U bent hier
Voortbestaan
Shockwave Audio
Ok, confession time.
There is only a couple moments in my tech history which had a profound effect on me, enough to sear the memory of the moment into my brain. When I was in college around 1997 I had a decent CD collection and I had learned how to copy those AIFF files off the disc and use them on my trusty PowerCenter Pro. These files were huge, at the time. I knew a regular size song would take up around 50MB on my hard drive. This was a lot of space back in 1997, but I could then mix them with other songs, something I did sometimes for friends I had on the dance team. I didn’t have a CD burner at the time so I would transfer them to cassette tape. I know, but remember this was the 1990’s when everything was changing and expensive.
One night I was exploring the world wide web and I happened across someone sharing a few songs. I assumed they were just clips as they were only 5MB in size, a tenth the size they should be. I downloaded the song, which of course still took a few minutes back in those days. When I played the song, I was dumbfounded, it was the whole song. I was completely confused. How could they take a 4+ minute song and compress it down to under 5MB? This was amazing.
I started grabbing every song I could find. Before long I had quite the collection. And before you judge me for downloading music from the web, this was a couple years before the advertisement we all remember reminding us that we wouldn’t steal a car so why would we steal music.
The files I found on the internet were MP3 files, the same we are familiar with today. Back then creating MP3 files wasn’t easy. MP3 was actually a licensed product so you had to get a little creative in order to make them. On my Macintosh PowerCenter Pro, there were even fewer options. I was already familiar with the sound editing application from Macromedia called SoundEdit 16, it was the tool I used to do all my editing. I found there was a plugin you could add which allowed export to a format called Shockwave Audio. This was meant for use in Macromedia’s Director application to add sound to the growing Flash animation industry. Once I got the plugin and installed I couldn’t stop making files and I made them as fast as I could. For a whole album this could take over an hour on my hardware, but it was worth it. Before long I had a large collection of popular music ready to play at a moments notice. My player of choice was MacAMP, a sibling of the popular WinAMP. I even borrowed some equipment from a friend who DJ’d on the weekends and DJ’d a college dance. I lugged my whole PowerCenter Pro tower and 17in trinitron monitor over to the school. It was so much fun and folks didn’t understand when they asked to see my CD collection.
Enough about transgressions from my youth, lets talk about the Shockwave Audio format.
To create a SWA file you would first need SoundEdit 16 Version 2. Then the plugins to enable export. This would only run on PowerPC computers running Macintosh OS or Classic in Mac OS X. For this post I pulled out my trusty PowerBook G4 Titanium running MacOS 9 and MacOS X 10.2. Installed SoundEdit 16 and the plugins in the Xtras folder and we are good to go.

Before you export you need to set what bitrate you prefer for the final file, giving you the option of 8KBits up to 160KBits per second. The higher the bitrate the longer it took and made larger files.
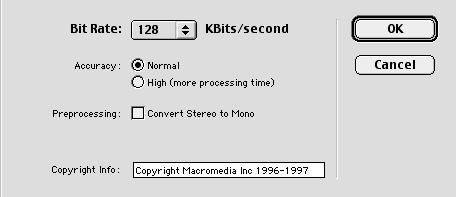
SoundEdit 16 had a native audio format and also frequently used the SoundDesigner II format to save the uncompressed files. On a Macintosh you had to be careful as these formats did not travel well to other systems on account of the resource forks associated with the data.

Because these SWA files were meant to be used in websites and other non-Mac systems, they did not have a resource fork, but had the Creator/Type codes, SwaT/SHCK. An extension wasn’t necessary for use on your Macintosh, but it was best to use .swa.
Here is what the data looks like for a SWA file.
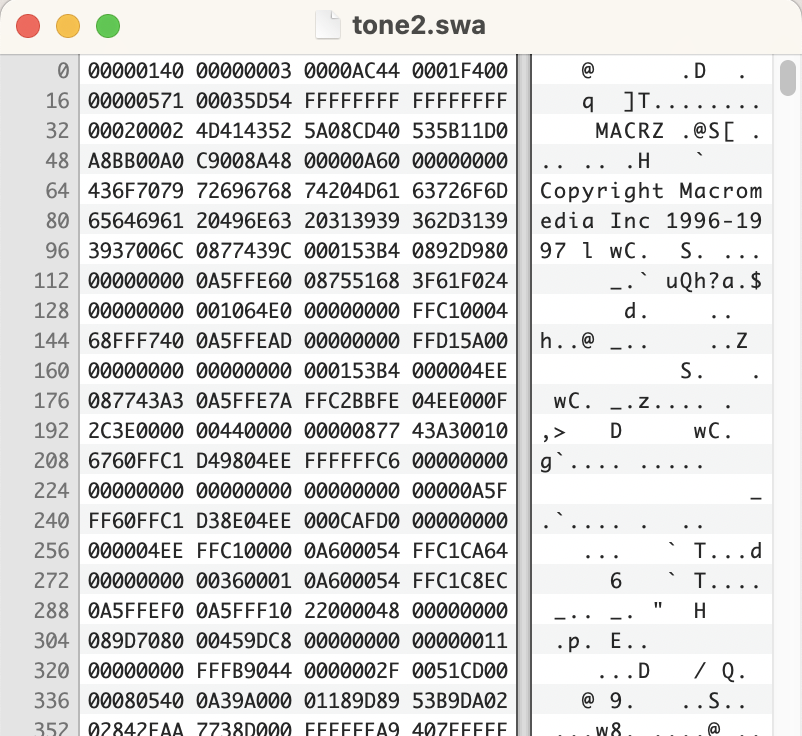
Even though the SWA format uses MPEG compression, this is not a typical header you might see in a MP3. There was no ID3 tags at the time so not much in terms of metadata.
General Complete name : tone2.swa Format : MPEG Audio File size : 80.7 KiB Duration : 5 s 166 ms Overall bit rate mode : Constant Overall bit rate : 128 kb/s FileExtension_Invalid : m1a mpa mpa1 mp1 m2a mpa2 mp2 mp3 Audio Format : MPEG Audio Format version : Version 1 Format profile : Layer 3 Format settings : Joint stereo / MS Stereo Duration : 5 s 172 ms Bit rate mode : Constant Bit rate : 128 kb/s Channel(s) : 2 channels Sampling rate : 44.1 kHz Frame rate : 38.281 FPS (1152 SPF) Compression mode : Lossy Stream size : 80.7 KiB (100%) ffprobe -i tone2.swa[mp3 @ 0x155704a60] Format mp3 detected only with low score of 25, misdetection possible!
[mp3 @ 0x155704a60] Skipping 324 bytes of junk at 0.
[mp3 @ 0x155704a60] Estimating duration from bitrate, this may be inaccurate
Input #0, mp3, from 'tone2.swa':
Duration: 00:00:05.15, start: 0.000000, bitrate: 128 kb/s
Stream #0:0: Audio: mp3, 44100 Hz, stereo, fltp, 128 kb/s

There are a few consistencies among all my files. They all begin with the hex values “00000140000000030000” for the first 10 bytes and all of them seem to have the string “MACRZ” at offset 36. I haven’t been able to find a open specification for this file format, so we will have to go with what we can find in the samples. According to ffprobe from above, there is 324 bytes of a header before the first MP3 frame starts.
MPEG signatures are difficult, there are no headers, just a sequence of frames. This is why there are often so many identification conflicts with the MP3 format. These SWA files indeed identify as MP3 files, but with a mismatch extension.
filename : 'tone2.swa' filesize : 82661 modified : 1970-01-01T00:00:00-07:00 errors : matches : - ns : 'pronom' id : 'fmt/134' format : 'MPEG 1/2 Audio Layer 3' version : mime : 'audio/mpeg' class : 'Audio' basis : 'byte match at 0, 4088 (signature 5/9)' warning : 'extension mismatch'If we wanted to distinguish an SWA from an MP3 we would need to create a new signature and give it priority over the MP3 signature. There is enough of a header this would be possible and easier, but since they are, in reality, just MP3 files does it matter? Trying to play a SWA on a modern computer is only possible if you change the extension to MP3.
If you want to take a look at some samples you can grab a couple I made on my GitHub page or check out some commercially made files for an awesome Star Trek Starship Creator game.
GEDCOM
One of the first PRONOM signatures I submitted was for a format I felt responsible for, considering where I worked. This is the GEDCOM format, which is an acronym for GEnealogical Data COMmunication. At the time I submitted the signature the format hadn’t been updated in years.
Very recently it has seen a renewed interest from those in the Genealogical community. In 2021 the format was renewed with a Version 7 specification with the purpose of simplifying and clarifying the format. In addition a new format was released to handle storing multimedia files in a container called GED-ZIP.
My first attempt at a signature was based on the specification generally, but with the new version released, I thought it might be good to revisit this format and see if we need to make any adjustments. There needs to be a new signature for the GED-ZIP format as well.
The original signature, fmt/851, created for PRONOM is:
302048454144{0-1024}47454443(0D0A|0D|0A)322056455253It has an offset of 0-3 to account for any Unicode BOM, but starts with “0 HEAD”; this is the required start to a GEDCOM file. The next bits can be a source of the software which created the GEDCOM, using the tag “SOUR” which can also include a version of the software and name and address of the developer. This can take a bit of space so we include 0-1024 bytes for this information. The next tag is the subrecord of HEAD, “GEDC”, then the next subrecord, “VERS”. Most GEDCOM validations will look for HEAD.GEDC.VERS for the version of GEDCOM the file claims to conform with. The hex values, (0D0A|0D|0A), is the hard return accounting for the different systems that could write the GEDCOM.
A minimal GEDCOM version 5.5 would contain the following.
0 HEAD 1 GEDC 2 VERS 5.5 0 TRLRThe end of the file is marked by the tag “TRLR” in reference to a Trailer. I didn’t include this in my initial signature, but probably should have.
GEDCOM files have been around a long time, the first draft was released in 1984, but the GEDCOM structure we see now really didn’t come along until version 3 in 1987, when the format was standardized and made public. The HEAD.GEDC.VERS wasn’t standardized until version 4. You can see the history here.
So moving forward we should probably have a new PUID for Version 3, Version 4, Version 5 and the new Version 7 and leave the existing signature as is.
Version 3 only requires the tags HEAD, SOUR, DEST and the ending TRLR.
BOF 302048454144(0D0A|0D|0A)3120534F5552{0-128}312044455354 EOF 302054524C52Version 4 requires the HEAD.GEDC.VERS sequence.
BOF 302048454144{0-1024}47454443(0D0A|0D|0A)3220564552532034 EOF 302054524C52Version 5 is similar.
BOF 302048454144{0-1024}47454443(0D0A|0D|0A)3220564552532035 EOF 302054524C52Version 7 is also similar.
BOF 302048454144{0-1024}47454443(0D0A|0D|0A)3220564552532037 EOF 302054524C52For the new GED-ZIP format we need to create a container signature as the format is a ZIP file but with a GEDCOM inside. The GED-ZIP specifications states:
A GEDCOM ZIP file should:
• include exactly one GEDCOM file with the name “gedcom.ged”
• include all the multimedia objects references by that GEDCOM file
• not include unreferenced multimedia objects
Our Container signature would look like this:
<ContainerSignature Id="1000" ContainerType="ZIP"> <Description>GEDZIP</Description> <Files> <File> <Path>gedcom.ged</Path> <BinarySignatures> <InternalSignatureCollection> <InternalSignature ID="300"> <ByteSequence Reference="BOFoffset"> <SubSequence Position="1" SubSeqMinOffset="0" SubSeqMaxOffset="3"> <Sequence>30 20 48 45 41 44</Sequence> </SubSequence> </ByteSequence> </InternalSignature> </InternalSignatureCollection> </BinarySignatures> </File> </Files> </ContainerSignature>I recently learned of a variation on the GEDCOM format which can cause a lot of confusion. The software Family Tree Maker could export to the GEDCOM format, but had a checkbox which, unchecked, allowed you to not abbreviate the tags. The tags in the GEDCOM format are expected just the way they are, which makes me wonder why they would do something so confusing. You can read more about this format here.

I was recently made aware a few of these rouge “GEDCOM” files were out there, in the wild, causing confusion during identification. My first thought was to adjust the signature to make it a little more loose to fit these variations, but then discovered they are not GEDCOM files. In fact later versions of FTM forgot they did this and would error when you tried to import them back into the software. I think it would be wise to identify these FTM GEDCOM variants, just so one is aware of the difference and can then decide how to handle them properly.
The format was named “FTW TEXT”, so we can use that to call the new signature. Instead of “0 HEAD”, “0 HEADER” is used, instead of “0 SOUR”, “0 SOURCE” is used, and instead of “0 TRLR” at the end, “0 TRAILER” is used.
BOF 3020484541444552(0D0A|0D|0A)3120534F55524345 EOF 3020545241494C4552It was fun to look back at this format and try and improve on it a bit. I learned more than I did when I initially wrote the signature and hopefully documented it well enough. The FTM variant was an interesting twist I was not expecting, which I am sure will show up again in the future. Take a look at the signatures and samples I updated and let me know what you think.
RIS Citation
Up until recently I was working in a Corporate archive preserving all sort of content. The corporation throughout the years used many different software packages to produce all sorts of data. When I moved to an academic library I saw much of the same content, but there was a some new file formats which I needed to document and manage. Many of those come from scholarly journals , theses, dissertation, and data sets for projects.
One format which I came across often but seems to be missing from the standard file format known lists was the RefMan citation format. This format is a simple text based format which serves to standardize citations from scholarly sources. Created by Research Information Systems, the format uses the RIS extension used by Procite and Reference Manager (RefMan). ISI ResearchSoft managed the format for a bit in the 1990’s, this is where you can find most of the specifications.
Now that I am a little more familiar with the format I see it everywhere! Find any scholarly journal and there will usually be a “cite” feature to download the citation in a few formats, RIS being one of the most common.
Example: Theory and Craft of Digital Preservation
It can be called by a few names, mostly based on the systems which support it. You might see Ris (Zotero), or EasyBib, Mendeley, ProCite, Reference Manager, and others. But they all follow the same format.
The format is simple plain text format, there are codes which indicate the different field types and tags. The basic structure would look like this:
TY - BOOK AU - Owens, Trevor LA - eng PB - Johns Hopkins University Press Baltimore, Maryland CY - Baltimore, Maryland SN - 9781421426976; 1421426978 PY - 2018 TI - The theory and craft of digital preservation LK - https://worldcat.org/title/1030899528 ER -The first tag always needed to be “TY” and the last tag “ER”. TY stands for Type of reference and ER stands End of reference.
There is actually two versions of the format, this original specification and a later one which added some header information. You can download the full documentation here.
Provider: The name of the information provider (required) Database: The name of the database (optional) Tagformat: Name of the tag format used identify fields (optional) Content: media type for the body of the file (required)Creation of a PRONOM signature for this text format is pretty straight forward. Looking for the TY and ER string should be enough to ensure the format doesn’t clash with other text based formats. Text formats are notoriously difficult to identify, but when they have expected patterns it makes it a little easier. I had to add a little buffer at the beginning of the signature to allow for the newer header information, but more samples will be needed to see if this is enough to identify the format in all situations. Take a look and see if it works for you!
MP4 & 360
Recently I have been exploring the MP4 format, more specifically the ISO Base Media File Format. It appears to be quite the versatile format. Based on the general Box/Atom format. Don’t mean to go much into the format here as there are so many formats which use this structure, like Quicktime MOV, Jpeg2000, to the more recent Canon RAW CR3. I have also been digging into the DASH MP4 format, but we’ll save that for a later time.
One of the more interesting uses of MP4 lately is 360 or spherical video. They are becoming more and more popular with content creators and also used for mapping like Google street view.
A while back I picked up a Insta360 Nano S camera. It attached directly to my iPhone. With a camera on each side it could capture images and video which could later be processed to produce some interesting results.

Of course it needs to be processed first so it doesn’t look like you are peering out of your peephole. Insta360 provides software for you to process the video into a regular video or some fun creative spherical video that makes you look like you are walking on a small globe.

The formats produced by the Insta360 Nano S are plain old JPG and MP4, but uses the extensions .INSP and .INSV respectively. Neither of which are documented in PRONOM yet. But because of the nature of 360 camera’s there is a little more under the hood. If you would like to look at some samples you can find some here.
The INSP file begins like any other EXIF JPEG file, but ends with a little additional info.

The 360 cameras have some additional information from the different gyros and accelerometers, as well as GPS information. The INSP file stores much of this information after the end of the JPG format. You can also see a string of alphanumeric numbers at the end, which is consistent with most of the files I have seen. One python parser of the additional data calls it the magic number. “8db42d694ccc418790edff439fe026bf” would make a good pattern for a signature.
The INSV files are similar, except they use the MP4 base media format.

Mediainfo indeed sees the file as an MPEG-4 with a AVC codec, but with a invalid extension.
Complete name : VID_20210222_170428_005.insv Format : MPEG-4 Format profile : JVT Codec ID : avc1 (avc1/isom) File size : 41.1 MiB Duration : 7 s 608 ms Overall bit rate mode : Variable Overall bit rate : 45.4 Mb/s Encoded date : UTC 2021-02-22 17:04:18 Tagged date : UTC 2021-02-22 17:04:18 IsTruncated : Yes FileExtension_Invalid : braw mov mp4 m4v m4a m4b m4p m4r 3ga 3gpa 3gpp 3gp 3gpp2 3g2 k3g jpm jpx mqv ismv isma ismt f4a f4b f4vIn addition to a video and audio track, there is a text track.
Text ID : 3 Format : Timed Text Codec ID : text Duration : 7 s 600 ms Bit rate mode : Constant Bit rate : 240 b/s Frame rate : 10.000 FPS Stream size : 228 Bytes (0%) Title : Ambarella EXT Language : English Forced : No Encoded date : UTC 2021-02-22 17:04:18 Tagged date : UTC 2021-02-22 17:04:18With a little Exiftool magic, thank you Phil, we can see some of the extra data within the video file.
Serial Number : ISS2418ND7XH4H Model : Insta360 Nano S Firmware : v1.17.12.3_build1 Parameters : 2 947.866 946.388 964.646 0.000 0.000 90.000 942.993 2891.656 952.520 -0.682 -1.501 89.186 3840 1920 1040 Preview Image : (Binary data 578944 bytes, use -b option to extract) Time Code : 62.155 Accelerometer : 0.0717358812689781 0.837667405605316 -0.541449248790741 Angular Velocity : -0.00380666344426572 -0.0143540045246482 0.0170918852090836Thanks to tools like Exiftool and MediaInfo we can take a peek into some of these formats. New ways of using the existing formats and new formats entirely keep popping up making it hard to know exactly what you have. Initially I just assumed the Insta360 formats didn’t need anything extra as they just used well known format with their own extension, but I needed to look a little closer. Many other cameras are now putting additional data at the end of a standard JPG. It will be interesting to see what new ideas camera developers come up in the coming years.
GoPro has a 360 camera as well and looking at a sample .360 file, I can see it also uses an MP4 base media format, but uses two video tracks to store video from the two cameras. Might need to dig into that format soon as well.
Beef & Babe’s
The 1990’s was a an exciting time for Desktop Publishing. I got my first taste of design in the early 90’s with Aldus PageMaker. QuarkXPress was king in commercial publishing world. For the most part designers and commercial printers used Macintosh computers which QuarkXpress catered to. For those who could not afford the high prices, or used a PC, there was a few options. Microsoft Publisher, TimeWorks Publish It!, and Express Publisher were a few. There was many debates during that time on which software was the best.
I have submitted signatures to PRONOM for many of these:
Express Publisher was proving elusive for finding software and sample files. Express Publisher was developed by Power Up who had been developing a DOS version since the late 1980’s. At one point Power Up decided to sue QuarkXPress for the use of the name XPress. In 1991 Power Up sold all their assets to Spinnaker around the time they released the first Windows version of Express Publisher.
When I first took a look at some samples from the Windows version 1.0 of Express Publisher, the magic header looked familiar.
Ok #retrocomputing folks, there must be a story behind the use of 0xCAFEBEEF in the header of these Express Publisher files from the early 90's. #fileformats #digipres pic.twitter.com/MMKafv5K4C
— Tyler Thorsted (@CHLThor) May 5, 2022If it looks familiar to you it is similar to the famous, well nerd famous, JAVA Class file format.

The story goes that James Gosling needed a magic number for his new class format and was in a place they called Cafe Dead when he realized CAFE was a hex value, he soon used CAFEBABE and CAFED00D for his new formats. JAVA was released by Gosling in 1995 for SUN Microsystems.
File Format magic numbers are often used when designing a file to be used with software. Often times it is meant to be a sequence of hex values or a string indicating the file supported by certain software, this is more accurate than the simple extension at the end of most files. They are not required to be there, in fact there are a few formats which are difficult to identify as they don’t use this type of magic number in the header. To learn more read Ross Spencer’s post on magic numbers for digital preservation.
CAFED00Ds and CAFEBABEsAt first I thought it was some sort of homage to the JAVA Class format until I realized the Express Publisher file format was released 3 years earlier. Just a coincidence? I am sure whomever developed this format probably has an interesting story behind it.
These formats are not in PRONOM so lets take a look at what is needed.

The document format for Express Publisher version 1 for Windows 3 uses the EWD extension, as well as EWT for templates. Magic numbers work best for a signature when they are at least 4 bytes long, this gives enough to have little chance of conflicting with another file format. So our PRONOM signature byte sequence would look like this:
<ByteSequence Reference="BOFoffset"> <SubSequence MinFragLength="0" Position="1" SubSeqMaxOffset="0" SubSeqMinOffset="0"> <Sequence>CAFEBEEF</Sequence> <DefaultShift>5</DefaultShift> <Shift Byte="CA">4</Shift> <Shift Byte="FE">3</Shift> <Shift Byte="BE">2</Shift> <Shift Byte="EF">1</Shift> </SubSequence> </ByteSequence>In looking at the earlier DOS versions of Express Publisher they used the extension EPD for a document and EPT for templates. I only have a few samples of version 2 and version 3, but they have different headers.

Version 2 & 3 has consistent bytes starting at offset 4, version 2 using the string PAGES, and version 3 the string EP300. I will have to dig a little more to see if I can find some samples of version 1 to see how they compare and then should be able to submit a PRONOM signature for them.
For the time being, adding “CAFEBEEF” to PRONOM will be a good addition. I wonder if there are any other “CAFE” formats out there, if you know of any, let me know!
UPDATE – There is another format, AnFX Movie, which uses the magic header “CAFEBEEF”. More research is needed to distinguish the two formats.
Hemera Photo-Object
Many years ago I dabbled in a little Graphic Design. Working for a commercial printer in the Pre-Press area, I was very familiar with all things graphics, but never had a great talent for design, especially drawing. I often needed the random clip art for a design I was working on, so I purchased the Hemera, The Big Box of Art, probably from my local CompUSA if that dates me.
 Hemera Big Box of Art
Hemera Big Box of Art
The cool thing about clip art from Hemera is it was not your usual JPG or TIFF format, it was in a special Photo-Object format. This format included the raster image, but also included a mask or alpha channel for the main object. They marketed this format as an alternative to the sometimes larger formats of the day. GIF files didn’t have the color depth and PNG was new enough, Hemera was probably hoping this format would be the next greatest thing to happen to clip art.

A Hemera Photo-Object has the extension HPI. Lets take a closer look at a file and see what is under the hood. I pulled this file from Disc 1 on Archive.org
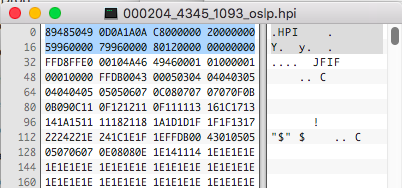
The HPI file has a unique header which should make identification really easy. But what do we see starting at offset 32? A JFIF! Just after a 32 byte header the file has a standard JPG file hidden inside. Now a standard JPG file does not have the ability to support an alpha channel so there must be something else they have within to mask this file. Lets look for the EOF file marker for the JPG format.
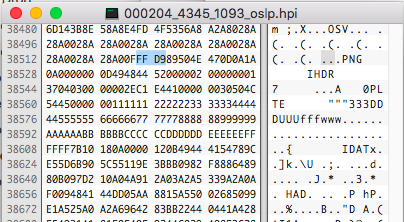
Well, well, well. It appears the JPG file is then followed by a standard PNG! Sneaky. The entire HPI file is a 32 byte HPI header, a JPG, followed by a PNG. One could easily carve out each of the formats and save as separate files if needed. There is a script you can use to do this for you, written by Ed Halley. The original Hemera software won’t run on modern systems.
Hemera had a good run for about 10 years before selling off their assets in 2004 to another stock image company. At one point Hemera even purchased the rights to all of Corel’s Premium photo library which I covered in my article about the Kodak PhotoCD format.
Image PAC Files
I wouldn’t be surprised if you have never heard of an Image PAC file. You may know it by the more common name Kodak Photo CD Image. Kodak’s PhotoCD format actually refers to the system and Disc format used to store images for compatibility with other hardware. The Kodak PhotoCD format was pretty advanced for its time, it original purpose was to store scanned 35mm film to a disc which was playable on computers and other hardware. In fact, because it was meant to store 35mm rolls as they were scanned it was the first use of the linked Multi-session CD format made standard by the orange book specification. The format was widely adopted at first, but eventually lost favor and was abandoned by 2004.
The Kodak PhotoCD format was also used on many commercial CD-ROM products. One example was the Corel Professional CD series. Below is a photo of a case of 200 CD’s I recently acquired. Each has around a hundred PCD images and viewing software on disc. Most discs can be viewed here. Or you can view their “Sampler” CD-ROM.

The actual PCD image file format was referred to as an Image PAC File. The format was unique in the fact it has multiple resolutions built into a single file. It also stored the raster data in a format called Photo YCC color encoding metric, developed by Kodak. This requires conversion to RGB for many uses. Adobe Photoshop for many years had an import filter for the format built in which included ICC profiles for properly converting the source to a destination colorspace, but support was dropped in CS3 of their products.
 Photoshop Kodak PCD import
Photoshop Kodak PCD import
The Image PAC PCD format was a proprietary format which Kodak protected aggressively, even to the point of threatening legal action to those who attempted to reverse engineer the format. This frustrated developers and was probably part of the reason the format was abandoned. Of course this didn’t deter some curious developers and was partially reversed engineered and is available in the NetPBM library formally knows as PBMPlus. The tool hpcdtoppm was developed to convert PCD to PBM.
The trick in preserving older obsolete formats is to find a way to first identify them, gather significant properties, then migrate to a modern format if appropriate with minimal loss of data. Luckily most PCD files have the ascii string “PCD_IPI” starting around offset 2048. This is basically how the PRONOM registry identifies the format and has assigned it fmt/211. Exiftool also supports the format in identifying some of the significant properties.
ExifTool Version Number : 12.62 File Name : 136009.PCD Directory : /Users/thorsted/Desktop/blog/Kodak/PCD File Size : 3.6 MB File Modification Date/Time : 2023:06:23 10:48:55-06:00 File Access Date/Time : 2023:06:26 23:43:50-06:00 File Inode Change Date/Time : 2023:06:27 11:18:38-06:00 File Permissions : -rwx------ File Type : PCD File Type Extension : pcd MIME Type : image/x-photo-cd Specification Version : 0.6 Authoring Software Release : 3.0 Image Magnification Descriptor : 1.0 Create Date : 1993:09:20 07:35:34-06:00 Image Medium : Color reversal Product Type : 116/01 SPD 0064 #00 Scanner Vendor ID : KODAK Scanner Product ID : FilmScanner 2000 Scanner Firmware Version : 2.21 Scanner Firmware Date : Scanner Serial Number : 0296 Scanner Pixel Size : 0b.30 micrometers Image Workstation Make : Eastman Kodak Character Set : 95 characters ISO 646 Photo Finisher Name : HADWEN GRAPHICS Scene Balance Algorithm Revision: 3.1 Scene Balance Algorithm Command : Neutral SBA On, Color SBA On Scene Balance Algorithm Film ID : Unknown (131) Copyright Status : Restrictions apply Copyright File Name : RIGHTS.USE Orientation : Horizontal (normal) Image Width : 3072 Image Height : 2048 Compression Class : Class 1 - 35mm film; Pictoral hard copy Image Size : 3072x2048 Megapixels : 6.3Exiftool is able to gather much of the important properties including an original creation date and the pixel dimensions. It would be nice if was able to mention each of the resolution options as some later Pro versions of PCD had a 64 base for resolutions of 4096 x 6144.
Migration to a more modern open format is a common preservation strategy. The National Archives and Records Administration has the format NF00224 listed as needing to migrate to JPG, while others prefer migration to TIFF. Others have learned valuable lessons attempting to find the right method for migration. There is a right way and a wrong way as the Center for Digital Archaeology learned. The easiest method is to use the popular ImageMagick command-line tool.
thorsted$ identify 136009.PCD 136009.PCD PCD 768x512 768x512+0+0 8-bit YCC 3.44727MiB 0.020u 0:00.006 thorsted$ convert 136009.PCD[5] -colorspace sRGB +compress 136009.tif thorsted$ identify 136009.tif 136009.tif TIFF 3072x2048 3072x2048+0+0 8-bit sRGB 18.0004MiB 0.000u 0:00.000ImageMagick along with most other tools like IrfranView and XnView only see the base resolution of 768 x 512, but with an extra little addition to the command by adding “[5]” after the filename if forces the conversion to use the “Fifth” 16 Base resolution which is the highest resolution on most PCD files, the Pro versions may have higher. The other issue is the colorspace conversion. It is known there could be a loss of highlights. This webpage illustrates different tools and the issues with highlights. You can see the difference if I use -colorspace RGB instead of sRGB.
 ImageMagick conversion using RGB vs sRGB colorspace setting.
ImageMagick conversion using RGB vs sRGB colorspace setting.
Other tools such as the open source pcdtojpeg and paid pcdMagic both work well, but the only tool I have tested so far which keeps the original metadata is pcdMagic.
ExifTool Version Number : 12.62 File Name : 136009_1.tif Directory : . File Size : 38 MB File Modification Date/Time : 2023:06:27 12:06:26-06:00 File Access Date/Time : 2023:06:27 12:06:29-06:00 File Inode Change Date/Time : 2023:06:27 12:06:27-06:00 File Permissions : -rw-r--r-- File Type : TIFF File Type Extension : tif MIME Type : image/tiff Exif Byte Order : Little-endian (Intel, II) Subfile Type : Full-resolution image Image Width : 3072 Image Height : 2048 Bits Per Sample : 16 16 16 Compression : Uncompressed Photometric Interpretation : RGB Image Description : color reversal: Unknown film. SBA settings neutral SBA on, color SBA on Make : KODAK Camera Model Name : FilmScanner 2000 Strip Offsets : 1622 Samples Per Pixel : 3 Rows Per Strip : 2048 Strip Byte Counts : 37748736 Planar Configuration : Chunky Software : pcdMagic V1.4.19 Modify Date : 2023:06:27 12:06:26 Copyright : Copyright restrictions apply - see copyright file on original CD-ROM for details Exif Version : 0231 Date/Time Original : 1993:09:20 07:35:34 Create Date : 1993:09:20 07:35:34 Offset Time : -06:00 User Comment : color reversal: Unknown film. SBA settings neutral SBA on, color SBA on Color Space : Uncalibrated File Source : Film Scanner Profile CMM Type : Unknown (KCMS) Profile Version : 2.1.0 Profile Class : Display Device Profile Color Space Data : RGB Profile Connection Space : XYZ Profile Date Time : 1998:12:01 18:58:21 Profile File Signature : acsp Primary Platform : Microsoft Corporation CMM Flags : Not Embedded, Independent Device Manufacturer : Kodak Device Model : ROMM Device Attributes : Reflective, Glossy, Positive, Color Rendering Intent : Perceptual Connection Space Illuminant : 0.9642 1 0.82487 Profile Creator : Kodak Profile ID : 0 Profile Copyright : Copyright (c) Eastman Kodak Company, 1999, all rights reserved. Profile Description : ProPhoto RGB Media White Point : 0.9642 1 0.82489 Red Tone Reproduction Curve : (Binary data 14 bytes, use -b option to extract) Green Tone Reproduction Curve : (Binary data 14 bytes, use -b option to extract) Blue Tone Reproduction Curve : (Binary data 14 bytes, use -b option to extract) Red Matrix Column : 0.79767 0.28804 0 Green Matrix Column : 0.13519 0.71188 0 Blue Matrix Column : 0.03134 9e-05 0.82491 Device Mfg Desc : KODAK Device Model Desc : Reference Output Medium Metric(ROMM) Make And Model : (Binary data 40 bytes, use -b option to extract) Image Size : 3072x2048 Megapixels : 6.3 Modify Date : 2023:06:27 12:06:26-06:00There is a way to convert the PCD to TIF using ImageMagick, then using Exiftool to map some of the metadata over to the new TIFF file. It would look something like this:
exiftool -addtagsfromfile 136009.PCD '-EXIF:DateTimeOriginal<PhotoCD:CreateDate' '-EXIF:CreateDate<PhotoCD:CreateDate' '-ExifIFD:SerialNumber<PhotoCD:ScannerSerialNumber' '-ExifIFD:ExifImageWidth<PhotoCD:ImageWidth' '-ExifIFD:ExifImageHeight<PhotoCD:ImageHeight' '-IFD0:Make<PhotoCD:ScannerVendorID' '-IFD0:Model<PhotoCD:ScannerProductID' '-IFD0:Orientation<PhotoCD:Orientation' '-IFD0:Copyright<PhotoCD:CopyrightStatus' 136009.tifJPG Structure
If you hadn’t been over to see the posters made by Ange Albertini, head over now. Below is his poster on the JPG image file format. This is the basic JFIF file format, which stands for JPEG File Interchange Format. There are also raw JPEG streams and Exif, Exchangeable Image File Format.
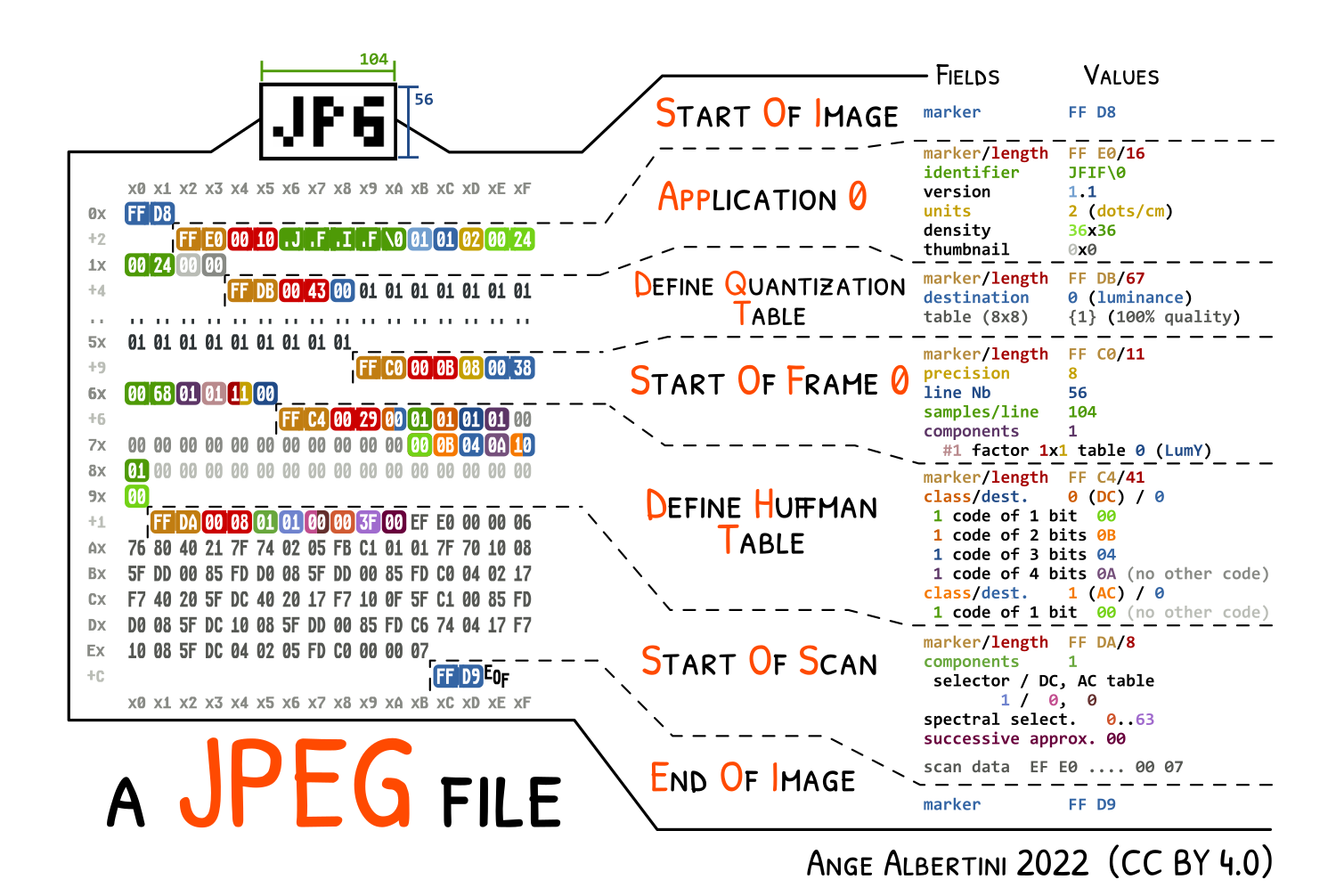
The basic format is pretty straight forward. There is a start of image marker FFD8 some format information, then the raster compressed data, then an end of image marker FFD9. Identification of a JPEG file should be pretty straight forward. Knowing the start and end marker values and then the type of JPEG based on the Application data, can be very specific. That is until some software engineers start playing fast and loose with the format specifications.
A while back I received a JPG file which didn’t identify using the latest PRONOM signature. It’s happened before, some new phones came out and started using a newer version of the exif specification so I submitted an update to PRONOM for JPG’s using exif 2.3 and greater. But also may need to submit another signature soon for the newly released Exif 3.0 specification! But this JPG I received wasn’t a new version, it should have been identified with the current PRONOM signature. It started with FFD8 and when I went to look at the end of the file for the end of image marker FFD9, it wasn’t where I expected it to be.

This JPG file had an additional 9632 bytes after the FFD9 end of image marker. But why? The image rendered just fine in multiple JPG viewers. The only warning from Exiftool was for “Unrecognized MakerNotes”, which is not too uncommon. So I went to the JPG Exif specification.
EOI, Recording this marker is mandatory. It shall be recorded in this position.But reading a little further we see…..
Moreover, Exif/DCF readers should be implemented to operate without interruption even if certain kinds of data have been recorded after EOI of the primary image defined in the Exif standard. Specifically, unknown data after EOI of the primary image should be skipped. (see section 4.7.1)
So the extra data is allowed by specification. Any readers should ignore or skip any data after the EOI (End of Image). Well that makes identification more difficult. All the PRONOM signatures are based on having the EOI marker at the “End”. Some have allowance for padding, but not enough for the worst offenders……
The image referenced above was created on a Huawei MHA-L29 cameraphone. But since finding this image, I have also found many Samsung phones do the same thing. Here is one from a Samsung SM-G975U1. Much less padding but enough to throw off identification.
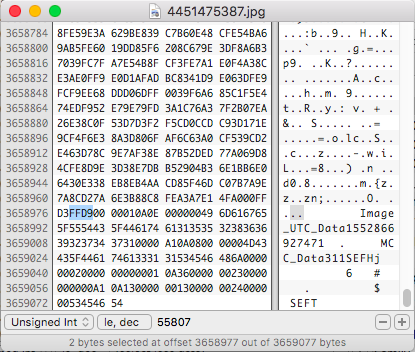
Apple iPhones are also not exempt from this “feature” either. When using the MacOS ImageCapture tool with the HEIC format, a bug can add an excessive amount of empty data at the end of the converted JPG file.
So, when it comes to identification, if your JPG files don’t seem to identify correctly, look closer at the end of the file, it may have some “extra” data.
What’s the 411?
I am dating myself by using the phrase “What’s the 411?” Back in my day (before the Googles), if you wanted quick information you could pick up the “land line”, a corded phone in your home which could only make phone calls, and dial 4-1-1 and you would be connected to an operator that could help you locate businesses, tell you the time, answer simple questions, and was infinity smarter than Alexa.

Around the same time I was using 4-1-1 to answer all my questions, digital camera’s were just coming on the scene. One of those was the Sony Mavica line of digital camera’s. They were unique as they used a floppy disk as the storage media. They had a small LED screen for capture and playback of the captured images. In order to quickly preview the images captured on disk, the camera generates a hidden thumbnail file for each image, this file has the extension .411. When I first saw this file when I copied a floppy from my Mavica cameras, it reminded me of the old information line. I first assumed it was a metadata file as the first few Mavica camera did not use EXIF in their files, but they are simply a raster image in a 64×48 pixel file. Of course Sony did not document this file format and probably hoped no one would noticed as they are hidden on the floppy FAT12 formatted disk.
@Foone picked up a Sony MVC-FD73 today. Tried capturing an image in bitmap. Disk full after 1 shot. #floppy #obsolete pic.twitter.com/Qr3WoHe4pV
— Tyler Thorsted (@CHLThor) April 14, 2018 Video showing index of floppy disk.One could argue the value of documenting and possibly identifying thumbnail formats as many in digital preservation have chosen not to keep the Thumbs.db file or other hidden files not meant to be preserved or accessible to the user. I have found documenting any format found through technical appraisals provides value to everyone, which may ultimately determine not to keep such formats in their repository, but knowing what they are is vital to the process. Come listen and chat with me about this topic at iPres 2023!
Usually the first part of documenting a format is looking for specifications online or documented somewhere. Since Sony did not publicly release any specifications for this format, we have to use others reverse engineering or do so ourselves. There have been a few attempts to document a conversion of the 411 format to a common raster format like BMP. Like this C code for conversion to BMP, or to NetPBM formats like PPM, or the Java “Javica” software which makes use of the 411 files. My first step was to see if we could find some common patterns in the many samples I have from my Mavica collection. Running Marco Pontello’s TrIDScan, across my 54 samples came up with no common patterns, this was expected as all the reverse engineering efforts points out the format is probably based on the CCIR.601 specification which is MPEG based on frames.
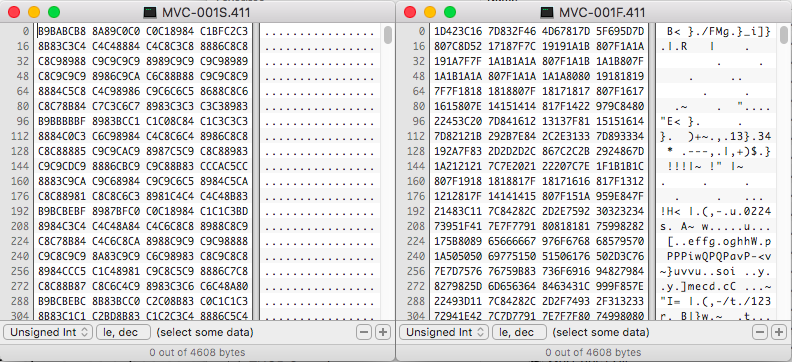
With no common patterns among all the samples, creating a PRONOM signature is not possible. In the future, file identification may be based more on dynamic pattern matching instead of the current static patterns we look for now. Until then, this may need to be submitted as an extension only entry. Two things to note, the files created by the camera are all named starting with “MVC” which could also be used for identification. You may also notice that every .411 file is exactly 4608 bytes. The extension .411 is also pretty unique, so I doubt it will clash with any other format for the moment.
Corel ArtShow
File extensions are the easiest way to quickly identify a file format, but they can be misleading. This is the reason in Digital Preservation format identification tools like DROID are important to look closer at the file structure to more accurately identify formats. The other complication is some extensions are used for more than one format. Extensions like .DOC or .ISO can be used with many formats.
The PRONOM registry which DROID uses will list extensions associated with each format signature, but for some, they only have an extension and no signature. It’s nice to have an official ID to go with a format but with no signature it only matches based on extension.
This caused a problem awhile back for me while working with some files with the extension CDX. Which according to PRONOM, there are 5 completely different formats which use the extension, and probably others.

My CDX was related to some indexing software called Cindex. At the time the only format with a signature was for the WARC summary file CDX. The other was for a CorelDraw Compressed format with no signature. Confusing right? When I would run format identification on my Cindex files, they would default to the CorelDraw Compressed format, identified by extension. It was easy enough to create a signature for the Cindex format as I had enough samples to know the patterns needed for correct identification. But I was curious about the CorelDraw format. Should be easy to find, right?
Wrong. Finding a sample of this format was very elusive. All I had to go by was the name given to the format by PRONOM and the extension. I scoured every Corel CD and image I could get my hands on. For months I looked and could never find a single CDX file. Each CorelDraw software I was able to run did not have any ability to save in the CDX format. I scoured clipart discs, other Corel software, like Designer, PrintHouse, Photo-Paint, nada, nothing. I started to wonder if the format even existed. That’s when I noticed in the filters included with CorelDraw a reference to the ability to import a CDX but not write to one.
[CDX] Signature=CORELFILTER - A FilterEntry=1 Description=CorelDRAW Compressed (CDX) FilterFullName=CorelDRAW Import Filter Version=Version 6.00 Company=Corel Corporation Copyright=Copyright © 1988-1995 Corel Corporation Extensions=*.CDX CorelID=0x704 FilterCapability1=0x9000 FilterCapability2=0x0 NoOfCompressions=0This led to me finding a reference on the old Corel FTP site for knowledge base number 4550.
It mentioned something called ArtShow, where version 5 supported the file format CDX. ArtShow was a gallery of winning designs released on a CD-ROM and book each year. The first one being ArtShow 91, then ArtShow 3, 4, 5, 6, and finally 7 was the last. Each one released used a different proprietary compressed format for storing all the designs, these formats exist nowhere else. The question remains, why didn’t they use other popular Corel formats like CDR, CMX, or CCX which were used on many other clip art titles.
It took some time but I was finally able to find copies of a few of the Artshow CD-ROM discs, especially numbers 5 & 6. Which had the CDX format and the second generation CPX formats.

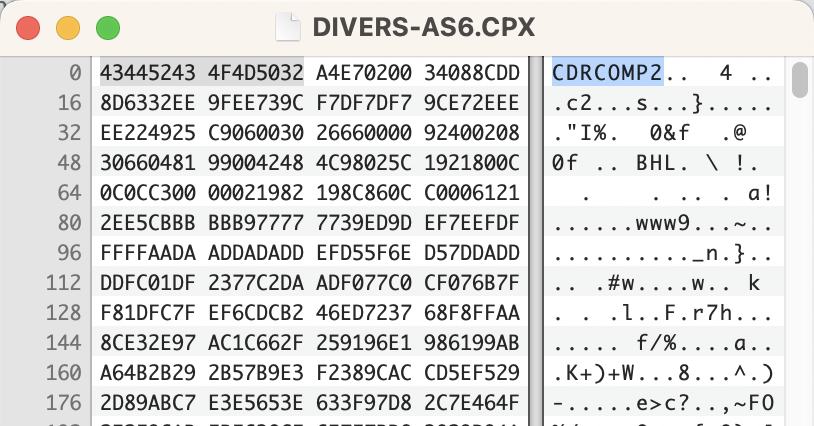
Each format had a easy to recognize header making a PRONOM signature easy to create. PRONOM already had the PUID for the two formats CDX & CPX, so sending in the signature added to the registry and hopefully will help distinguish between all the CDX formats!
Universal Scene Description
A few years ago I became obsessed with creating 3D models from physical objects. There was an app on my iPhone called 123D Catch by AutoDesk and it allowed you to take a series of photos with your iPhone camera, then combine them to create a 3D Model. This lead me down a path to eventually take a course on Photogrammetry and develop a process for capturing objects in our Museum.
Autodesk eventually discontinued the app and built the technology into their paid products. This is when we started seeing lidar introduced with handheld devices. The first one I tried was using my XBOX360 kinect sensor with the skanect software. The quality was horrible, but was fun to learn about depth sensors and structure from motion. When the iPhone finally came out with lidar sensor it was like Apple had read my mind. I love having the ability to capture objects I find into 3D models. The quality is pretty good, not as good as taking the time to capture image sets for photogrammetry and use tools like Aigisoft metashape, but apps like Scaniverse do a fantastic job. You can check out some of the models I have captured on my Sketchfab page.
Sony Mavica FD5 by tthorsted on Sketchfab
With any new technology comes new file formats, and 3D formats are definitely no exception. It seems every software developer has to come up with their own proprietary format leaving the digital preservation folks scrambling to keep up. The DPC and Archivematica published a report a couple years ago and state:
“There are many challenges in preserving 3D data. As well as the complexity of the data itself, there is
a lack of interoperability between the different (often proprietary) systems that are used to create
and manipulate 3D models. Relationships to other data, software and hardware also need to be
captured and managed effectively.”
With my new iPhone in hand I found myself with new file format I was unfamiliar with. Universal Scene Description is a framework to exchanging 3D data between different software developed by Pixar. The relationship between Apple and Pixar goes way back so it was no surprise the Apple iPhone has support built in for this new format and I found myself capturing and sending 3D models to others with an iPhone. The USDZ format is a ZIP package format for containing a USD 3D model and is perfect for sharing and preserving.
There is no current PRONOM signatures for identifying USD formats, so I wanted to look into creating one. This is where I ran into a problem. The current PRONOM signature syntax has no way of properly identifying the USDZ format. Let me explain.
When DROID or Siegfried is used to identify a container format such as USDZ. It will first identify the format as a ZIP file, which technically it is. This triggers the software to then refer to the container signature to see if any patterns from the files internal to the ZIP match to a known format. This is done by pointing to a specific file and a hex pattern or ascii string within the file. In the case of a USDZ the internal structure may look like this:
Listing archive: scaniverse-20210928-113055.usdz -- Path = scaniverse-20210928-113055.usdz Type = zip Physical Size = 5702256 Date Time Attr Size Compressed Name ------------------- ----- ------------ ------------ ------------------------ 2021-09-28 11:47:36 ..... 297999 297999 scaniverse-20210928-113055.usdc 2021-09-28 11:47:36 ..... 5403849 5403849 0/texgen_0.jpg ------------------- ----- ------------ ------------ ------------------------ 2021-09-28 11:47:36 5701848 5701848 2 filesIn this sample file the name of the USDZ is the same name as the internal USDC file. So the name of the USDC is variable and DROID needs a static name and path to look for patterns. The USDZ specification is clear that the only required file inside a USDZ is a USD model, anything else is ancillary and is not always going to be included. Currently the only format used is USDC, but in the future may allow a simple USD or USDA format. In addition, some of the other sample files show a very nested USDC file, making identification even more difficult.
Listing archive: Scan.usdz -- Path = Scan.usdz Type = zip Physical Size = 19155195 Characteristics = Minor_Extra_ERROR Date Time Attr Size Compressed Name ------------------- ----- ------------ ------------ ------------------------ 2021-03-09 09:22:36 ..... 19154773 19154773 /private/var/mobile/Containers/Data/Application/EFD09E66-32FB-4B08-8BED-B7E3D78FE1A8/tmp/Scan.usdc ------------------- ----- ------------ ------------ ------------------------ 2021-03-09 09:22:36 19154773 19154773 1 filesThe USDZ format is not the only file format which makes identification difficult through variable names and non-static patterns. An issue on GitHub has been raised to address this problem. One potential fix is to use glob patterns as suggested by the amazing Richard Lehane, creator of Siegfried. This way we could use wildcard to ignore the variable names and find any file with an extension of .USDC for example. The USDC file format has a nice 8 byte header “PXR-USDC” which is perfectly suited for identification so our container signature might look like this:
<ContainerSignature Id="1000" ContainerType="ZIP"> <Description>USDZ 3D Package</Description> <Files> <File> <Path>*.usdc</Path> <BinarySignatures> <InternalSignatureCollection> <InternalSignature ID="300"> <ByteSequence Reference="BOFoffset"> <SubSequence Position="1" SubSeqMinOffset="0" SubSeqMaxOffset="0"> <Sequence>50 58 52 2D 55 53 44 43</Sequence> </SubSequence> </ByteSequence> </InternalSignature> </InternalSignatureCollection> </BinarySignatures> </File> </Files> </ContainerSignature>Update: I was able to get a beta version of Siegfried working with my test signature.
siegfried : 1.11.0 scandate : 2023-06-02T08:54:27-06:00 signature : default.sig created : 2023-06-02T08:52:33-06:00 identifiers : - name : 'pronom' details : 'DROID_SignatureFile_V112.xml; container-signature-20230510.xml; extensions: usdz-signature-file-v1.xml; container extensions: usdz-dev1-signaturefile-20230601.xml' --- filename : 'scaniverse-20210928-113055.usdz' filesize : 5702256 modified : 2021-09-28T11:47:37-06:00 errors : matches : - ns : 'pronom' id : 'BYUdev/1' format : 'USDZ 3D Package' version : mime : 'model/vnd.usdz+zip' class : basis : 'extension match usdz; container name scaniverse-20210928-113055.usdc with byte match at 0, 8 (signature 1/2)' warning :I am still in the process of testing some beta versions of Siegfried in hopes of getting the glob matching to work, but still have more to do. Stay tuned!
EAP Digital Lecture Series
3M Printscape
There are some file formats out there which are confusing. One such file came across my desk awhile back. This file was not identifiable with any tools I threw at it. At first I believed it to be a TIFF file variant.

You can see the TIFF header, but would not open as one, even if the extension was changed from PSC to TIF. The other hint was the phrase “3M Printscape”, I had never heard of it and there wasn’t much information available about it. It seems it was a creative product made by 3M in the early 2000’s. You could buy a package of printable cards, gift bags, etc. The problem was, there was no available software to be found. I searched on the Internet Archive, the Wayback Machine, and many other abandoned software sites. For months I searched, it wasn’t until a year later I came across one of the creative packages at thrift store. I was thrilled. That is until I was able to get the software installed.

After I installed the software in a virtual machine running Windows 98 I tried to open the PSC file but the software was looking for files with the extension STD, which is an unfortunate acronym. Turns out it stands for SureThing Document. SureThing is a software company who develops Label software. After many months of searching I thought I had found the software to render my file, but it was not meant to be.

Many months later I decided to do some more searches. That is when another copy of 3M Printscape showed up in the Internet Archive. 3M Printscape 2.0! It appears 3M decided to design their own software for version 2.0.

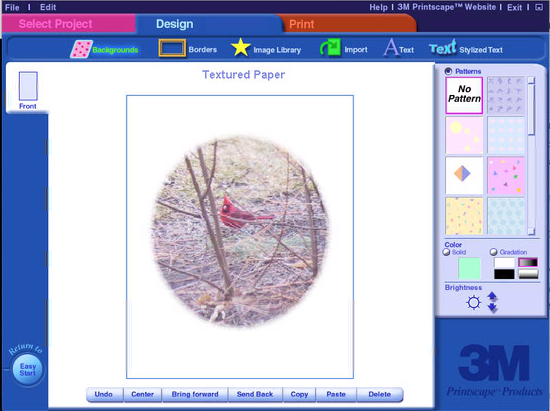
The preservation value of the above image is not lost on me. What took me over a year to figure out ended up being a simple pixelated image of a cardinal. Its the journey, not the destination?
From this little adventure I was able to submit two file formats to PRONOM, fmt/1275, fmt/1276. Also I documented the formats and linked to the software on the File Format Wiki. The 3M Printscape version 2 was also released for Macintosh, so the signature had to account for endianness, just like a TIFF file would. With the format having the string “3M Printscape” in the header, it made for an easy signature.
Hopefully, I will be the last to spend this much time on an image of a bird.
Greenstreet
During the 1980’s and 90’s, there was an explosion of software created for the PC and Macintosh. When it came to graphic design, Aldus, Adobe, Quark, Serif, and a few others were clearly the best. That didn’t stop other software developers in trying their hand with publishing design software. If you were on a budget, there were plenty of options to choose from. One of them, Timeworks Publisher, was very popular. It was released in 1987 for IBM PC and Atari with later releases for Apple II and Macintosh. The name was later changed to Pressworks. It was published by an interesting software company out of the UK called GST Software, also under the GSP name. They really enjoyed licensing their software.
Desktop Publishing software
TimeWorks Publisher may have been the first, but was definitely not the last. Pressworks was very popular so the software was sold and rebranded to many companies. In 2001 GST merged with eGames Europe as a new company, Greenstreet Software who continued to support the software. Some of which are:
- FUJI Publisher
- Global Software Publishing (in Europe) Pressworks, Power Publisher
- GST Pressworks
- 1st Press
- IMSI TurboPublisher
- Media Graphics Publishers Paradise Page Express
- MicroVision Vision Publisher 4
- NEBS PageMagic
- PersonalSoft Publications (Français)
- Pushbutton Publish
- Softkey Publisher DOS
- Sybex Page (Deutsch)
- Timeworks Publisher, Publish-it, Publisher Lite, Publish-it Lite
- VCI Pro Publisher
- Wizardworks CompuWorks Publisher
- Instant Home Publisher
- Greenstreet Publisher
- Canon Publishing Suite

All the of the software listed above could open and save to the same file format with the extension .DTP with full compatibility, also used TPL for templates. Originally the DTP file format was a single proprietary binary format which had an ascii header of “DTPI” and all seemed to end with the ascii “EODF”. Later the software was enhanced to be OLE compatible and the binary format was wrapped inside. This made it work well for moving objects in and out of the software into other OLE compatible software like Word, but is confusing to format identification software as the header is the same as a Word file. I have added the two versions of the DTP format to PRONOM to help identify them better. They are fmt/1415 and fmt/1416.
Drawing Software
In addition to the popular Desktop Publishing software, there was a companion Drawing software licensed as well. It also had many titles:
- BHV COLOURDRAW!
- FUJI Designer
- Global Software Publishing (in Europe) Designworks, Power Publisher
- GST (in North America) PressworksDraw
- 1st Design
- IMSI TurboDraw
- Media Graphics Publishers Paradise Design Studio
- MicroVision Vision Draw
- NEBS DesignMagic
- PersonalSoft Création Graphique
- Pushbutton Design
- VCI Pro Design
- Wizardworks CompuWorks Designer, CompuWorks Draw
- Canon Publishing Suite
The Draw/Design software all used the same file format as well with the extension .ART, also with full compatibility between all the titles. The TEM extension was used for templates. Not to be confused with the AOL Image format, or Asymetrix Compel Image format, or a number of other formats using the ART extension. This format also began as a single proprietary binary format with the ascii header “GST:ART” starting at offset 16. And just like the DTP format it was later wrapped in an OLE container to be more compatible. In fact, the DTP format may have embedded Art objects! This format is not in PRONOM, so lets take a closer look.

You can see from the 1stdgn.art file here, the ascii “GST:ART” string starting at byte 16. This is consistent with all the samples I have. The first 16 bytes seem to vary in each sample and probably have to do with the size of the file and dimensions of the artwork. GST:ART is unique enough and should work well for a signature.

The ART file from a later version of Draw is in the OLE file format. This container format was designed by Microsoft as a universal container to increase compatibility among software. You can see from the hex view above the file looks very similar to the DOC format used by Word. There were many software titles which used this container format, many documented here. One of the easiest ways to look inside an OLE container is to use 7-Zip. A quick listing of the file shows it is a Type = compound and includes three files. The SummaryInformation file is common among many OLE formats and can contain some metadata, but the Contents file is what we are looking for. Examining the Contents file we find it looks identical to the earlier version of the ART format. The same “GST:ART” string starting at byte 16.
A note about the Preview.dib file. It appears to be a Device-Independent Bitmap, similar to a Bitmap file, probably for a thumbnail preview.
Writing a signature for an OLE container format is a bit more tricky. It requires a separate signature file to go along with the regular signature xml. Basically DROID is setup to “trigger” once it discovers either a “ZIP” file or “OLE” format. If it detects one of those formats it then looks into the container signature xml for additional patterns. If it finds a match then it identifies the format, if not it reports back a generic “ZIP” or “OLE” format.
As it turns out there were two different types of OLE file types, one used “Contents” for the internal file and another which used “CONTENTS”. Since the signature is case sensitive, the container signature requires two signatures both mapped to the same PUID.

These two formats were used with quite a few software titles. Hopefully these signatures cover most of them! You can find a couple samples and my signatures on my Github.
Downgrading this blog
As of July 2, 2023, this blog will no longer be available as madfileformatscience.garymcgath.com. It will continue to exist as fileformats.wordpress.com. I’m making very little use of the blog lately, and while I want the old posts to stay around, it’s not worth continuing to spend money to maintain it. Nothing should disappear, but links may break. I may still make the occasional post.
LiveCode stack
One of the earliest hypermedia systems which predated the world wide web was called HyperCard on the Macintosh. Within minutes you could have a small application to do just about anything, calendar, address book, interactive books, games, etc. The internet archive has collected many HyperCard stacks and emulates them directly in the browser.

Riding on the success of HyperCard was another hypermedia tool called MetaCard, which later became Runtime Revolution. Today it is known as LiveCode, a cross-platform application development system. LiveCode is often used to quickly create applications which can run on many platforms including iOS. It is popular with students and higher education. The LiveCode source was opened for a time instigated by a successful kickstarter program, but closed in 2021 as the company struggled to keep paying customers.
Each LiveCode version produced unique files for each of the major versions. Currently none of the formats can be identified using preservation tools. Luckily, because the code was open-source for a time, we have details which helps us identify the formats. Let’s take a look:
#define kMCStackFileMetaCardVersionString "#!/bin/sh\n# MetaCard 2.4 stack\n #define kMCStackFileVersionString_2_7 "REVO2700" #define kMCStackFileVersionString_5_5 "REVO5500" #define kMCStackFileVersionString_7_0 "REVO7000" #define kMCStackFileVersionString_8_0 "REVO8000" #define kMCStackFileVersionString_8_1 "REVO8100"I took LiveCode up on their 10 day trial and was able to install software version 9.6.9 to save some samples. The software has a “Save as” option which allows you to save your code to older versions. Although one must be careful as saving to older versions may have some data loss.

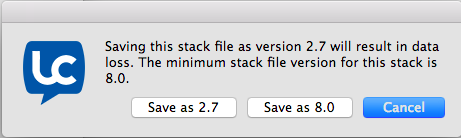
The samples I was able to save had matching headers just like in the source code. The REVO string starts right at the beginning of the file making identification easy. Take a look at my GitHub page for samples and signature. Also check out the File Format Wiki Page for more information and more samples!
Sounds of the shellac!
Open Media Framework
Awhile back I was asked to look at a file in our repository which had the extension OMF. It was not identified by DROID and didn’t appear to be in PRONOM. It didn’t take long to find quite a bit of information on the file format as it was used by many important software titles, or at least it used to. Exploring the details of this file format led me on quite the rabbit hole. You see, the OMFI format is based on a container format that once was heralded as the a better open choice over the Microsoft OLE container format growing in popularity.
OpenDoc
This all started with a multi-platform approach to an open document format started by Apple Computers in the early 1990’s called OpenDoc. It was originally an alliance between Apple, IBM, and Motorola. The idea was to have a framework any developer could use to develop software or components that would all work seamlessly together. Many developers were on board initially with many promised software titles being developed, but ultimately with much confusion surrounding the framework and Steve Jobs return to Apple in 1997, the project was scrapped.
Bento
The storage format to be used with OpenDoc was called Bento, in reference to the Japanese style of a compartmentalized container tray. Specifications were released in 1993.
There are four key ideas in the Bento format:
- everything in the container is an object,
- objects have persistent IDs,
- all the metadata lives in the TOC (Table of Contents),
- objects consist entirely of values, and
- each value knows its own property, type, and data location.
The idea of a data model with such an organized structure was so appealing the digital preservation community there was excited to push for a Universal Preservation Format specifically for multimedia based on Bento. The idea was presented to AMIA in 1996!
Open Media Framework (OMF) Interchange
Avid Technology, a leader in audio/video editing systems, used the Bento specification to design a container format for multimedia. This allowed easy interchange of projects between many different software titles. Original specifications were published in 1994, while the 2.1 specifications released in 1997. Software titles such as Pro Tools, Cubase, Adobe Audition, Adobe Premiere, Apple Logic Pro, Apple Final Cut Pro, and many others supported the OMF format, at least for awhile. OMFI was migrated to Microsoft’s Structured Storage container format to form the core of (AAF) Advanced Authoring Format in the late 1990’s.
Identification
In order to identify an OMF file we first need to understand what is part of the OMF specifications and what is part of the Bento format. OpenDoc may not have lived very long but the Bento format held on long enough to be the structure used by a few different file formats. I am aware of the following, but there was other software being developed at the time.
Samples from each of these formats show some similar patterns. In the Bento specifications we can see:

The only version of the specifications I can find are version 1.0d5 released in 1993, but we know there was also a version 2 released later. The magic bytes are not defined in the 1.0d5 spec, but looking at the code in the Open Doc Developer Release in 1996, we can find reference to the magic bytes used in “Containr.h”.
#define MagicByteSequence "\xA4""CM""\xA5""Hdr""\xD7"The Bento specification also defines this header information as, “Our solution to this is to define the standard Bento format to have the label at the end of the container.” Which means this byte sequence will frequently be found at the End of File. The “CM” refers to “Container Manager” and “Hdr” refers to “Header”.
Now that we have the magic bytes for the Bento container we can look at what makes the OMF file unique from others. We can find the answer in the Bento specifications.
We know that every Bento container must have a object, so in version 1.0 of the specifications on page 65 we find.
Each object must have the property OMFI:ObjID. The value of OMFI:ObjID is required and is listed in the property description for each object.
The OMFI:ObjID can also be found in version 2.0 of the specification, but in addition it defines:
The OMFI:ObjID property has been renamed the OMFI:OOBJ:ObjClass property, which eliminates the concept of generic properties and makes the class model easier to understand. The name ObjClass is more descriptive because the property identifies the class of the object rather than containing an
ID number for the object.
Since both are required it seems appropriate to use those strings for identification in a PRONOM signature. You can check out the proposed signature and samples on my GitHub page.
There is so much history wrapped up in these formats and the potential they had to change how we preserve files in our archives. Luckily we have the Internet Archive WayBack machine to help us discover or remember ideas that once existed, some which may find their way back to inspire future file formats.
Email migration
Recently I migrated my email to a new host and discovered a hazard I hadn’t known about before. I didn’t lose anything, but I came closer to it than I would have liked. Since it’s a personal digital preservation issue, it merits a rare post on this blog.
There are two widely used open protocols for email clients: POP3 and IMAP. The latter is far more widely used today, because it lets you synchronize your mailboxes across multiple devices. The downside is that your mail lives on the server and may or may not be saved on your client. If you change your mailbox to a new server, all your existing mail could disappear. As long as you haven’t terminated the old service, you should be able to get it back, but it could be a pain.
If you’re migrating, back up all your mailboxes before starting the move. Back up your mail to local storage periodically so that your IMAP server won’t lose everything to a glitch or unexpected loss of the account.
POP3 is safer in this respect. Your mail lives on your client machine. The downside is that unless you set your options to never delete mail from the server (or delete it only after a long time), your other devices may not have all your mail.
Sony Voice Recorder

Ugh I recorded all this audio as .dvf files and now I have a Mac and it's 10 years later and I can't open those audio files, waaaahhhh.
— Taz (@TazzyStar) February 8, 2018Sony’s IC Recorders have been a popular small digital voice recorder for many consumers. The current models all use common recording formats like Linear PCM WAVE files or MP3, but it wasn’t always so. One of the first models ICD-R100 would record to the ICS audio format, which was Sony’s original sound formats used on the IC Recorders. I am still looking for samples of this format. If you do have a need to convert this format, Sony has free converter software.
The next generation of IC Recorders used a Memory Stick and therefore recorded audio to the MSV (Memory Stick Voice) format. There were actually two different types of MSV files, the first used the ADPCM codec and the next used the LPEC codec. Later IC Recorders would record to the DVF (Digital Voice Format) which also had a couple versions, one using the LPEC codec and the other the older TRC codec.
AFAIK, none of the codecs used in these file formats has been made public and these formats are not readable by tools such as MediaInfo. The only way to know details of a file and have the ability to play or convert is to use Sony software which has been discontinued and the replacement, Sound Organizer, can only recognize the LPEC codec versions of MSV and DVF. There is also a plugin for Windows Media Player available here, which is required even for Switch to work.
PRONOM currently has one signature for the LPEC versions of MSV and DVF, so lets look closer at the formats and see if we can determine what they are from the header.
The CODECs
ADPCM is an abbreviation for “Adaptive differential pulse-code modulation“. Appears to only have been used with the ICD-MS1 and possibly MS2 digital recorders.
TRC may be an abbreviation of Truespeech’s “Triple Rate CODER” or “Triple Rate Codec“, but not much info exists.
LPEC is a proprietary compression format. It is an abbreviation of “Long-term Predicated Excitation Coding“. It even had its own trademarked logo which was cancelled in 2015.
The Software
The first IC Recorders came with PCLINK software, then came with the “MemoryStick Voice Editor” software. List of compatible formats.
Digital Voice Editor came next. It could read and convert everything except “ICS” files. Click here to download the last version. Version 1 compatible formats. Version 2 compatible formats. Version 3 Compatible Formats. The software was officially retired in 2016.
The current software for managing audio files from IC Recorder is Sound Organizer. The software does open and convert some MSV/DVF files as long as they use the LPEC codec. Sound Organizer Compatible formats.
Also note, Sony made one ICD-CX series recorder which could also capture photos. It requires the Visual & Voice Player software. Audio is recorded in the DVF format.
Test Data Set
In order to explore the different formats I first needed to gather some samples. There are a few out there, but with the Digital Voice Editor 3 software, I was able to take a sample file and convert it to the many options available. You can see in the screenshot below, the different samples, their extension and the codec used. You can find my samples in GitHub here.

All MSV and DVF file have a similar pattern. The first 32 bytes have the text string “MS_VOICE SONY CORPORATION”. In between MS_VOICE and SONY, there is 4 bytes which vary slightly between the different formats. Here is a table of samples and the 4 bytes so we can see the differences.
ModelCODECEXTENSIONHex ValuesICD-Px0TRCDVF01020000ICD-Px8TRCDVF01020000ICD-Px7TRCDVF01020000ICD-SXxx0LPECMSV01030000ICD-SXx8LPECMSV01030000ICD-SXx7LPECMSV01030000ICD-SXx6LPECDVF01020000ICD-SXx5LPECDVF01020000ICD-SXx0LPECDVF01020000ICD-MXLPECMSV01020000ICD-BMLPECMSV01020000ICD-STLPECDVF01020000ICD-MS5xxLPECMSV01010000ICD-SLPECMSV01010000ICD-BPx50LPECDVF01010000ICD-BP100/x20LPECDVF01010000ICD-MS1/MS2ADPCMMSV01000000ICD-R100/R200UnknownICSThere is an obvious pattern to the hex values as they increment 0100, 0101, 0102, and 0103. But there is some overlap between extension and codec, so probably more of a version number than specific to the codec. Currently the PRONOM signature for this format fmt/472, has the pattern for the 0102 version, but none of the others. We could simply add a variable in the signature for the different values and update the PRONOM signature so more samples would be identified. This would work well if there was a secondary characterization process to get technical metadata such as the codec and quality, but I am unaware of any tool to gather this information from the format, so I wonder if we can find any hints in the file to identify the codec so we have multiple PRONOM signatures to choose from. Also, you can see from the screenshot above that some of the LPEC formats have specific model numbers in the codec column, which could mean they may not be exactly the same. Each IC Recorder model has different quality settings and it appears, some settings may not be compatible with other models.
Looking beyond the first 16 bytes there is a lot of hex values which are unknown. A close comparison of all the samples leads me to the 4 bytes at offset 60. They seem to be the same for files with the same settings. Below is a chart of those values.
ExtensionCODECQualityOffset 60DVFTRCHQ00300001DVFTRCSP00350001DVFTRCLP00370001DVFLPEC (ICD-BP-100/x20)SP00150001DVFLPEC (ICD-BP-100/x20)LP00190001DVFLPECSP002A0001DVFLPECLP002C0001MSVLPEC (ICD-BM/MX/SXx7/SXx8/SXxx0)SP004A0001MSVLPEC (ICD-BM/MX/SXx7/SXx8/SXxx0)LP004C0001MSV/DVFLPEC (ICD-SXx7/SXx8/SXxx0)STHQ00200002MSV/DVFLPEC (ICD-SXx7/SXx8/SXxx0)ST00240002MSVADPCMSP00050001MSVADPCMLP00090001Just to be sure this value at offset 60 was indeed an indication of codec and quality I manually switch out the 4 bytes from a LPEC ST file for a TRC HQ file. Sure enough, the software now saw the file as a TRC HQ audio file, even though the original is a Stereo file.


There is a very good chance this is not all the options. I only have one physical recorder which only records in Mono. But this gives us a really good idea of how to tell the difference between files. Below are the patterns I am submitting to PRONOM.
MSV ADPCM
4D535F564F494345{4}01000000534F4E5920434F52504F524154494F4E{28}00(05|09)0001
DVF TRC
4D535F564F494345{4}01020000534F4E5920434F52504F524154494F4E{28}00(30|35|37)0001
MSV/DVF LPEC
4D535F564F494345{4}01(01|02|03)0000534F4E5920434F52504F524154494F4E{28}00(15|19|20|24|2A|2C|4A|4C)00(01|02)
Perhaps we can alter the existing PRONOM signature for fmt/472 to catch all we may miss to:
4D535F564F494345{8}534F4E5920434F52504F524154494F4E6D73766C637374772E73706900000000
This is one example of a file format which has a proprietary component which was never released from the vendor. When the vendor stopped supporting the software to open and read these formats, the risk increased for long-term preservation. It would be really nice when a vendor discontinues a technology, which was used by consumers, they would make the documentation for the format openly available. If you know more about the format, please reach out or if you have samples which don’t match the patterns mentioned here.
Pagina's







")

































































")

")






























")























")







")
")
")




")
")







]")







")
")



































")






")
")

")

















")








")






")

")






Unable to be inspected because the user does not have access to the entity.