain items.)
Notable new collections:We’ve been reorganizing some of the items uploaded by our users, and these collections of magazines struck us as particularly interesting:
- The Planetary Report: 216 issues of a scientific magazine all about planets.
- Film and Cinema Magazines: Magazines dealing with film, movies, cinema and related subjects, including film making.
- Hobby Magazines: Magazines dedicated to hobbies.
This month we’ve added books in more than 20 languages. Here are a few good ones to start with:
 Crescent City Girls
Crescent City Girls
 Hard road to the top
Hard road to the top
 Namibia : a thirstland wilderness
Namibia : a thirstland wilderness
 The hidden places of Ireland
The hidden places of Ireland
 Herbal teas for lifelong health
Audio Archive 73,305
Herbal teas for lifelong health
Audio Archive 73,305
The audio archive contains recordings ranging from alternative news programming, to Grateful Dead concerts, to Old Time Radio shows, to book and poetry readings, to original music uploaded by our users.
The LibriVox Free Audiobook Collection 118Founded in 2005, Librivox is a community of volunteers from all over the world who record audio versions of public domain texts: poetry, short stories, whole books, even dramatic works, in many different languages.
 A Guide Book of Art, Architecture, and Historic Interests in Pennsylvania
A Guide Book of Art, Architecture, and Historic Interests in Pennsylvania
 A Year with the Birds
A Year with the Birds
 Innocencia: a story of the prairie regions of Brazil
78 RPMs and Cylinder Recordings 8,840
Innocencia: a story of the prairie regions of Brazil
78 RPMs and Cylinder Recordings 8,840
Listen to this collection of 78rpm records, cylinder recordings, and other recordings from the early 20th century.
 Sweet Bird
Sweet Bird
 Van Beinum, LPh.O. – Beethoven (Decca X.311) 1949
Van Beinum, LPh.O. – Beethoven (Decca X.311) 1949
 You Made Me Care
Live Music Archive 892
You Made Me Care
Live Music Archive 892
The Live Music Archive is a community committed to providing the highest quality live concerts in a lossless, downloadable format, along with the convenience of on-demand streaming.
 Billy Strings Live at Bell Auditorium on 2022-02-16
Billy Strings Live at Bell Auditorium on 2022-02-16
 Everyone Orchestra Live at Brooklyn Bowl on 2022-02-25
Everyone Orchestra Live at Brooklyn Bowl on 2022-02-25

Goose Live at Mohegan Sun Arena on 2022-02-26 Netlabels 263
The Netlabels collection hosts complete, freely downloadable/streamable, often Creative Commons-licensed catalogs of virtual record labels.
 The Whirling Way
The Whirling Way
 DJ Saint-Hubert – Word Salad Homunculus [bump221]
DJ Saint-Hubert – Word Salad Homunculus [bump221]
 [A027] Udiv – 2022 – “Trivia”
Internet Arcade 5
[A027] Udiv – 2022 – “Trivia”
Internet Arcade 5
The Internet Arcade is a web-based library of arcade (coin-operated) video games from the 1970s through to the 1990s, emulated in JSMAME, part of the JSMESS software package. Containing hundreds of games ranging through many different genres and styles, the Arcade provides research, comparison, and entertainment in the realm of the Video Game Arcade.
 Tetris (Photon System)
Tetris (Photon System)
 Wheels Runner
Wheels Runner
The post What’s New in February 2022 appeared first on Internet Archive Blogs.
Independent Publisher Drives Innovation, Sells eBooks to Internet Archive
Publisher of 11:11 Press says it sells—rather than licenses—books to libraries for online lending to reach a broad audience.
The goal of 11:11 Press is to have its books in every library in the world, according to its founder and publisher, Andrew Wilt.
 Andrew Wilt, 11:11 Press
Andrew Wilt, 11:11 Press
“We are big supporters of libraries because they allow equal access to knowledge and preserve culture,” said Wilt, whose independent press based in Minneapolis sells its books at a discount to nonprofits. “From a publishing standpoint, our authors care about being read so we want to get our books to as many people as possible.”
The Internet Archive recently bought the entire catalog of books from 11:11 Press and made them available online for controlled digital lending to one person at a time.
“Honestly, I don’t know why anyone would not want to have their books in a library, especially the Internet Archive, which is more relevant now than it has been any other time,” Wilt said. “It used to be the library of the future. But in our era of remote learning and people working from home, the Internet Archive is the library of the present. You don’t have to go into an actual physical building. It’s available for anyone with an internet connection. It’s probably the most relevant lending institution at the moment.”
“[Internet Archive] used to be the library of the future. But in our era of remote learning and people working from home, the Internet Archive is the library of the present.”
Andrew Wilt, editor, 11:11 PressIn business for four years, 11:11 Press publishes an eclectic mix of titles that Wilt describes as “disruptive literature.” Its authors push the boundaries. Some books have a very heavy, theoretical and academic focus while others are about everyday working people. There are books of poetry, short stories, novels, and hybrid work. The aim is to give exposure to underrepresented voices and offer an alternative from what is produced by mainstream publishers.
“We’re kind of this lighthouse trying to find those people who are actively looking for something that’s new and exciting,” said Wilt.
From the 11:11 Press CatalogIn one of the 11:11 Press “theory fiction” titles, Zer000 Excess, images are “glitching out” within the text, leading the reader to consider what meaning is being created. Jake Reber wrote the book using Microsoft PowerPoint 2007 – the only version of the software with identifiable software features known to produce these “glitches.” Authors like Reber intentionally use these embedded software tools incorrectly in order to get distortion. “Like the early punk bands who put fuzz in their music, we’re trying to add that distortion in the work,” said Wilt.
Human Tetris merges digital dating in an all-too-honest newspaper style of queer dating profiles. It was written as a collaboration between two different voices building a lattice of interlocking online identities by Vi Khi Nao and Ali Raz.


The publisher features “dangerous writing,” which uses fiction as the buffer to draw on personal experience. For authors in this genre, fiction is the lie that tells the truth. “We want to encourage writers to go to those uncharted territories of the self. What you find might be hard to look at, but if you pull back the layers, there’s something unique and beautiful there.” Wilt said.
Jinnwoo (Ben Webb) is a writer, musician, visual artist, and author of the book Little Hollywood published by 11:11 Press. It consists of B-grade movie scripts with paper doll cut outs. The idea is to engage the reader by having them cut out the dolls and use the scripts. “Going to those dark places with honesty encourages the reader to be more mindful, more present, which leads to more empathy,” Wilt said.
Did you know? Thanks to the innovative partnership between the Internet Archive and Better World Books—our favorite online bookstore—patrons who browse to the 11:11 Press books at archive.org have a direct link to purchase new copies of the books in print via Better World Books.
“Small presses drive innovation.”In its next catalog, 11:11 Press will be coming out with a 520-page Illustrated Old Testament and corresponding painting. This 9-by-12-inch book, which will sell for $150, is too religious for some and too secular for others, making it a perfect product for a small press, Wilt said. Another upcoming book will be a compilation of short stories by the late Peter Christopher who helped start the dangerous writing movement.
As a small press, Wilt said the focus isn’t to write with marketing in mind but rather for authors to write the stories only they can tell. The hope is for 11:11 Press to create something greater to help benefit society and get people to think in a different way. “Reading authors who courageously face their lives, their past, their future, encourages us, the readers, to do the same,” he said.
Wilt said he anticipates other independent publishers will follow suit in selling their works to the Internet Archive. “Small presses drive innovation. This is where experimentation occurs,” he said. “Our top priority is sharing knowledge.”
The post Independent Publisher Drives Innovation, Sells eBooks to Internet Archive appeared first on Internet Archive Blogs.
A Long Bet Pays Off
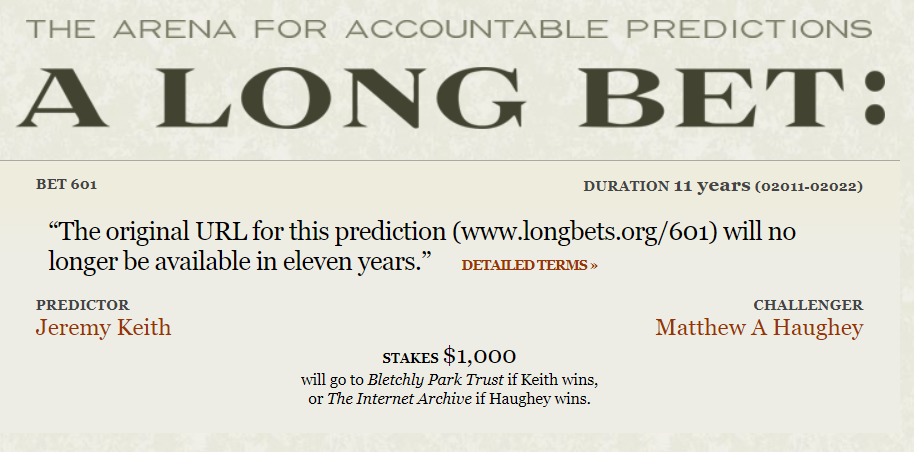
11 years ago, on the site longbets.org, a friendly wager was made between two mavens of the web: Jeremy Keith and Matthew Haughey.
The bet, to be revisited a decade and a year later, would be whether the URL of their wager at Long Bets would survive to a point in the semi-distant future.
That is, this day, February 22nd, 2022, (2/22/2222).
As of this writing, the URL absolutely has survived.
Therefore, the Internet Archive shall receive a $1,000 donation from Mr. Keith and Mr. Haughey ($500 apiece), provided from an escrow account that has held the funds since the day of the wager. (We shout out to the Bletchly Park Trust, a worthwhile historical organization, who will not be getting the donation but who are deserving of yours.)
It would be easy enough to declare it a win for the idea of “the web” and that regardless of concerns and topics brought up about the Internet’s issues and concerns, we can still find hope. So certainly, let us all applaud that things worked this way, and the URL’s 11-year consistency is a bright beam of light, online.
In many ways, however, the bet is at best a bittersweet victory, and at its darkest interpretation, a small oasis in a desert.

To understand The Long Bets, you need to understand The Long Now.
The Long Now Foundation is a non-profit meant to be an organization geared towards projects and approaches to thinking that chronologically leave the average human lifespan in the dust; focusing on 10,000-year timelines and solutions to problems of sustaining cultural contexts for a hundred lifetimes and beyond.
Currently, the Long Now and its ideals are expressed in both a very nice performance and drinking space called The Interval, and a number of stylish projects and websites to bring this realm of thinking into focus.
The most prominent and first major project was the Clock of the Long Now, a project to make a time-accurate clock that would function for 10,000 years. The as-yet incomplete project goal is to build a clock deep in a mountain range and set it off, ticking occasionally (but on time, doing so) for the next ten millennia.
Other projects follow this approach as well, ranging from delicious to provoking. A re-imagining of the Rosetta Stone, a language translation service, a manual for civilization, a mountain land purchase, and others in these themes.
Among these variant projects is Long Bets.
It is a facilitation of long-term thinking, of providing a neutral, fair and equitable way for years-in-the-future bets to be made between parties, each contributing funds towards the prize. It is traditional that the recipient of the prizes be organizations not run or controlled by either bettor.
Browsing the betting page, the bets range from the humorous to the aspirational, from specific sports outcomes to predictions around space travel, vehicle autonomy and economics. They’re a joyride of thought and conversation starters, as they’re meant to be.
And among them is Bet #601.
Jeremy Keith and Matt Haughey are both veterans of The Web as it has historically been described; each has had their voices heard to crowds online and off, describing the nature of websites. Their careers have (deservedly) benefitted greatly from the power of interlinked websites.
They both recall the start of the world wide web, as well as internalizing the rules and mores that followed its birth. They were well-qualified to debate on the longevity of URLs and the position that a specific URL would hold across time.
That said, Keith was skeptical. Haughey was optimistic.
Like a lot of its neighbors, Bet #601 is too clever by half; the bet states that it is won or lost depending on the availability of the bet at the URL the bet is hosted at. That is, either two situations exist to judge the outcome: Either the URL https://longbets.org/601 exists, at which point the bet is lost, or it does not exist, at which point the bet is won.
(Strikingly, if the bet had been won, the Internet Archive would possibly be the only place to browse the site in its original form, where it would have then helped prove the funds should go to Bletchly Park Trust. The continued reliance on the Wayback Machine as the vault of the Web’s lost memories would have persisted, in a very sharp and slightly less financially-beneficial way. Such is the price of memory.)
For the record, here are the statements made by each bettor about their arguments for the wager:
 Jeremy Keith
Jeremy Keith
Jeremy Keith:
“Cool URIs don’t change” wrote Tim Berners-Lee in 01999, but link rot is the entropy of the web. The probability of a web document surviving in its original location decreases greatly over time. I suspect that even a relatively short time period (eleven years) is too long for a resource to survive. I would love to be proven wrong.
 Matt Haughey
Matt Haughey
Matthew Haughey: Though much of the web is ephemeral in nature, now that we have surpassed the 20 year mark since the web was created and gone through several booms and busts, technology and strategies have matured to the point where keeping a site going with a stable URI system is within reach of anyone with moderate technological knowledge. My oldest sites are going on 13 years old at the time of this bet and the original URL scheme still functions via 301 redirects to a final format we selected about six years ago.
This should be it.
But it’s worth noting how the context of this bet has changed over time. And issues with the continued evolution of the web strike at heart of the point the bet was trying to make.
THE URL:
The Long Now Foundation, intending to maintain its footing for as long as absolutely possible, has a very vested interest in its URLs staying stable. Between hosting structure, the setup of the webpages themselves, and maintaining clean, static URLs (longbets.org/601 is a very simple address, lacking any ornamentation or dependence on programming language extensions or dynamic rendering). The domain name longbets.org is registered until June of 2022 as of this writing, but was registered in June of 2001, twenty years ago, which bodes well for continued survival.
If you’re going to bet that a URL is going to stick around, on a website run by an organization that expresses its character by the longevity of its projects, staking your bet on a specific URL from that organization is a pretty safe bet.
THE WEB:
Both of the parties in the bet clearly think of “the web” as being a set of interacting links between websites, but even by 2011, the idea of a “website” was beginning to experience direct collision with the ever-centralizing, ever-shifting audience of online life. Mobile access is a quirk in the 1990s, an oddity growing into a majority in the 2000s, and now, in the present day, phones with screens are the “home computer” of vast percentages of internet patrons.
In the interconnection of the world, it is harder and harder to think of a “website” where “platforms” rule the roost. A user is more likely to have an account name, or a public identity, than to ever utter the phrase “http” in their daily activity, or maybe even their year. The clear goal of many firms is to dissolve the consideration of the URI or URL, with many of the previous protocols of the earlier Web forgotten. The question becomes less of “will this URL survive” and more of “will the idea of the URL survive?”
THE IDEA OF LONGEVITY AND CHANGE FOR DIGITAL DATA:
Finally, the overarching fact of the situation is that sites like Long Bets are part of a philosophy of the web that is rapidly shrinking – that points of data and dependable signifiers of content and individuals are no longer the destinations, but stops along the way, flotsam and jetsam that ride in nebulous platforms that dominate online life.
As we move into this even-more-ethereal version of the Web, where objects, materials and locations possess data as much as pages and links we ever did, the Internet Archive will do its best to keep up and grow to match the challenge.
But what a challenge it shall be. Bet on it.
The post A Long Bet Pays Off appeared first on Internet Archive Blogs.
What does AI look like when archival concepts and principles inform its development?
In the past, archives have used Artificial Intelligence relying on off-the-shelf tools. This practice has both limited what challenges can be met and made the needs of archives subservient to the larger field of machine learning. It may be a practical thing to do, but many alarming instances of bias have been found in modern machine learning models as applied to archival material. This raises the questions of a) whether off the shelf tools are the best solution for the archival field, b) how archival concepts and principles might influence the development of AI tools intended for records and archives management, and c) how the two fields of AI and archival science can benefit from a partnership. The speakers will discuss the archival design, development, and leveraging of AI to support the ongoing availability and accessibility of trustworthy records. We will first explain the types of AI that are most likely to support archival endeavours, and then illustrate studies on the design of AI tools for the identification of ancient records, for the classification of current records, and for detection of privacy information, as well as presenting several other studies focused on using and developing AI to support archival appraisal, arrangement and description, preservation, and access.
This theme is discussed by Luciana Duranti (University of British Columbia (UBC)-Canada, archival science), Muhammad Abdul-Mageed (UBC-Canada, AI), Luigi Compagnoni (Archivio di Stato di Milano-Italy), Emanuele Frontoni (University of Macerata-Italy, AI), Umi Moktar (Universiti Kebangsaan Malaysia, archival science and AI), and Jim Suderman (I Trust AI Researcher, Canada, archival science). The session will be moderated by Luciana Duranti.
Pagina's







")

































































")

")






























")























")







")
")
")




")
")







]")







")
")



































")






")
")

")

















")








")






")

")






{kind=link}
{kind=link}
Raadpleegbaarheid is een samenstel van ontsluitingstechnische voorzieningen die tezamen bewerkstelligen, dat derden (vrijwel) zonder tussenkomst van de archiefvormer of -beheerder/-archivaris, ter beantwoording van een bepaalde vraag in elk geval de benodigde archiefbewaarplaatsen/-ruimten, archieven/bestanden en archiefbestandde(e)l(en) gericht kunnen traceren en opvragen.