U bent hier
Le blog de Marie Anne Chabin
Quand les victimes écrivent l’histoire
« L’Histoire ne s’écrira plus par les universitaires, les chercheurs du CNRS, les diplomates ou les hommes politiques. Elle s’écrira par les victimes du terrorisme, les victimes de ces actes que les Anglo-saxons appellent political violence, des actes de violence à caractère politique ». C’est par ces mots que Joël Bescond présente le livre qu’il a consacré à son frère Jean-Paul, médecin humanitaire, victime d’un attentat au Soudan à la veille de Noël 1989. Des mots qu’il a prononcés en septembre 2019 lors de l’hommage aux victimes organisé par l’Association française des Victimes du Terrorisme (AfVT).
J’ai lu le livre, Malim, une histoire française, publié il y a quelques mois. Je l’ai lu d’abord parce que j’ai connu Jean-Paul dans mon enfance et que je connais sa famille, mais aussi parce que cette affirmation résonne à mes oreilles et alimente ma réflexion sur l’histoire et les archives.
 À l’automne 1989, Jean-Paul Bescond, médecin de 33 ans qui s’est porté volontaire pour une mission auprès de MSF, arrive au Soudan, avant d’être envoyé à Aweil, une petite ville du Sud-Soudan (aujourd’hui Soudan du Sud). La région est alors en proie à une guérilla entre les rebelles du Sud (le SPLA) et l’armée du général El Béchir qui a pris le pouvoir quelques mois plus tôt (juin 1989). Le travail des humanitaires est extrêmement difficile. Le 21 décembre, l’avion blanc de MSF, très reconnaissable, est pris pour cible quelques secondes après le décollage et explose en vol avec quatre personnes à bord dont Jean-Paul. Le tir vient manifestement de très près et la ville est sous contrôle de l’armée régulière. C’est la première fois (mais pas la dernière) que des humanitaires sont délibérément pris pour cible.
À l’automne 1989, Jean-Paul Bescond, médecin de 33 ans qui s’est porté volontaire pour une mission auprès de MSF, arrive au Soudan, avant d’être envoyé à Aweil, une petite ville du Sud-Soudan (aujourd’hui Soudan du Sud). La région est alors en proie à une guérilla entre les rebelles du Sud (le SPLA) et l’armée du général El Béchir qui a pris le pouvoir quelques mois plus tôt (juin 1989). Le travail des humanitaires est extrêmement difficile. Le 21 décembre, l’avion blanc de MSF, très reconnaissable, est pris pour cible quelques secondes après le décollage et explose en vol avec quatre personnes à bord dont Jean-Paul. Le tir vient manifestement de très près et la ville est sous contrôle de l’armée régulière. C’est la première fois (mais pas la dernière) que des humanitaires sont délibérément pris pour cible.
La famille de Jean-Paul Bescond ne se résout pas à accepter cette déflagration dans l’univers familial comme une fatalité et entreprend des démarches pour comprendre, pour demander justice. La demande de rendez-vous avec le président de la République (François Mitterrand) ne débouche pas ; la cellule Afrique de l’Élysée dissuade la famille de porter plainte ; les démarches auprès de plusieurs interlocuteurs obtiennent toujours la même réponse : « on ne peut rien faire ».
Joël, le jeune frère de Jean-Paul, ne se satisfait pas de cette impasse et entreprend une longue enquête. François Mitterrand n’a-t-il pas écrit dans Le Coup d’État permanent (1964) que « Tant que le peuple n’aura pas recouvré le droit de dire lui-même où se trouve les frontières de la liberté d’expression, justice et démocratie resteront des mots vides de sens » ? Une plainte sera finalement déposée en 2009, vingt ans après les faits, l’année de la création de l’Association française des Victimes du Terrorisme (AfVT).
Le livre Malim, une histoire française restitue, précisément, minutieusement, cette longue quête d’informations et de sens.
Ce livre n’est pas un livre d’histoire écrit à partir des archives. Il est lui-même une archive, dans l’acception nouvelle de ce mot depuis quelques décennies, une trace de ce qui a été dit et tu, de ce qui a été fait ou non, de ce qui a été ressenti.
Joël Bescond rend compte, point par point, des vingt cinq années qu’il a consacrées à la compréhension de l’événement, faisant état de ses interrogations et de ses actions, de ses lectures, de ses rencontres, des demandes formulées et des réponses reçues (souvent des non-réponses), des réflexions et des éclairages qui permettent enfin d’articuler le tout pour ne plus porter seul la responsabilité du « on ne peut rien faire ». En parallèle de l’édition de l’ouvrage, l’auteur a mis en ligne un bon nombre de documents collectés ou constitués lors de l’enquête et que tout un chacun peut consulter.
Et les archives traditionnelles ? Bien sûr, l’histoire de l’attentat contre l’avion de MSF à Aweil pourra un jour faire appel aux archives publiques issues de l’activité des États, de l’administration, de la Justice, des organisations publiques relatives à la politique africaine de la France dans la région (les événements du Soudan sont indissociables de la politique française au Tchad et en Libye), à la diplomatie, au droit international, à l’action humanitaire, aux échanges avec la famille de Jean-Paul, sans parler des archives privées des hommes politiques, des avocats, des responsables associatifs, etc. Mais ces archives-là ont-elles été constituées (correspondance, accords, notes internes, documentation, simple mention dans un rapport…) ? Si oui, ont-elles été conservées (le temps d’une mandature, dix ans, à titre d’archives historiques avec un « versement d’archives » en bonne et due forme) ? Si oui, avec quel délai de communicabilité et quel inventaire sont-elles accessibles ? Quand on sait que la majorité des archives conservées n’a jamais été consultée et ne le sera jamais, on peut s’interroger sur l’espoir d’y voir clair un jour par ce biais-là.
Une petite phrase prononcée par un des avocats consultés dans cette affaire est particulièrement éclairante : « Il y a un double obstacle [à votre démarche] : le temps et l’affaire d’État »… Sans le recours aux archives qui, si elles sont préservées, restent confidentielles pendant des décennies, le citoyen qui cherche à comprendre un événement d’ordre international et national autant que privé, peut au moins compter sur lui-même. Les réponses que lui a faites l’administration lui appartiennent et il est libre d’en faire état. Il serait curieux un jour de comparer ce qui subsiste dans les archives publiques de ces nombreux entretiens que l’auteur de Malim a fidèlement retranscrits dans son volumineux ouvrage.
Il faut également avoir en tête deux évolutions majeures de la société pendant cette période de vingt cinq années après l’attentat. La première est l’arrivée d’Internet, de la messagerie électronique, des sites web ; en 1989, il n’y avait que le courrier postal et le téléphone. La seconde, liée à la première, est la libération de la parole d’une manière générale, la possibilité pour un individu de s’exprimer directement au moyen du réseau mondial (du moins dans les pays démocratiques).
De ce point de vue aussi, Malim, une histoire française, est une archive originale et symbolique de l’histoire des victimes. Écrite par les victimes, sinon peut-être jamais.
L’article Quand les victimes écrivent l’histoire est apparu en premier sur Le blog de Marie-Anne Chabin.
Les clics sont cancérogènes, alertent deux chercheurs
Il semblerait que l’abus de clics nuise à la santé et, pire, que les clics soient, dans certaines conditions cancérogènes. C’est ce que viennent de démontrer les deux chercheurs Mado EKAF [1] et Sacha SWEN [2] de l’université de SAINT-FROMEDION à ALCAURN.
L’étude menée par les chercheurs consistait en l’approfondissement du lien de causalité entre l’addiction aux écrans et l’apparition chez certains individus de lésions cérébrales. Les pratiques d’un panel d’internautes recrutés sur les réseaux sociaux (sans leur consentement, le district d’Alcaurn étant exonéré de l’application du RGPD) ont été soigneusement observées pendant plusieurs mois : nombre de clics, heure du premier et dernier clic, activités menées en parallèle du cliquage, etc.
Plusieurs indicateurs (Klics Problem Indicators ou KPI) ont été établis : ratio nombre de clics/jour de la semaine, trajectoire de l’œil d’un clic à l’autre (plusieurs modèles de référence ont été élaborés), pourcentage de re-clics, forme des nuages des mots-clés (étiquettes) ou hashtags des pages visitées (là aussi plusieurs modèles ont été dessinés grâce à une IA dédiée : boule, traîne, étoile, ruche…). Bien évidemment, les chercheurs ont procédé à des études complémentaires pour tenir compte des bons clics et des mauvais clics (good clicks, bad clicks) afin d’apporter les corrections nécessaires aux résultats bruts.
Ce travail a mis en évidence que les clics, quand on en abuse, provoque une atrophie de la criticoïde, ou glande de Tucapt, cette glande très fragile qui se situe à l’avant du cerveau [3]. Cette maladie, dont les effets sont hélas tragiques, a été dénommée « cancer de la criticoïde».
Trois stades sont identifiés à ce jour dans le développement de la maladie.
Le premier stade, dénommé « stade frénétique », est une première étape de la dégradation de la criticoïde par altération de ses fonctions naturelles d’analyse des données transmises par l’œil ; les impulsions dues aux clics à répétition usent la criticoïde dont la taille se réduit chaque jour un peu plus ; ceci a été particulièrement observé lors de l’accélération des clics (en l’occurrence chez le sujet « extrême » qui a cliqué 666 fois en une minute).
Le deuxième stade est la perforation progressive de la matière grise du cerveau : chaque clic, une fois qu’il a traversé la criticoïde (et ce d’autant plus vite qu’il est poussé par de nouveaux clics) exerce un léger coup sur la matière, un peu comme une pointe virtuelle qui dégrade le muscle à force de répétition ; ces coups-clics (l’orthographe cooklics est également admise) rongent progressivement la criticoïde qui n’est bientôt pas plus efficace qu’un marshmallow (littéralement : ça marche mais lentement).
Le troisième stade observé à ce jour se caractérise par la méta-extase devant les IRM (Images Rudement Manipulées) ; cette « métaxtase » en vient à paralyser les organes environnants qui pâtissent à leur tour de la clicomania et sont peu à peu grignotés (un peu comme des petits gâteaux ou cookies) par la spirale cliqueuse. La criticoïde étant totalement épuisée et inopérante, « l’enzyme du clic » pénètre toujours plus loin dans l’organisme du patient [4].
Certaines personnes, totalement dénuées d’esprit scientifique, se sont crues autorisées à proposer des actions préventives pour éviter de contracter la maladie ou, du moins, ralentir son développement : greffer une criticoïde en titane sur les sujets à risque, brider les outils pour freiner les clics, ou encore organiser des concours du moindre clic dotés de prix attractifs.
Un nouveau projet est à l’étude dans le laboratoire de Mado EKAF et Sacha SWEN, toujours au sujet des clics. Il porte sur l’incidence délétère du clic sur l’oculitée, cette pellicule sensible à la surface du globe oculaire dont la fonction est simplement de voir ce qu’il y a à voir, même quand ça ne brille pas. Le laboratoire est à la recherche de volontaires . Contact.
Source : MAC sans AFP
 Notes oulipiennes
Notes oulipiennes
[1] Mado EKAF a précédemment effectué des recherches sur les tocs liés au tic-tac chez les TUC (titulaires de contrats de travaux d’utilité collective dans les années 1980) dont certains étaient obnubilés par le tic-tac des horloges en attendant la fin de la journée de travail.
[2] Sacha SWEN, quant à lui, est spécialiste des cloques chez la « clique des claques », gang bien connu dont les membres se sont illustrés au début des années 2000 en distribuant des claques gratuites à tour de bras dans les espaces publics et privés. En effet, des cloques étaient apparues sur les paumes des membres de la clique, et Sacha SWEN cherchait une corrélation entre la taille des cloques, les lieux d’administration des claques et le profil des victimes.
[3] La criticoïde ou glande de Tucapt doit son nom à la chercheuse Eskeu TUCAPT, du 2IG (Institut des Inventions Glandeuses), découverte intervenue par hasard en décembre 1999, à la faveur d’un bug dans le passage à l’an 2000.
[4] Des détracteurs de EKAF et SWEN se sont moqués de cette observation en pointant la contradiction entre les concepts de patient et d’impatience. En effet, la maladie du clic étant due essentiellement à l’impatience du sujet, il est tout à fait illogique de qualifier de « patients » les personnes atteintes. De qui se moque-t-on ?
L’article Les clics sont cancérogènes, alertent deux chercheurs est apparu en premier sur Le blog de Marie-Anne Chabin.
Les deux âges des archives
Depuis plus de quarante ans, une des bases conceptuelles de la formation des archivistes francophones est la théorie des trois âges des archives.
Il existe plusieurs définitions ou explications de cette théorie. Commençons par l’encyclopédie en ligne Wikipédia qui dit : « La théorie des trois âges des archives est une thèse selon laquelle le cycle de vie d’un document d’archives connaît trois phases : une période dans laquelle il sert pour son utilité première, une deuxième étape intermédiaire dans laquelle il est archivé provisoirement et reste accessible en cas de besoin imprévu, puis un dernier stade qui consiste dans son archivage pérenne ».
Les glossaires des archivistes définissent les archives courantes, les archives intermédiaires et les archives définitives, en se basant sur la réglementation française, plus précisément les décrets d’application de la première loi sur les archives, promulguée en 1979 et intégrée aujourd’hui (dans sa version 2008) dans le code du patrimoine. Extrait de la partie réglementaire du code (la partie législative ne relayant pas, heureusement, cette « thèse » sur les « âges » des archives) : « Sont considérés comme archives courantes les documents qui sont d’utilisation habituelle pour l’activité des services, établissements et organismes qui les ont produits ou reçus » (article R212-10) ; « Sont considérés comme archives intermédiaires les documents qui : 1° Ont cessé d’être considérés comme archives courantes ; 2° Ne peuvent encore, en raison de leur intérêt administratif, faire l’objet de sélection et d’élimination conformément aux dispositions de l’article R. 212-14 » (article R212-11) ; « Sont considérés comme archives définitives les documents qui ont subi les sélections et éliminations définies aux articles R. 212-13 et R. 212-14 et qui sont à conserver sans limitation de durée » (article R212-12).
On peut noter au passage que la réglementation ne parle pas de théorie ni de cycle de vie des documents ; et que la page Wikipédia n’utilise pas les expressions « archives courantes », « archives intermédiaires » et « archives définitives ».
Cette théorie des trois âges des archives est généralement attribuée à Yves Pérotin, directeur des archives de la Seine au début des années 1960 et auteur d’un texte intitulé « L’administration et les “trois âges” des archives ». Cette attribution de la prose actuelle à Yves Pérotin est un raccourci ennuyeux. Il semble qu’on prête à celui-ci plus qu’il n’a écrit et que sa pensée a été reformulée, « aménagée », voire déformée avant d’être figée, sanctuarisée et répétée à des générations d’étudiants, sans faire vraiment preuve de l’esprit critique qui caractérisait justement Yves Pérotin. J’en viens à me demander si la théorie des trois âges des archives, telle qu’elle est diffusée aujourd’hui encore, ne doit pas davantage à Michel Duchein, qui est finalement l’auteur qui en a le plus parlé et qui la voyait « éternelle » [1], qu’à Yves Pérotin.
La théorie des trois âges a cependant subi quelques critiques ces dernières décennies [2], la plus connue étant celle qu’a exprimée Marcel Caya en 2004 dans une conférence titrée « La théorie des trois âges en archivistique. En avons-nous toujours besoin ? ». Marcel Caya, avec une vision nord-américaine de la gestion des documents (records management), se demande notamment si les propositions « exploratoires » d’Yves Pérotin sur la gestion des masses d’archives ne sont pas corrélées à la situation administrative de la France dans les années 1960 (situation qui a changé), et si l’intérêt de la réflexion de Pérotin ne tourne pas davantage sur le séquencement des lieux de stockage et des responsabilités que sur le nombre « trois ». Un autre argument, repris par d’autres articles, est que l’environnement numérique périmerait la notion d’archives intermédiaires. Et, pour ma part, il y a longtemps que j’ai exprimé mes critiques sur le caractère par trop logistique et contre-productif du mantra « archives courantes et intermédiaires », quel que soit le support.
À l’occasion du colloque consacré en septembre dernier à Yves Pérotin par les Archives de Paris et l’École nationale des chartes, un siècle après sa naissance, j’ai relu ou lu attentivement les publications très variées de Pérotin pour préparer ma communication intitulée « Yves Pérotin et l’écriture ». Ces lectures ont bien évidemment réactivé ma réflexion sur tous les aspects de la pensée pérotine. Or, vu que, paradoxalement, aucune intervention de ce colloque n’était spécifiquement consacrée à la théorie des trois âges des archives, j’ai entrepris l’écriture de ce billet car le sujet mérite d’être débattu [3].
Les « âges » des archives selon Yves Pérotin Donc, le fameux texte de référence d’Yves Pérotin est publié en 1961 dans une revue administrative peu diffusée, intitulée Seine et Paris [4]. Cet article, par ailleurs fort cité, n’est pas facilement accessible en ligne. On ne le trouve guère que sur un site québécois, dans une version scannée un peu floue. Il m’a donc paru utile, à l’appui de ce billet « Les deux âges des archives » d’en proposer une transcription plus facilement accessible.
Donc, le fameux texte de référence d’Yves Pérotin est publié en 1961 dans une revue administrative peu diffusée, intitulée Seine et Paris [4]. Cet article, par ailleurs fort cité, n’est pas facilement accessible en ligne. On ne le trouve guère que sur un site québécois, dans une version scannée un peu floue. Il m’a donc paru utile, à l’appui de ce billet « Les deux âges des archives » d’en proposer une transcription plus facilement accessible.
Au début de l’article, Pérotin présente délibérément « une vue simpliste des choses » :
L’observateur le moins averti reconnaît deux âges dans la « vie » des archives publiques. D’abord celui des documents administratifs : les bureaux conservent à leur disposition leurs papiers récents (registres et dossiers bien constitués, utiles, pratiques en même temps que banals et prosaïques). Ensuite l’âge des documents historiques : les Archives conservent dans leurs magasins les papiers anciens, plus ou moins parcheminés, recouverts de cette fine couche de poussière qui habille les grands crus.
[…]
À ce point d’observation, les archives vivantes et les archives archivées semblent parfaitement hétérogènes, ce qui rend impensable le passage d’un stade à l’autre, passage qui a pourtant bien dû se faire. L’observateur peu averti n’est pas gêné par ce mystère parce qu’il ne se pose pas de problèmes. Si, cependant, on pratique à son égard une maïeutique pressante, on le mènera à découvrir qu’il existe un stade intermédiaire entre l’ordre (apparent) des dossiers des bureaux et l’ordre (apparent) des cartons d’archives.
[…]
Ainsi se révèle l’âge intermédiaire, l’âge ingrat des archives, celui des ‘tas’, fâcheuse transition entre l’Administration et l’Histoire.
Et de conclure ce premier constat par ces mots :
Or, si, dans les observations sommaires que je viens de résumer, il y a bien la reconnaissance des trois âges fondamentaux des archives, tout le reste ne vaut rien. L’analyse est complètement fausse. Car il n’y a pas de véritable ordre au début, pas de véritable ordre à la fin, pas de miracle entre les deux : il n’y a que des faits déplorables dont administrations et archivistes sont plus ou moins responsables.
Dans la suite de son texte, Pérotin cherche une méthode (il utilise le mot doctrine) pour mieux maîtriser ces entassements non contrôlés lors du stade intermédiaire. C’est ainsi qu’il en vient à décrire « les différents âges des archives », chaque « âge » étant inauguré par une opération d’élimination des documents périmés, avec la terminologie suivante :
Premier âge : archives courantes (après un premier tri réalisé par l’Administration) ; la durée de ce premier âge est évaluée entre un et quatre ans.
Deuxième âge : archives de dépôt, pour une période de vingt à cent ans (après une deuxième élimination des « papiers devenus inutiles pour l’Administration et sans intérêt pour l’Histoire ») ; la responsabilité de ce stockage revient à l’Administration sous contrôle des services d’archives.
Troisième âge : archives archivées (après une troisième opération de tri-élimination effectuée par les archivistes).
En 1964, après un voyage d’études outre-Manche, Pérotin publie dans la Gazette des archives un article intitulé « Le records management et l’administration anglaise des archives » où il décrit, entre autres, la pratique britannique de dépôts intermédiaires.
 Quelques années plus tard, dans sa contribution au Manuel d’archivistique publié par la direction des Archives de France en 1970, Yves Pérotin développe son analyse dans un passage intitulé « Les dépôts intermédiaires ou de « pré-archivage » » (terme tombé aujourd’hui en désuétude). Après un constat de la situation qui ne s’est pas améliorée, il s’appuie, reprenant les mots de l’Américain T.R. Schellenberg, sur les notions de valeur primaire (intérêt administratif) et de valeur secondaire (intérêt pour la recherche historique) des papiers qui constituent les archives pour conclure : « Ainsi s’impose par la force des choses, une notion d’ « âge intermédiaire » correspondant à ce stade où les deux valeurs des papiers sont simultanément basses mais où au moins l’une des deux n’est pas négligeable – fût-ce seulement en puissance. Tout naturellement nous sommes amenés à en déduire une notion de « dépôts intermédiaires », c’est-à-dire de locaux économiques, moins chers que les bureaux et moins chers que les dépôts d’archives ». Et de qualifier un peu plus loin les dépôts intermédiaires de « bassins de décantation » des papiers administratifs. Enfin, il esquisse l’idée de plusieurs stades au sein de l’âge intermédiaire (trois pour être précis) corrélés aux besoins de consultation et à la durée de stockage.
Quelques années plus tard, dans sa contribution au Manuel d’archivistique publié par la direction des Archives de France en 1970, Yves Pérotin développe son analyse dans un passage intitulé « Les dépôts intermédiaires ou de « pré-archivage » » (terme tombé aujourd’hui en désuétude). Après un constat de la situation qui ne s’est pas améliorée, il s’appuie, reprenant les mots de l’Américain T.R. Schellenberg, sur les notions de valeur primaire (intérêt administratif) et de valeur secondaire (intérêt pour la recherche historique) des papiers qui constituent les archives pour conclure : « Ainsi s’impose par la force des choses, une notion d’ « âge intermédiaire » correspondant à ce stade où les deux valeurs des papiers sont simultanément basses mais où au moins l’une des deux n’est pas négligeable – fût-ce seulement en puissance. Tout naturellement nous sommes amenés à en déduire une notion de « dépôts intermédiaires », c’est-à-dire de locaux économiques, moins chers que les bureaux et moins chers que les dépôts d’archives ». Et de qualifier un peu plus loin les dépôts intermédiaires de « bassins de décantation » des papiers administratifs. Enfin, il esquisse l’idée de plusieurs stades au sein de l’âge intermédiaire (trois pour être précis) corrélés aux besoins de consultation et à la durée de stockage.
Il est intéressant de souligner que Pérotin ne parle pas une seule fois d’ « archives intermédiaires », ni dans le premier texte (« L’administration et les trois âges des archives », 1961) ni dans l’article publié dans la Gazette des archives en 1964 ni dans le Manuel d’archivistique. Dans le premier texte, on trouve cinq occurrences de l’adjectif « intermédiaire », deux fois pour qualifier le mot « statut », une fois pour « âge » et deux fois pour « dépôt ». Dans le texte sur le « records management », les douze occurrences du mot appartiennent à l’expression « dépôts intermédiaires ». Dans le Manuel d’archivistique, il est question d’âge intermédiaire ou surtout de « dépôts intermédiaires ».
En relisant ces textes un demi-siècle après leur publication et au regard de ce qui se dit et s’écrit aujourd’hui sur cette sacro-sainte théorie des trois âges des archives, je me dis que certaines questions n’ont pas été posées ou reposées :
- la notion d’archives courantes est plus précise chez Pérotin que dans la loi française ; la définition légale (« Les archives sont l’ensemble des documents, quels que soient leur date, leur lieu de conservation, leur forme et leur support, produits ou reçus par toute personne physique ou morale et par tout service ou organisme public ou privé dans l’exercice de leur activité », article L211-1 du code du patrimoine) est très englobante : tout est archive. Dans l’article de 1961, Pérotin désigne par « archives courantes » les dossiers qui ont déjà fait l’objet d’un premier tri, par les utilisateurs (les bureaux), ce qui rapproche la notion pérotine d’archives courantes de celle de records, c’est-à-dire de dossiers débarrassés des papiers inutiles, autrement dit débarrassés des « non-records » ; or, la définition légale française englobe tout dans les archives, records ET non-records.
- le mot archives est utilisé par Pérotin dans son acception plurielle ; il s’agit de l’ensemble des dossiers d’un service producteur regroupés à un endroit donné. Pérotin décrit les différents stades de stockage de ces archives dans des dépôts distincts, avec la notion de bassin de décantation ou de dépôt intermédiaire entre les bureaux et les magasins d’archives historiques. Il parle de la « vie » des archives avec des guillemets et, s’il utilise une fois l’expression « deuxième âge des documents », il n’évoque à aucun moment le « cycle de vie » des documents d’archives (on peut remarquer au passage que ce « cycle » est souvent schématisé aujourd’hui par un tracé linéaire [5]). L’approche de Pérotin est une approche de gestion des masses documentaires dans une optique d’optimisation de la conservation des documents avant l’opération d’élimination ou de sélection à titre d’archives historiques, et non une théorie sur les étapes de vie de chaque document. De ce point de vue, le glissement sémantique opéré au cours des dernières décennies n’est pas innocent. La définition des trois âges des archives donnée par Wikipédia (voir ci-dessus) est même assez éloignée du discours de Pérotin [6].
- C’est parce qu’il était confronté à un manque crucial de place de stockage dans le bâtiment des Archives de la Seine au début des années 1960 qu’Yves Pérotin a argumenté ses « trois âges » des archives. Il lui fallait trouver de la place et il lui fallait convaincre l’administration de cette nécessité. L’approche est avant tout économique. La notion de « dépôts intermédiaires » vise des « locaux économiques, moins chers que les bureaux et moins chers que les dépôts d’archives » (cf supra). De ce point de vue, les archives intermédiaires dans les magasins des services d’archives sont une mauvaise pratique. La réponse concrète (les locaux économiques) est venue des prestataires en gestion externalisée d’archives, dont la profession s’est organisée dans les années 1980 et Yves Pérotin apparaît comme précurseur dans sa façon de penser cette organisation du « stockage intermédiaire ». On peut regretter à ce sujet que le débat n’ait pas été davantage approfondi entre ces prestataires de service et les institutions archivistiques. Il est vrai qu’il a fallu attendre 2009 pour que ces sociétés aient le droit de gérer des archives publiques, même si de nombreuses organisations recouraient déjà depuis longtemps à leurs services efficaces.
 Les deux âges des archives
Les deux âges des archives
Cette théorie des trois âges des archives telle que diffusée aujourd’hui ne m’a jamais enthousiasmée (c’est un euphémisme). Autant l’article « fondateur » d’Yves Pérotin (qu’il faut replacer dans le contexte des années 1960) m’intéresse pour l’analyse et l’argumentation, autant je me dis que la déformation que sa pensée a subie ultérieurement n’est pas convaincante.
Je partage avec Pérotin la première partie de son analyse et son constat des deux âges des archives publiques : l’âge des documents administratifs puis l’âge des documents historiques. Je partage également son engagement professionnel pour trouver des solutions aux défis que pose le fameux passage des archives administratives aux archives historiques. Mais un demi-siècle plus tard, je suis persuadée que si Pérotin était toujours parmi nous, il serait surpris du discours ambiant sur les « archives courantes et intermédiaires », et qu’il aurait une vision différente de cette subtile frontière entre les deux âges essentiels.
Avant de poursuivre, je m’arrête sur la notion d’âge car l’interprétation discutable des propositions d’Yves Pérotin sur les âges des archives ne tient pas qu’au sens donné au mot archives (document individuel versus masse) mais également à la compréhension du mot « âge ». Le mot âge peut se comprendre de deux façons (voir le Centre national de ressources textuelles et lexicales) : ou bien il indique le temps écoulé dans la vie d’un être ou d’un objet depuis le début de son existence ; ou bien il désigne une époque considérée dans son unité ou son originalité. Aujourd’hui, on lui donne le premier sens mais il me semble assez évident que Pérotin a essentiellement utilisé le mot « âge » dans le second sens (âge administratif et âge historique). Du reste, il utilise à plusieurs reprises, notamment dans l’introduction de son article, les synonymes « étapes » ou « stade ». Le mot étape porte une évocation visuelle de lieux de séjour distincts (bureau, autres locaux plus ou moins éloignés, service d’archives). Quant au mot stade, plus fréquent sous la plume de Pérotin, il vise également l’aspect physique de la conservation : ordre apparent (ordre des bureaux, ordre des archives) versus entassements désordonnés (stade intermédiaire). Il parle du « stade de rédaction », du « stade de conservation », « stade où les papiers sont utilisés ».
L’objectif de l’article de 1961 est de faire émerger des solutions au problème auquel Pérotin est alors confronté dans sa vie professionnelle : la gestion du passage entre l’âge administratif et l’âge historique, avec des volumes qui explosent, en préservant les intérêts de l’administration et en évitant la perte de documents d’intérêt historique. L’angle de vue est celui de la gestion efficace mais Pérotin souligne aussi les enjeux de responsabilité : responsabilité partagée de l’Administration et des services d’archives dans le désordre intermédiaire, responsabilités respectives de l’Administration et des services d’archives dans l’organisation de chaque lieu de conservation : bureaux, bassins de décantation et magasins historiques. Cette dimension de responsabilité a été relevée par plusieurs commentateurs (Caya, Fuentes-Hashimoto) mais il apparaît que la profession dans son ensemble a minimisé cet aspect de la réflexion pour se centrer sur les questions de stockage physique.
Or, s’il y a plusieurs « zones » de stockage, il n’y a que deux responsables : l’Administration et les services d’archives. D’un côté, l’Administration doit organiser les traces de son activité, optimiser l’exploitation des informations collectées pour ne pas recréer des documents déjà produits et perdus (ce que Pérotin dénonce aussi dans son article), etc. L’Administration doit aussi, et de plus en plus, maîtriser les risques informationnels en conformité avec la réglementation et en tenant compte des enjeux sécuritaires. De l’autre côté, l’administration des Archives a pour mission de collecter et de conserver les documents de mémoire collective pour les mettre à disposition de la population et les préserver pour les générations futures. Les missions ne sont pas les mêmes ; les intérêts ne sont pas les mêmes ; les budgets ne sont pas les mêmes ; les méthodes ne sont pas les mêmes ; les risques ne sont pas les mêmes [7].
 C’est pourquoi, pour être compris d’un large public, il me semble préférable de s’en tenir à deux âges basés sur les responsabilités, qui correspondent du reste aux termes anglo-saxons « records » et « archives », et d’aborder la gestion du passage d’un « âge » à l’autre, qui est la préoccupation de Pérotin, avec d’autres mots : âge de responsabilité et âge du patrimoine, âge du droit et âge de la connaissance, âge de l’action et âge de la mémoire collective, etc. Cela permettra d’éviter l’écueil de la confusion entre la valeur intrinsèque des documents et leur lieu de stockage. S’appuyer sur deux âges complémentaires pour deux bénéficiaires distincts (producteur, collectivité) permet également d’éviter la dérive vers cette image du cycle de vie linéaire des archives qui ne colle pas à la réalité et qui enferme dans une vision étriquée des possibilités [8].
C’est pourquoi, pour être compris d’un large public, il me semble préférable de s’en tenir à deux âges basés sur les responsabilités, qui correspondent du reste aux termes anglo-saxons « records » et « archives », et d’aborder la gestion du passage d’un « âge » à l’autre, qui est la préoccupation de Pérotin, avec d’autres mots : âge de responsabilité et âge du patrimoine, âge du droit et âge de la connaissance, âge de l’action et âge de la mémoire collective, etc. Cela permettra d’éviter l’écueil de la confusion entre la valeur intrinsèque des documents et leur lieu de stockage. S’appuyer sur deux âges complémentaires pour deux bénéficiaires distincts (producteur, collectivité) permet également d’éviter la dérive vers cette image du cycle de vie linéaire des archives qui ne colle pas à la réalité et qui enferme dans une vision étriquée des possibilités [8].
En effet, si le défi auquel était confronté Pérotin était bien celui des entassements non contrôlés entre les bureaux et les services d’archives, cela ne signifie pas que tout document d’archives traverse trois périodes successives : courante, intermédiaire et définitive comme on l’entend régulièrement. Si cela a pu être observé pour les « papiers administratifs », le schéma linéaire n’est plus représentatif de la réalité, notamment du fait des technologies et du fait de l’évolution de la notion d’archives.
Les technologies numériques ont un impact certain non seulement sur la production mais aussi sur la collecte des archives. Le numérique ne change pas le stockage de documents inutiles, périmés, inexploitables, car cela relève plus de mauvaises pratiques humaines que de la technique et de la technologie ; au contraire, le numérique ne fait qu’exacerber ces mauvaises pratiques et provoque des entassements bien pires que dans les années 1960. En revanche, le numérique permet, mieux que le support papier, la mise en sécurité des documents dans un lieu de conservation dès sa création sans en déposséder son émetteur, par capture de « l’original » (horodatage et traçabilité) au service aussi bien de la preuve pour le producteur que de l’authenticité pour le chercheur. Ainsi le numérique permet de repenser la mise en œuvre de l’archivage, de s’appuyer sur cette technologie pour éviter l’attente de la péremption pour la collecte des documents de mémoire. Organiser des « archives intermédiaires numériques » uniquement pour se conformer à la sacro-sainte théorie des trois âges des archives est une stupidité, ce qui ne veut pas dire que le stockage à moindre coût des données peu consultées n’est pas une bonne pratique, au contraire ! Simplement, on continue de mélanger la question logistique et la question de la sélection du patrimoine. Cette fausse-bonne idée du cycle de vie a diablement la vie dure !
Par ailleurs, la part des papiers administratifs dans la constitution des fonds d’archives a régressé au cours des dernières décennies. Les « entrées par voie extraordinaire » (l’expression remonte au milieu du 20e siècle voire plus loin [9]) ne sont plus si « extraordinaires » ; elles ont même la faveur des archivistes, à une époque où les « nouvelles archives », celles qui ne sont pas le sous-produit de l’administration mais qui sont produites pour elles-mêmes, pour être des archives, ont le vent en poupe. De cet angle de vue, quel sens cela a-t-il de parler de l’âge intermédiaire :
des dessins d’un enfant pendant le confinement général de 2020,
du témoignage d’un passant sur le mémorial d’un attentat,
de « l’archive radiophonique » de l’interview de Bruno Latour du 3 avril 2020 ?
Il y a deux réalités : celle du producteur en tant qu’acteur qui laisse des traces de son activité, et celle du patrimoine en tant que bien commun. Le passage d’une réalité à l’autre n’obéit pas à un schéma unique. Il varie en qualité, en intensité, en durée et en complexité, selon la finalité de la production, selon la nature de l’information produite, selon la valeur patrimoniale qu’on lui attribue (encore un sujet trop peu débattu…). Et il ne faut pas oublier que le pourcentage de la production informationnelle globale qui intègre un jour les archives historiques est infime (1 % ?), de sorte qu’il est préférable de concentrer son énergie sur l’identification du 1 % à conserver plutôt que sur l’élimination des 99 %. L’époque n’est-elle pas aux économies d’énergies ? [10].
Si les « dépôts intermédiaires » économiques reste une réponse technique au problème de stockage, la notion de bassin de décantation ne saurait être généralisée à tout ce qu’un service d’archives collecte aujourd’hui. Du point de vue de l’Administration, le stockage des données est bien plus éclaté que ne l’était naguère le stockage des papiers et les outils se sont démultipliés (applications, serveurs, cloud, outils semi-personnels…). La possibilité technique de collecte d’un exemplaire des fichiers pour le patrimoine est trop peu exploitée et les services des prestataires (éditeurs, intégrateurs, hébergeurs…) pourraient être affinés avec des critères d’archivage ou d’exploitabilité dans la durée, donnés dans les cahiers des charges des applications, ce qui est loin d’être le cas. Du point de vue des services d’archives patrimoniaux, la vraie question n’est pas celle du stockage mais celle de savoir ce que l’on veut collecter, en fonction de quelle politique pour laquelle on dispose de quels moyens, ce qui peut conduire à des priorités, en parallèle des opportunités.
Face à la masse potentiellement dotée d’un intérêt patrimonial (même quand elle représente 1 % de la production globale), il apparaît aujourd’hui plus pertinent de dresser un panorama des groupes d’archives à collecter, plutôt que d’appliquer systématiquement à tout un schéma linéaire en trois étapes chronologiques. Autrement dit de dresser une cartographie des ensembles d’archives candidats à la collecte, caractérisés par les facettes de l’information : valeurs juridique et documentaire (autre formulation de la valeur primaire et secondaire), représentativité de la réalité, faisabilité et coût de la conservation, etc., puis d’en déduire un plan d’action réaliste. L’avantage est de donner à voir la production plutôt que de subir des tas. Cette vision offre la possibilité d’identifier ce que l’on veut conserver et d’intervenir en amont, soit en récupérant un exemplaire des documents (numériques), soit en introduisant une règle dans l’outil de gestion du producteur, soit en instituant une routine de contrôle périodique de la conservation et des destructions, soit en déléguant officiellement le contrôle de la catégorie à un métier ou à un prestataire, etc., autant de règles validées par le producteur et applicables à toute l’organisation. L’idée est aussi de promouvoir une identification et une sélection des archives patrimoniales en amont (avec des hypothèses dues au manque de recul mais compensées par des clauses de révision et la tenue d’un tableau de bord archivistique) plutôt que d’espérer avoir un jour le temps de trier des masses informes que le plus avisé ne saurait traiter avec pertinence (Pérotin le notait déjà [11]).
En procédant ainsi, on squeeze la gestion d’archives intermédiaires comme une masse unique ou une dénomination unique, vision qui a démontré son incapacité à résoudre et le problème du stockage et le problème de la sélection.
 C’est ce que j’ai voulu faire en créant la méthode Arcateg
C’est ce que j’ai voulu faire en créant la méthode Arcateg [12]: une cartographie des 100 valeurs possibles de l’information au moment de sa création, chaque valeur ou « catégorie de conservation » étant rattachée à une analyse de risque, codifiée et assortie de modalités de gestion (support, lieu et responsabilité de stockage, règles d’accès, règles de conservation-destruction…) qui permettent – entre autres – de piloter, de façon plus réaliste que linéaire, le passage du premier âge (celui du producteur des documents archivés) au second âge (celui du patrimoine commun).
[12]: une cartographie des 100 valeurs possibles de l’information au moment de sa création, chaque valeur ou « catégorie de conservation » étant rattachée à une analyse de risque, codifiée et assortie de modalités de gestion (support, lieu et responsabilité de stockage, règles d’accès, règles de conservation-destruction…) qui permettent – entre autres – de piloter, de façon plus réaliste que linéaire, le passage du premier âge (celui du producteur des documents archivés) au second âge (celui du patrimoine commun).
J’aurais bien aimé discuter de la méthode Arcateg avec Yves Pérotin.
______
Notes[1] Archives de France, La Pratique archivistique française, 1993, p. 233 : « … la théorie des trois âges des archives (archives courantes, archives intermédiaires, archives historiques ou définitives), qui est aujourd’hui si universellement admise qu’on aurait presque tendance à la croire éternelle. »
[2] Conférence donnée par Marcel Caya à l’École nationale des chartes le 2 décembre 2004 : « La théorie des trois âges en archivistique. En avons-nous toujours besoin ? », http://elec.enc.sorbonne.fr/conferences/caya
Lourdes Fuentes-Hashimoto et Pierre Marcotte, « Back to basics: et si on relisait Pérotin? », billet de blog, octobre 2011, https://archivesonline.wordpress.com/2011/10/12/back-to-basics-relire-perotin/
« L’archivage électronique à l’épreuve de la théorie des trois âges », billet de blog, Lourdes-Fuentes Hashimoto, 2010, https://archivesonline.wordpress.com/2010/08/30/larchivage-electronique-a-lepreuve-de-la-theorie-des-trois-ages/
Marie-Anne Chabin, « Les archives courantes, une expression logistique, confuse et contre-productive », billet de blog, juin 2013, http://transarchivistique.fr/les-archives-courantes-une-expression-logistique-confuse-et-contre-productive/
[3] « De l’archivistique au XXe siècle Hommage à Yves Pérotin (1922-1981) », journée d’études proposée par Archives de Paris et l’École des chartes, Paris, 8 septembre 2022. À noter que le livret du programme ne comporte pas une seule occurrence du mot « intermédiaires » : un signe ?
[4] Revue trimestrielle, publiée entre 1975 et 1975, conservée notamment aux Archives de Paris sous la cote PER39, https://archives.paris.fr/_depot_ad75/_depot_arko/ead/INV2000.pdf
[5] Je dois avouer qu’avant de pousser ma réflexion sur la vie des archives, j’ai longtemps utilisé cette notion de « cycle de vie linéaire » que l’on m’avait enseignée (les guillemets soulignent le paradoxe de l’expression…). J’ai même créé au tournant des années 2000 un schéma pour illustrer la vie des archives et plus précisément la distinction entre « archives » et « records », avec la borne T0 pour la création des documents, la borne T2 pour la fin d’intérêt juridique ou mémoriel pour le producteur et la borne mouvante T1 pour le stockage plus ou moins éloigné, afin d’expliquer le caractère logistique des « archives intermédiaires ». Ce schéma a d’ailleurs connu un certain succès puisque je l’ai retrouvé sur de nombreux sites, dont Wikipédia, parfois sans référence… Je tiens à remercier l’Association des Archivistes Français qui, sur la page « Que sont les archives ? », utilise deux de mes schémas dûment sourcés: https://www.archivistes.org/Que-sont-les-archives
[6] On oppose parfois la théorie des trois âges au « records continuum » théorisé par les Australiens. Mais les deux notions ne sont guère comparables puisque, pour faire court, la théorie des trois âges a d’abord à voir avec le stockage tandis que le records continuum a d’abord à voir avec le contenu des documents. https://123dok.net/article/mod%C3%A8le-records-continuum-archive-approche-dialectique-exploitation-artistique.9yn2jepy
[7] J’ai développé cette question dans mon livre Archiver, et après ? au chapitre 4 « Qui paie quoi ? » https://www.marieannechabin.fr/archiver-et-apres/4-qui-paie-quoi/
[8] Je m’inscris donc en faux contre l’affirmation qui figure en page 235 de la Pratique archivistique française, de 1993 (Michel Duchein n’est pas loin) : « Apparue dans les années soixante, la doctrine d’une succession de trois périodes dans la vie de tout document est aujourd’hui unanimement acceptée par les professionnels de l’archivage (tandis qu’il faut encore user de beaucoup d’acharnement et de persuasion pour en convaincre les administrations) ».
[9] Voir l’article de Jacques Levron, « L’intégration et la cotation des documents entrés par voie extraordinaire dans les Archives départementales », La Gazette des archives / Année 1958 / 23 / pp. 46-53 https://www.persee.fr/doc/gazar_0016-5522_1958_num_23_1_1496
[10] Globalement, il s’agit d’inverser la pratique de tri et de remplacer l’objectif d’éliminations par la mission de sélection. J’ai suggéré cette inversion en 2014 dans un billet au sujet des mails, dont l’inflation caractérise bien le problème de la masse non-archivable : https://www.marieannechabin.fr/2014/11/gestion-des-mails-jai-change-de-formule/
[11] Dans l’article de 1961, on peut lire : « … aussi les archivistes, lorsqu’ils ont la moindre place disponible, se résignent-ils le plus souvent à accueillir le fatras pour sauver les perles. Pauvres perles ! Quels triages, quels classements pourront jamais les dégager ? On fera ce que l’on pourra, c’est-à-dire très peu ; on traitera soigneusement un petit lot que l’on décantera avec soin, d’où on tirera un maigre groupe de documents à moitié inutilisables et le reste encombrera les archives ».
[12] Marie-Anne Chabin, Des documents d’archives aux traces numériques. Identifier et conserver ce qui engage l’entreprise – La méthode Arcateg, éditions KLOG, 2018, https://www.editionsklog.com/product/des-documents-d-archives-aux-traces-numeriques-identifier-et-conserver-ce-qui-engage-l-entreprise-la-methode-arcateg
L’introduction est en ligne ici : http://fr.calameo.com/read/0005936512f21cbb51459
L’article Les deux âges des archives est apparu en premier sur Le blog de Marie-Anne Chabin.
URL, traces de connexion et hygiène numérique
J’ai remarqué depuis quelques mois une subtile modification dans la façon dont, sur Internet, je peux utiliser les URL (Uniform Resource Locator autrement dit adresse d’une page Web).
Jusque-là, lors que je copiais-collais l’URL d’un article consulté en ligne, j’obtenais soit l’adresse simple (si j’étais allée directement sur le site), soit une adresse assez longue composée de l’URL proprement dit prolongée par des éléments traçant la recherche qui m’avait conduite sur la page, charge à moi de raccourcir cette référence trop longue pour la ramener à l’URL nécessaire et suffisante (ceci pour les sites qui tracent les chemins d’accès, ce que tous ne font pas).
Maintenant, en faisant le même geste (CRTL+C suivi de CRTL + V), j’obtiens un titre avec un hyperlien masqué, de sorte que je ne vois plus les traces de recherche embarquées. Si donc, je réutilise ce titre avec son lien caché, je ne vois plus que j’embarque à mon tour les traces de recherche.
Bon, avec un exemple, ce sera plus clair.
Si je me promène sur le site https://theconversation.com/fr, je peux consulter l’article « Fermeture des piscines municipales, ou quand le droit fait de la brasse coulée » publié le 14 septembre 2022. L’URL est : https://theconversation.com/fermeture-des-piscines-municipales-ou-quand-le-droit-fait-de-la-brasse-coulee-190698
 Je peux aussi lire cet article à partir de la Newsletter de The Conversation France à laquelle je suis abonnée. Je clique sur le lien dans la Newsletter et j’arrive sur la même page, à ceci près que l’URL en haut de la page est devenue : https://theconversation.com/fermeture-des-piscines-municipales-ou-quand-le-droit-fait-de-la-brasse-coulee-190698?utm_medium=email&utm_campaign=La%20lettre%20de%20The%20Conversation%20France%20du%2014%20septembre%202022%20-%202403324008&utm_content=La%20lettre%20de%20The%20Conversation%20France%20du%2014%20septembre%202022%20-%202403324008+CID_149cd898aefaeded2f7fc98a5eef8e37&utm_source=campaign_monitor_fr&utm_term=Fermeture%20des%20piscines%20municipales%20ou%20quand%20le%20droit%20fait%20de%20la%20brasse%20coule
Je peux aussi lire cet article à partir de la Newsletter de The Conversation France à laquelle je suis abonnée. Je clique sur le lien dans la Newsletter et j’arrive sur la même page, à ceci près que l’URL en haut de la page est devenue : https://theconversation.com/fermeture-des-piscines-municipales-ou-quand-le-droit-fait-de-la-brasse-coulee-190698?utm_medium=email&utm_campaign=La%20lettre%20de%20The%20Conversation%20France%20du%2014%20septembre%202022%20-%202403324008&utm_content=La%20lettre%20de%20The%20Conversation%20France%20du%2014%20septembre%202022%20-%202403324008+CID_149cd898aefaeded2f7fc98a5eef8e37&utm_source=campaign_monitor_fr&utm_term=Fermeture%20des%20piscines%20municipales%20ou%20quand%20le%20droit%20fait%20de%20la%20brasse%20coule
Cette formule, nettement plus longue et plus cabalistique, inclut, derrière l’URL simple, suivie d’un point d’interrogation, des éléments indiquant que j’arrive sur la page via la Newsletter, ce qui en soit n’est pas confidentiel, les sites Web ayant intérêt à pister un peu la fréquentation de leur page. Pourquoi pas ? Je me place ici du point de vue de l’utilisateur.
Or, ce que je veux souligner est que, alors qu’hier je voyais cette URL à rallonge quand je copiais-collais la référence d’un article, elle est aujourd’hui a priori masquée. Si je fais CRTL+C suivi de CRTL+V dans un fichier Word, dans un mail ou dans un post sur un réseau social, pour ce même article : j’obtiens : Fermeture des piscines municipales, ou quand le droit fait de la brasse coulée (theconversation.com) c’est-à-dire le titre donné par le site à l’URL longue.
Pour obtenir ce que j’avais avant, c’est-à-dire le titre long que je peux abréger pour avoir l’URL « propre », je dois coller le titre avec un clic droit.
Et alors ? Pourquoi gaspiller mes mots et le temps de mes lecteurs avec d’aussi infimes détails dont tout un chacun se contrefiche ? Il y a quand même des sujets plus sérieux à discuter, non ?
Eh bien, pour deux raisons.
La première est que j’aime bien savoir ce que je fais, disons ce qu’Internet me fait faire. Par ailleurs, on nous rebat assez les oreilles avec les spams ; or, très souvent les liens vicieux présents dans les mails ont justement une forme de titre accrocheur et il faut passer délicatement la souris sur ce titre pour voir l’ineptie de l’URL derrière. Donc, tant qu’à être attentif et à s’habituer à des liens propres et explicites, autant le faire pour tout.
La seconde raison est que si je partage un lien avec d’autres, il est plus correct d’avoir une URL sobre plutôt qu’une adresse alourdie de fioritures inutiles qui, à la longue, alimentent une traçabilité des faits et gestes des internautes qui me sont assez tracés comme ça.
Je remarque de plus en plus de posts sur LinkedIn qui partagent un article de presse avec l’URL à rallonge, masquée par le titre. Exemple le post suivant datant du 26 septembre 2022 (j’ai retiré le nom de la personne) :
 Je clique sur le lien et je note que l’URL est https://www.lefigaro.fr/actualite-france/hopital-de-l-essonne-cyberattaque-les-hackers-ont-diffuse-des-donnees-20220925?utm_source=app&utm_medium=sms&utm_campaign=fr.playsoft.lefigarov3, alors que
Je clique sur le lien et je note que l’URL est https://www.lefigaro.fr/actualite-france/hopital-de-l-essonne-cyberattaque-les-hackers-ont-diffuse-des-donnees-20220925?utm_source=app&utm_medium=sms&utm_campaign=fr.playsoft.lefigarov3, alors que
https://www.lefigaro.fr/actualite-france/hopital-de-l-essonne-cyberattaque-les-hackers-ont-diffuse-des-donnees-20220925 aurait été suffisant.
Je vois aussi dans les bibliographies (celles des mémoires d’étudiants par exemple), certaines URL à rallonge, non toilettées, qui me font sourire car je vois comment l’étudiant a procédé en coulisse, et ce n’est pas toujours à son avantage…).
Cette mauvaise pratique me fait penser à celle qui consiste à diffuser un document soi-disant définitif à un destinataire (client, avocat, professeur…) au format Word avec toutes les modifications apportées au fichier embarquées bien que masquées. Un client me racontait un jour combien il avait ri en recevant d’un prestataire, en réponse à un appel d’offre, une offre dont le nom de fichier finissait par « … V13.doc » et où le client avait pu exhumer les hésitations et commentaires internes de l’entreprise pour la rédaction de cette offre commerciale. Inutile de dire que le prestataire n’avait pas été retenu et avait même été blacklisté.
Bref, le sujet est sans enjeu ou presque. C’est juste une question d’hygiène numérique, voire de politesse numérique.
L’article URL, traces de connexion et hygiène numérique est apparu en premier sur Le blog de Marie-Anne Chabin.
Images insoutenables et archives publiques
Le mardi 6 septembre 2022, au deuxième jour du procès de l’attentat de Nice du 14 juillet 2016, la question est posée de savoir s’il faut ou non diffuser en audience les images de vidéo-surveillance captées pendant la course meurtrière du camion sur la promenade des Anglais. Faut-il montrer aux parties civiles et au public ces 4 minutes 17 secondes d’images « insoutenables » ? Quel apport à la procédure ? Quel impact ?
Laurent Raviot, président de la cour d’assises spéciale, s’est d’abord opposé à cette diffusion, notamment pour « éviter le voyeurisme ou le sensationnalisme ». Puis, il a précisé que, si la vidéo venait à être diffusée, il demanderait de couper l’enregistrement du procès dans le cadre de la constitution des archives audiovisuelles de la justice, au motif qu’il « ne souhaite pas que ces images se retrouvent sur les réseaux sociaux dans trente ans ».
Après échange entre les magistrats et les avocats, les images sont finalement diffusées en audience le jeudi 15 septembre.
L’argument avancé par le président Raviot a retenu mon attention et suscité une remarque, puis une interrogation.
Tout d’abord, j’ai me suis fait la réflexion qu’il n’existait pas – du moins que je ne connaissais pas – de typologie normalisée des images animées dans les archives publiques (j’entends le mot archives au sens de documents émis, reçus et détenus par les pouvoirs publics dans l’exercice de leur mission, aussi bien qu’au sens d’archives patrimoniales).
Le critère du support reste prédominant dans la gestion archivistique actuelle (archives papier, archives audiovisuelles, archives numériques…), alors que cette distinction est de moins en moins pertinente, sauf dans une vision technique de conservation. Pourtant, pour ne parler que des images animées en lien avec des procès, il n’est pas anodin de distinguer, en fonction de leur provenance, de leur finalité première et de leur rôle dans le déroulement du procès (liste non exhaustive évidemment), les éléments suivants :
Les images de vidéo-surveillance, celles qui sont au cœur du débat dans l’article qui a déclenché ce billet ; ce sont des documents qui sont créés automatiquement, sans finalité précise si ce n’est, le cas échéant, a posteriori, de disposer d’un enregistrement audiovisuel de ce qui s’est passé dans le champ de la caméra. Le plus souvent, il ne se passe rien et les images dont la durée de conservation est réglementée sont régulièrement effacées. D’autres fois, il peut être utile de les consulter pour prouver qui a fait quoi à telle heure à tel endroit, en général pour une recherche de responsabilité lors d’un accident ou d’une manifestation. Les images sont alors saisies pour documenter la procédure. C’est ce qui s’est passé lors des incidents du stade de France le 28 mai 2022 dans le cadre de la finale de la Ligue des champions (images dont la destruction prématurée a fait couler beaucoup d’encre pendant le mois de juin). Mais dans le cas de Nice, il n’y avait pas besoin de prouver la culpabilité de qui que ce soit ; la responsabilité du tueur était évidente sans ces images. Mais les images « objectives » des caméras de surveillance permettent de mieux comprendre un drame dont on peine à imaginer la férocité, ce qui a motivé leur diffusion. Et même si elles n’avaient pas été diffusée en audience, elles seraient une pièce au procès (cela dit sous réserve de vérification auprès du tribunal).
Cas plus rare (heureusement) : les images créées délibérément par le tueur qui décide de filmer son forfait, comme l’a fait Mohamed Merah en 2012, images qui n’ont pas été saisies mais on pourrait imaginer que ce type de vidéo, saisi par la police, soit versé au procès.
Autre type de vidéo : celles issues de smartphones des personnes privées qui ont assisté à la scène judiciarisée et qui, pour certaines, peuvent être versées au dossier de l’enquête. La qualité des images peut être médiocre mais si elles existent, c’est pour montrer qu’il se passe quelque chose.
Plus classiquement, on pourra y trouver les constats réalisés sur les lieux des événements par les autorités policières, judiciaires ou autres (les pompiers, les soignants), a posteriori, parce qu’il s’est passé quelque chose, et qui peuvent avoir une forme audiovisuelle quand les outils de travail le permettent.
Et bien sûr les « archives audiovisuelles de la justice », catégorie de documents très spécifique, qui a vu le jour avec la loi n°85-699 du 11 juillet 1985 voulue conjointement par le président Mitterrand et Robert Badinter. Cette loi crée un genre nouveau : le film d’un procès, créé volontairement dans un but de témoignage, à des fins historiques et pédagogiques, autrement dit un film qui est sa propre finalité et non, comme le sous-entend la définition traditionnelle des archives, un document qui découlent de l’activité judiciaire, le « sous-produit » d’une procédure. Le mot archives, dans cette expression, est donc à interpréter dans l’acception nouvelle des archives appliquées aux enregistrements de la télévision (archives de l’INA) et dans les collections chronologiques de publications de presse (le qualificatif « nouvelles » est toutefois relatif car cela fait quand même quelques décennies qu’on parle d’archives audiovisuelles).
Il y aurait lieu de développer cette typologie et de l’étendre à d’autres domaines administratifs.
Mais ce qui a motivé ce billet est la réflexion du président Raviot concernant la mésutilisation potentielle, un jour, de ces images de vidéo-surveillance : « Je ne souhaite pas que ces images se retrouvent sur les réseaux sociaux dans trente ans ».
Cette formulation nourrit plusieurs interrogations :
Quel est le niveau de risque ? Dès lors que le contrôle de l’usage – ou plutôt du non-usage – de smartphones pendant la diffusion en audience est efficacement effectué, comment ces images pourraient-elles se retrouver sur les réseaux sociaux dans trente ans ? Que seront les réseaux sociaux dans trente ans ? Le risque pointé est-il que, enregistrées dans le film intégral du procès, ces 4 mn 17 s de vidéo soient consultées et exploitées au bout d’un certain temps et que, dans le cadre de cette exploitation par des chercheurs, des journalistes, des producteurs…, elles soient détournées sur des réseaux ? Et pourquoi trente ans ? Les « archives audiovisuelles de la justice » (le film du procès) sont légalement librement communicables après cinquante ans ; avant l’expiration de ce délai, une dérogation est possible pour les personnes qui présentent un projet éditorial convaincant en précisant les extraits dont la reproduction est sollicitée. Cette dérogation peut être demandée bien avant trente ans, en théorie tout de suite. Faut-il voir dans ces « trente ans » une façon d’évoquer un futur moyennement éloigné, et surtout plus court que les soixante-quinze ans qui sont le délai légal de communicabilité des archives proprement judiciaires (les pièces du procès) ?
La position initiale du juge (ne pas diffuser les images) au motif de les protéger d’une communication prématurée ou d’une communication non maîtrisée fait écho d’une certaine façon à l’attitude de certains responsables de certaines administrations consistant à de ne pas verser les dossiers sensibles dans les services d’archives publics dont ils relèvent au motif qu’ils pourraient être communiqués trop tôt au public (selon l’interprétation que l’on fait de certains articles du code du patrimonial). C’est tout l’objet de la polémique de 2021 sur les archives classifiées. Le risque de tomber sur une information « accusatrice » ou « toxique » perdue dans un vieux dossier (comme une aiguille perdue dans une vieille botte de foin) suscite la frilosité, voire la peur des autorités qui, ne comprenant pas très bien le fonctionnement des archives, s’inquiètent de ce qui pourrait bien advenir si ladite information prenait son envol dans la nature. Mais j’y vois une différence intéressante. Avec les archives traditionnelles, qui sont le fruit des activités des services dans la durée, on freine le versement parce que les archives sont déjà produites et que la question de ce qu’on mettait ou pas dans les dossiers n’a pas été maîtrisé à la source. Avec les « nouvelles » archives que sont les archives audiovisuelles de la justice, la question est posée au moment de la création (au moment de la fabrication du film) de ce que l’on pourra y trouver en fonction des règles de communicabilité en vigueur (lesquelles pourraient d’ailleurs changer avant les délais indiqués). Avec la production de documents qui sont leur propre finalité (l’enregistrement d’un événement pour constituer un témoignage public), il est plus facile de contrôler l’amont que pour les dossiers constitués, classés, déclassés, perdus du vue, déménagés au fil du temps par divers agents. Pourtant, le fameux « records management » est fait pour ça mais c’est une autre histoire…
Réflexion connexe : si les producteurs d’archives publiques s’autocensurent, par non-versement ou non-création, faudra-t-il miser sur les archives privées pour approfondir demain la connaissance de certains événements ?
Enfin, on peut voir dans cette déclaration du magistrat un exemple de la pression de la société de l’immédiateté sur les archives publiques. La toute puissance des réseaux sociaux distille une exigence d’immédiateté qui rabote la mémoire de demain. Que peut-il résulter de ce besoin impérieux d’accéder à tout tout de suite ? On dirait que l’œuvre du temps qui passe est complètement escamotée dans les comportements collectifs. Cette négation quasi unanime du temps qui passe comme composante de nos vies m’inquiète. C’est comme si les horreurs d’aujourd’hui ne deviendront pas un jour des faits historiques « éteints », recouverts dans la mémoire collective par de nouvelles horreurs… Or justement, les archives patrimoniales sont là, depuis des siècles, pour témoigner de cette indispensable césure entre les traces des événements accumulées par la double action administrative et archivistique, d’une part, et l’exploitation des sources mémorielles ainsi préservées pour les historiens, d’autre part. Comme le rappelait naguère l’archiviste américain Frank Boles, il y a un temps pour tout, un temps pour constituer les archives, un temps pour exploiter les archives [1].
Les lignes qui précèdent ne sont que quelques questions griffonnées en marge d’une petite phrase au sein d’une actualité judicaire qui comportent bien d’autres enjeux.
____
[1] Frank J. Boles, “To Everything There Is a Season”, in The American Archivist, 2019, traduit sur le carnet Archivalise(s) « Il y a un temps pour tout », en deux parties, 1 et 2.

L’article Images insoutenables et archives publiques est apparu en premier sur Le blog de Marie-Anne Chabin.
Déficit d’image de la GED
La Gestion Électronique de Documents (GED) existe depuis plus de quarante ans, d’abord pour faciliter l’accès à des documents papier numérisés puis pour gérer des documents nativement numériques. Or, bien que l’image soit aujourd’hui le vecteur de tous messages dans les médias et les réseaux, la GED (de même que l’archivage électronique) est très souvent illustrée par des rayonnages d’archives papier, particulièrement par cette image que j’ai remarquée des dizaines de fois depuis cinq ans que je scrute le réseau LinkedIn :
 Cette image, provenant de la banque d’images Pixabay et légendée « Archiver Des Boîtes Étagère Dossiers Documents », est également utilisée pour illustrer des propos sur la conservation, la gestion ou l’exploitation des archives papier, cas où, en revanche, elle correspond davantage au sujet traité:
Cette image, provenant de la banque d’images Pixabay et légendée « Archiver Des Boîtes Étagère Dossiers Documents », est également utilisée pour illustrer des propos sur la conservation, la gestion ou l’exploitation des archives papier, cas où, en revanche, elle correspond davantage au sujet traité:
 D’autres articles sur la GED, bien sûr, utilisent des images à connotation numérique, des images bleues (car les données numériques sont bleues, n’est-ce pas ?), par opposition au papier qui est gris ou marron :
D’autres articles sur la GED, bien sûr, utilisent des images à connotation numérique, des images bleues (car les données numériques sont bleues, n’est-ce pas ?), par opposition au papier qui est gris ou marron :
 Il existe dans le monde de la documentation et de l’archivage d’autres exemples d’illustration d’un discours numérique par des piles de papiers ou des fichiers de bibliothèque :
Il existe dans le monde de la documentation et de l’archivage d’autres exemples d’illustration d’un discours numérique par des piles de papiers ou des fichiers de bibliothèque :
 Quelle importance ?
Quelle importance ?
Aucune, ou si peu.
J’en tire toutefois trois mini-conclusions.
- Les banques d’images sont pauvres sur la question de la gestion documentaire et archivistique, preuve du faible intérêt que ces entreprises médiatiques accordent au sujet, y compris dans un environnement électronique.
- Les auteurs et/ou les éditeurs manquent d’imagination pour trouver des images plus suggestives ou plus attractives, ou alors ces personnes se satisfont d’illustrations répétitives ou approximatives parce que les utilisateurs / internautes s’en satisfont eux-mêmes et que, le sujet de la gestion électronique de documents étant finalement une thématique restreinte qui intéresse avant tout des gestionnaires de papier, cela ne vaut pas la peine de chercher autre chose.
- La réelle difficulté d’illustrer les différentes facettes du sujet numérique : montrer le support de stockage ou le contenu ? L’unité ou la masse ? Les tâches du gestionnaire ou les pratiques de l’utilisateur ? Et pourquoi ne pas utiliser des images d’autres choses, figuratives ou non, que l’on aimerait associer à la gestion de l’information numérique ?
Est-ce important ?
Non, ou si peu.
J’ai cependant noté, avec beaucoup d’intérêt, un cas d’illustration « mixte », dans un billet de Florian Delabie :
 L’image présente face à face un rayonnage de cartons physiques et un data center. Elle met donc en avant le passage de la gestion papier à la gestion numérique, ce qui est pertinent pour les missions du gestionnaire de l’information (ce qui est le propos de l’article) mais reste peu parlant pour l’utilisateur qui ne « voit » pas le stockage. Dans cette image, le stockage numérique est à gauche, ce que, avec le réflexe de lecteur de gauche à droite, j’interprète comme : « la gestion du stockage numérique qui entre dans mes missions » fait écho au stockage papier, soit que je doive gérer les deux, soit pour rappeler que la rupture du support de l’information ne doit pas masquer la continuité des contenus au-delà des supports. Ceci, tout en me disant qu’un prestataire en numérisation de documents papier, cherchant à montrer aussi cette transformation d’un support à l’autre, aurait sans doute souhaité inverser les images en mettant à gauche le papier afin de suggérer, avec les unités de stockage numérique à droite, justement, le cheminement proposé aux clients, vers le numérique.
L’image présente face à face un rayonnage de cartons physiques et un data center. Elle met donc en avant le passage de la gestion papier à la gestion numérique, ce qui est pertinent pour les missions du gestionnaire de l’information (ce qui est le propos de l’article) mais reste peu parlant pour l’utilisateur qui ne « voit » pas le stockage. Dans cette image, le stockage numérique est à gauche, ce que, avec le réflexe de lecteur de gauche à droite, j’interprète comme : « la gestion du stockage numérique qui entre dans mes missions » fait écho au stockage papier, soit que je doive gérer les deux, soit pour rappeler que la rupture du support de l’information ne doit pas masquer la continuité des contenus au-delà des supports. Ceci, tout en me disant qu’un prestataire en numérisation de documents papier, cherchant à montrer aussi cette transformation d’un support à l’autre, aurait sans doute souhaité inverser les images en mettant à gauche le papier afin de suggérer, avec les unités de stockage numérique à droite, justement, le cheminement proposé aux clients, vers le numérique.
Et je continue de m’interroger, plus globalement, sur l’impact, direct ou subliminal, des images à la une des articles et posts sur l’information, les données engageantes, la conservation numérique patrimoniale, la recherche de contenus, voire la diplomatique numérique.
Quel intérêt ?
Aucun, ou si peu.
L’article Déficit d’image de la GED est apparu en premier sur Le blog de Marie-Anne Chabin.
Les bulletins nuls en questions
Quel est le statut archivistique des bulletins nuls ? Quelle est leur durée de conservation ? Quel est leur délai de communicabilité au public ?
Ces questions, naïves a priori, m’ont été suggérées par la lecture d’un article de presse en marge de la récente élection présidentielle : « Les meilleurs bulletins nuls sont aux archives départementales du Val-d’Oise », publié sur actu.fr le 20 avril 2022.
 Le point de départ de cet article, très court, est le travail de recherche de Jérémie Moualek, maître de conférences au laboratoire de sociologie de l’université d’Evry-Paris-Saclay, qui a étudié un corpus de 16 000 bulletins nuls entre 1970 et 2010, à partir des collections de plusieurs service d’archives départementaux. Le journaliste s’est intéressé aux sources et a interviewé succinctement Cécile Ribet, responsable du service « conseil, collecte, traitement » des Archives départementales du Val-d’Oise.
Le point de départ de cet article, très court, est le travail de recherche de Jérémie Moualek, maître de conférences au laboratoire de sociologie de l’université d’Evry-Paris-Saclay, qui a étudié un corpus de 16 000 bulletins nuls entre 1970 et 2010, à partir des collections de plusieurs service d’archives départementaux. Le journaliste s’est intéressé aux sources et a interviewé succinctement Cécile Ribet, responsable du service « conseil, collecte, traitement » des Archives départementales du Val-d’Oise.
D’autres médias, en ce printemps électoral, se sont intéressés spécifiquement aux bulletins nuls, non seulement dans les archives, rétrospectivement, mais aussi directement dans les bureaux de vote, à l’heure du dépouillement :
« « Un vrai moyen d’expression politique : ce chercheur dévoile chaque jour un bulletin de vote nul », interview de Jérémie Moualek par BFMTV, 29 mars 2022
« Présidentielle. Voici les bulletins de vote nul les plus insolites du premier tour », Ouest-France, 12 avril 2022, mêlant témoignages et tweets.
« « Pécresse la pôvre », Benzema, Poutine ou Louis XVI : florilège des bulletins nuls insolites glissés dans l’urne ce dimanche », Le Figaro, 25 avril 2022 ; l’article se réfère également à Jérémie Moualek et est émaillé de tweets de twittos divers publiant des bulletins nuls glanés ici ou là.
Les bulletins blancs et nuls, cette autre France de la colère », Le Monde, 25 avril 2022. L’article est peu illustré mais bien documenté, une équipe de journalistes de plusieurs régions ayant transmis des citations représentatives des bulletins nuls qu’ils ont vu dans les bureaux de vote.
Définition du bulletin nulAvant d’approfondir la question du devenir du bulletin nul, il convient de préciser ce qu’il est.
Le bulletin nul est défini par le code électoral dans son article R66. Ce sont les bulletins ne répondant pas aux prescriptions légales ou réglementaires édictées pour chaque catégorie d’élections (à l’exception de la prescription relative au grammage), les bulletins non conformes aux dispositions de l’article L. 52-3 (scrutins binominaux), les bulletins comportant une modification de l’ordre de présentation des candidats, les bulletins d’un modèle différent de ceux qui ont été produits par les candidats ou qui comportent une mention manuscrite, les circulaires utilisées comme bulletin et les bulletins manuscrits lors des scrutins de liste. Le code ne prévoit pas spécifiquement les bulletins fantaisistes.
Le site du Conseil constitutionnel précise les causes de nullité des bulletins dans le cas des référendums, avec deux groupes : les bulletins de vote comportant une signe de reconnaissance (par exemple l’insertion d’une pièce de monnaie, ce qui irait à l’encontre du principe du secret du vote), et les bulletins n’exprimant pas un choix objectivement clair de l’électeur. Le texte cite l’article 14 du décret n°2000-666 du 18 juillet 2000 portant organisation du référendum de septembre 2000 (réforme du septennat) qui mentionne en outre « les bulletins ou enveloppes portant des mentions quelconques », lesquelles « n’entrent pas en compte dans le résultat du dépouillement », mais sans utiliser le mot « nuls ».
Le Conseil constitutionnel parle de « vote détourné » et de « bulletins pirates » (avec les guillemets), présentant des commentaires personnels. Il est précisé : « Le détournement du vote peut être l’occasion pour l’électeur d’exprimer une protestation particulière (s’ajoutant à une protestation plus générale contre le système politique) ». Ces bulletins sont nuls.
À noter que le nombre de bulletins nuls de l’élection présidentielle de 2022 (environ 800 000) est moins important que celui de l’élection présidentielle de 2017 (un peu plus de 1 million). Les bulletins dits « blancs » font près du triple. Pour les élections présidentielles précédentes , les résultats officiels ne distinguent pas les bulletins nuls des bulletins blancs dans les chiffres (votes blancs et nuls sont décomptés séparément seulement depuis le 1er avril 2014) mais ils font ensemble des scores bien inférieurs : 1,8 million en 2002, 1,6 million en 2007, 2,2 millions en 2012, pour 4 millions en 2017 et 3 millions en 2022.
Statut archivistiqueLa première question est de savoir si les bulletins nuls sont des archives et, si oui, à quel type d’archives ils appartiennent.
Même sans invoquer la définition légale française des archives (tout est archives), il est assez évident que les bulletins nuls sont des documents d’archives dès lors qu’ils sont issus d’un processus administratif. L’administration organise une élection et fournit le matériel électoral, la réglementation prévoit le décompte des votes, normalise la mise par écrit du résultat dans un procès-verbal de dépouillement, le comptage des bulletins de votes « normaux » et l’annexion des bulletins blancs et nuls au procès-verbal.
Les bulletins nuls sont-ils des archives publiques ou des archives privées ? La réponse semble évidente. Il s’agit d’un processus public ; les archives qui en résultent sont donc publiques. Mais d’aucuns pourraient en douter dans la mesure où le contenu de ces « votes détournés » (pour reprendre l’expression du Conseil constitutionnel) est rédigé par des individus, des citoyens anonymes, qui y expriment souvent quelque chose de personnel. Cela n’enlève rien au fait que les bulletins appartiennent aux archives publiques (je pense à la confusion courante entre la notion de privé et la notion de personnel).
En revanche, les bulletins nuls ne sont pas des « documents administratifs » au sens de la loi du 17 juillet 1978 (accès aux documents administratifs, aujourd’hui dans le code des relations entre le public et l’administration). De fait, les bulletins nuls ne font pas partie de la liste des documents électoraux décrits par la Commission d’accès aux documents administratifs (CADA).
Les bulletins nuls sont donc bien des documents d’archives, produits lors l’élection, appartenant au dossier électoral, avec toutes les pièces qui témoignent du bon déroulement des opérations au regard de la réglementation. En tant que pièces annexes du procès-verbal (c’est là leur statut diplomatique, et non plus seulement archivistique), leur rôle est de justifier le décompte des voix non retenues pour l’élection, a minima pendant la période de recours. À ce titre, ils sont indissociables du procès-verbal qui les date, lieu et temps, dans le respect des principes archivistiques de respect de l’ordre primitif et de respect des fonds.
Est-ce à dire qu’un bulletin déconnecté du procès-verbal qu’il documente n’aurait aucune valeur ? On voit bien que non en lisant les médias friands de ces « bulletins pirates ». La piraterie (tant qu’on n’en est pas la cible directe) fait toujours rire et alimente les conversations de comptoir, sans que la valeur de document d’archives de ces bulletins y soit d’une quelconque importance. De même, si ces bulletins (ou plutôt leur reproduction car les archives publiques sont inaliénables) faisaient l’objet d’un collage par un artiste, on constaterait simplement que ces bulletins constituent « une archive » esthétiquement intéressante… La valeur esthétique d’un écrit entre depuis quelques décennies dans les critères de définition de nouvelles « archives ». C’est un constat.
Durée de conservationLa deuxième question porte sur la durée de conservation des bulletins nuls, à supposer qu’ils soient conservés.
Si on définit la durée de conservation d’un document comme le laps de temps pendant lequel ce document est préservé par la personne qui en est responsable, depuis le moment où ce document est créé jusqu’à une date où ce responsable déciderait qu’il n’est plus conservé, quel que soit le lieu de son stockage et les modalités de sa conservation, alors, comme pour beaucoup d’archives publiques, le chemin temporel se découpe en plusieurs phases. Pour les élections présidentielles et législatives, je distinguerai quatre phases :
- délai de recours de quinze jours, au sein du bureau des élections ; c’est la seule durée dont on connaisse précisément la longueur ;
- puis une certaine période de stockage des dossiers électoraux dans les bureaux ou sous-sols de la préfecture, jusqu’au versement aux Archives départementales, temps variables en fonction de critères variables ; rappelons qu’il n’existe pas en France de délai de versement, c’est-à-dire d’un temps défini réglementairement pour remettre les archives publiques au service dédié à leur traitement et conservation (et donc pas de sanction pour les administrations qui ne le font pas) ; il arrive également pendant cette période que les bulletins nuls soient supprimés par l’administration en raison de leur inutilité administrative ou pour faire de la place ;
- ensuite, le temps de dormance aux Archives départementales, autrement dit, le moment entre l’entrée physique du versement dans les locaux des archives et le traitement des documents ; ce temps peut être très court, ou très long, là encore en fonction de critères variables (planning des traitements, effectif dédié au tri, autres priorités) ;
- et enfin, le temps de l’éternité au sein des archives historiques pour les heureux élus, autrement dit les bulletins dont l’archiviste aura décidé la conservation.
Si les bulletins nuls franchissent l’étape 2 et entrent aux Archives départementales, ils dépendent alors de la circulaire DPACI/RES/2004/01 du 5 janvier 2004 consacrée au « Traitement et conservation des archives relatives aux élections politiques postérieures à 1945 », circulaire accessible aujourd’hui sur le site Legifrance, avec une date de déclaration d’opposabilité :au 1er janvier 2019. La circulaire aborde les bulletins nuls en tant que tels : après les quinze jours de délai de recours, la recommandation est le tri avec cette observation : « Des échantillonnages peuvent être envisagés (pour certains scrutins ou certains bureaux de vote) selon l’intérêt des mentions portées sur les bulletins ». Le texte ne prévoit pas une conservation intégrale des bulletins nuls mais ne l’interdit pas non plus. L’introduction de la circulaire précise que « une conservation plus importante est laissée à l’appréciation des directeurs des services départementaux d’archives ». Ces formulations laissent l’archiviste assez libre de ses choix, selon la teneur même des bulletins certes, mais aussi, selon sa sensibilité, selon son intérêt pour l’histoire politique contemporaine, selon son expérience de tri, selon … (je peux en témoigner personnellement, ayant été en situation d’opérer ce tri il y a quelques décennies). Je serais aujourd’hui curieuse de savoir quel archiviste pratique quelle sélection, et en se posant quelles questions. Au bout du compte, les chercheurs, sociologues, historiens ou autres, trouvent toujours des documents à se mettre sous la main mais je ne peux m’empêcher de penser que c’est un domaine où les ensembles de bulletins nuls qui sont préservés doivent aussi, comme de nombreuses archives, au hasard et la à providence (voir mon billet sur Les archives, fruit du hasard et de la providence).
Il est intéressant de remarquer que la circulaire n’évoque ni le contexte politique ni le taux de participation ni le pourcentage de bulletins nuls ni la prise en compte des tendances de la recherche ni la mise en commun au niveau national des pratiques départementales.
Délai de communicabilitéTroisième et dernière question : au bout de combien de temps ces bulletins nuls sont-ils communicables au public, chercheur ou simple curieux ?
Le soir même des élections, on voit des journalistes, des chercheurs, ou de simples citoyens (tout le monde a le droit d’assister au dépouillement) capturer avec leur smartphone des images de bulletins nuls insolites ou incisifs, images diffusées presque aussitôt dans les médias et sur les réseaux sociaux (notamment Twitter). De là à considérer que les bulletins nuls sont libres d’accès, il n’y a qu’un pas… qu’on pourra franchir mais sans l’appui d’aucun texte réglementaire explicite.
La loi en vigueur sur les archives (code du patrimoine, article L213-1 et 2) dispose que les archives publiques sont communicables de plein droit – dans les conditions définies pour les documents administratifs à l’article L. 311-9 du code des relations entre le public et l’administration – avec évidemment un certain nombre d’exceptions liée à la nature des documents ou à leur contenu : 25 ans (à compter de la date du document ou du document le plus récent inclus dans le dossier) pour les délibérations du gouvernement, les enquêtes fiscales…., 50 ans pour le secret de la défense nationale, 75 ans pour les registres d’état civile et les affaires judiciaires, etc.
Les bulletins nuls n’ayant pas la qualité de documents administratifs, ils ne sont pas visés par le code des relations entre le public et l’administration.
La loi précédente (loi du 3 janvier 1979) précisait dans son article 6 que « Les documents dont la communication était libre avant leur dépôt aux archives publiques continueront d’être communiqués sans restriction d’aucune sorte à toute personne qui en fera la demande ». Mais cette disposition a été supprimée lors de la révision de la loi en 2008. À noter en passant que la circulaire sur le tri des archives électorales citées plus haut ne dit rien sur le sujet de la communicabilité des documents (ce type de circulaire comportait naguère – dans les années 1990 – une colonne « communicabilité » mais cette information a été abandonnée au 21e siècle, sans doute parce que trop sensible ou subtile).
Dans un billet de 2019, intitulé « La communicabilité des documents électoraux », Marie Ranquet fait une précieuse analyse de la réglementation sur la question.
L’article rappelle tout d’abord une disposition du code électoral souvent oubliée en matière de communication : les listes électorales sont communicables à tout électeur ou candidat afin de pouvoir exercer des droits politiques, à condition de ne pas divulguer ces informations dans une démarche commerciale. Logiquement, la liste électorale visée est la liste en vigueur ; les listes étant régulièrement mise à jour, la durée de communicabilité d’une liste donnée n’excède donc pas quelques années, avant de muter vers un délai de communicabilité plus long.
L’accès à la liste d’émargement, (exemplaire de la liste électorale qui permet de savoir qui a voté et qui s’est abstenu) est limité par l’article L. 68 du code électoral dont le 3e alinéa précise : les listes d’émargement déposées à la préfecture ou à la sous-préfecture sont communiquées à tout électeur requérant pendant un délai de dix jours à compter de l’élection et, éventuellement, durant le dépôt des listes entre les deux tours de scrutin, soit à la préfecture ou à la sous-préfecture, soit à la mairie ». Au-delà de ces dix jours, « les listes d’émargement rejoignent le sort des documents couverts par le secret de la vie privée, et ne sont donc communicables qu’après cinquante ans ».
L’article détaille le cas des « documents liés aux opérations de vote », à savoir les procès-verbaux, les procurations et la liste des assesseurs ; il est noté que ces documents relèvent à la fois du régime de communicabilité prévu par le code du patrimoine et le code des relations entre le public et l’administration (aucun délai concret n’est toutefois énoncé pour le dossier électoral). L’aspect qui est mis en avant est la protection de la vie privée, pour les procurations et les listes d’assesseurs, pour lesquelles les adresses personnelles ne doivent pas être communiquées. À la fin du paragraphe sur les listes d’assesseurs qui rappelle que la CADA les considère librement communicables immédiatement, il est ajouté : « Il en va de même pour les bulletins nuls agrafés aux procès-verbaux des opérations de vote ». D’où l’on peut inférer que, vu qu’ils ne comportent pas de données à caractère personnel (même si on peut toujours trouver une exception pour confirmer la règle…), les bulletins nuls sont librement communicables. Mais toujours aucune référence à un texte qui le dirait clairement.
Le centre de gestion de Loire-Atlantique a mis en ligne une fiche intitulée « Communication des documents relatifs aux élections politiques » qui s’appuie sur l’analyse ci-dessus. On y lit que les procès-verbaux des opérations de vote pour les élections législatives deviennent incommunicables après un délai de dix jours. Quant aux bulletins nuls, ils ne sont pas mentionnés…
Le site Internet des Archives départementales du Val d’Oise, dont l’activité dans le domaine de la communication des bulletins nuls est à saluer, comporte une page intitulée « Des urnes aux Archives » ; il est indiqué que les bulletins nuls « font l’objet d’une attention particulière de la part des Archives départementales : les plus insolites – comportant textes, dessins, collage – sont conservés pour la postérité ! », mais rien n’est dit quant à leur délai de communicabilité.
Si les bulletins sont annexés, voire agrafés, au procès-verbal, ne doivent-ils pas suivre la règle qui s’applique au procès-verbal, voire au dossier électoral dans son entier ? J’évoque le dossier électoral car les délais de communicabilité du code du patrimoine visent le plus souvent le dossier (même si la notion de dossier n’y est pas définie).
Si les bulletins nuls sont librement communicables immédiatement, un chercheur peut-il invoquer le code du patrimoine pour exiger des préfectures l’accès aux bulletins nuls non encore versés aux Archives départementales ?
Et si les bulletins nuls sont librement communicables dès le jour de l’élection et qu’on leur fait subir un tri dans les années qui suivent, cela pose la question plus générale des tris et éliminations de documents communicables au public. On peut ainsi imaginer que des photos numériques de bulletins nuls perdurent dans les « archives » de comptes Twitter (privés) de chercheurs ou de journalistes alors même que les originaux correspondants auront été détruits dans les archives publiques. Faut-il s’en émouvoir ?
ConclusionCette réflexion sur les bulletins nuls fait voir que ces documents sont assez représentatifs de plusieurs phénomènes à l’œuvre dans le monde des archives.
Tout d’abord, le poids de l’immédiateté dans la société de l’information. Ce besoin de tout voir tout de suite, de communiquer sans trêve, en continu, une info chassant l’autre. Cette pratique, rendue possible par « l’épanouissement » des réseaux sociaux (les citoyens qui assistaient jadis au dépouillement n’apportaient pas leur appareil photo au bureau de vote, mais tout le monde ou presque va voter avec son smartphone. La vision du temps long, propre aux archives, en prend un coup.
Ensuite, la place que prennent dans le débat public (disons dans l’espace public parce le débat, trop souvent, on le cherche…) les supports d’expression de la population. On l’a vu avec le Grand débat national de 2019 et ses « cahiers citoyens », à la suite des « cahiers de doléances » lancés par certains maires. C’est finalement le même processus avec les bulletins nuls. Les autorités sont à l’initiative d’une consultation (grand débat, élections) qui débouche sur un résultat (proclamation des conclusions, proclamation du nom des élus) mais dont le matériau de base constitue une source de connaissance qui va au-delà de la finalité première des documents, source exploitée au moment même de la production des documents ou en différé, dans une démarche militante ou dans une démarche de recherche.
On pourrait ajouter deux autres évolutions archivistiques qu’illustrent les bulletins nuls. D’un côté, le rôle de l’image, de l’insolite, de la « perle », de la « pépite » dans le monde médiatique et des réseaux. De l’autre, la décontextualisation décomplexée d’un document, pris d’abord pour ce qu’il montre (contenu) et non pour ce qu’il est (trace). C’est sans doute là une manifestation du succès du mot archive au singulier en français, l’objet isolé, vu pour lui-même, avant autre chose…
Ah ! Une dernière question : à quoi ressembleront les bulletins nuls quand le vote sera électronique ?
L’article Les bulletins nuls en questions est apparu en premier sur Le blog de Marie-Anne Chabin.
L’Open data, ce qui a changé depuis Napoléon
L’Open data est une démarche qui a le vent en poupe. Un mouvement à la mode. Une tendance très tendance.
Et tant mieux.
L’expression française correspondante est « données ouvertes » mais force est de constater qu’elle est moins utilisée car sans doute moins explicite, en tout cas plus floue.
L’anglais « data » (qui est autant du latin que de l’anglais) fait ressortir plus rapidement que l’on parle de données numériques, dans la lignée du « big data », « smart data », « data mining »… dont les équivalents français parfois tardifs et discutables (données massives ou mégadonnées, données intelligentes, fouille de données) n’ont pas réussi à s’imposer. Par ailleurs, l’accent aigu de données disparait dans l’écriture désaccentuée des URL, ce qui affaiblit la visibilité du mot. Sans parler de l’utilisation marketing de l’expression anglaise, l’État étant le premier à « montrer l’exemple » avec le site https://www.data.gouv.fr/.
La traduction de « open » par « ouvertes » n’est pas forcément efficace car l’image que l’on associe spontanément à cet adjectif est celui d’une porte ouverte ou d’une personne à l’écoute, image qui ne s’accorde pas de manière évidente à la notion de données numériques. La majorité de la population connaît l’open d’Australie et les « open bars » mais là encore, le lien avec les données numériques ne va pas de soi. Le mot « public » eût peut-être été plus clair, malgré sa propre polysémie. On aurait pu parler de « données publiques », au sens ancien du terme que l’on retrouve dans le mot « Re-publique », à savoir « qui est sous contrôle de l’État, qui appartient à l’État, qui dépend de l’État, qui est géré par l’État » avant que le substantif « le public », c’est-à-dire les gens qui assistent ou sont concernés par quelque chose (le public d’un spectacle, le grand public…), ne s’impose comme sens le plus courant de ce terme.
Résultats des courses: on devrait dire de « données ouvertes » et on dit « open data » (certains écrivent même Open datas » !) (1).
Las, peu importe l’anglicisme, pas dramatique en soi. Ce qui est plus gênant, plus sournois, est que son adoption laisse entendre que cette pratique, une de plus, aurait été inventée aux États-Unis: « Le terme d’open data est apparu pour la première fois en 1995, dans un document d’une agence scientifique américaine »; ou encore « Le terme est apparu pour la première fois dans les années 1970 dans les accords qu’a signés la NASA avec des pays partenaires en vue du partage de données satellitaires ».
Si l’on parle d’un échange international de données scientifiques via le réseau mondial, oui, sans doute, la chose est récente. Mais la politique de mise à disposition des citoyens des données de l’État ou qui concernent la collectivité nationale relève d’une tradition plus ancienne. L’article « Données ouvertes » de Wikipédia mentionne, certes pour le périmètre français, deux dates et deux textes fondateurs de la politique d’ouverture des données / d’accès aux informations publiques :
- 1789: l’article 15 de la Déclaration des Droits de l’Homme et du Citoyen de 1789 dispose que « la société a le droit de demander des comptes à tout agent public de son administration ». Cet article constitue le fondement juridique du droit d’accès aux informations publiques.
- 1978 (les mêmes chiffres mais pas dans le même ordre): plus d’une décennie, c’est vrai, après le Freedom of Information Act, la loi du 17 juillet 1978 relative à l’accès aux documents administratifs reconnaît (timidement mais après deux siècles de silence législatif sur le sujet) le droit d’obtenir communication des documents détenus par une administration, quels que soient leur forme ou leur support.
Il existe plusieurs définitions, sous le vocable « open data » ou sous celui de « données ouvertes », lesquelles définitions laissent voir quelques nuances.
Quelques définitions insistent sur les données elles-mêmes.
« Les données ouvertes sont des données numériques dont l’accès et l’usage sont laissés libres aux usagers, qui peuvent être d’origine privée mais surtout publique, produites notamment par une collectivité ou un établissement public » (définition Wikipédia)
« Données brutes non nominatives et libres de droits, produites ou recueillies par un organisme public ou privé, qui sont accessibles aux citoyens par Internet » (Office québécois de la langue française)
« Les données ouvertes (de l’administration) sont les informations que les organismes publics recueillent, produisent ou achètent (aussi appelées «informations du secteur public») et qui sont mises à disposition gratuitement en vue de les réutiliser à d’autres fins. La licence précise les conditions d’utilisation » (Portail officiel des données européennes)
« Les Open Data, ou données ouvertes, sont des données auxquelles l’accès est totalement public et libre de droit, au même titre que l’exploitation et la réutilisation. Ces données offrent de nombreuses opportunités pour étendre le savoir humain et créer de nouveaux produits et services de qualité » (site LeBigData)
« Les open data sont des données ouvertes qui sont accessible à tous. Elles sont universelles, publiques et réutilisables. Elles permettent aux citoyens d’accéder à plus de transparence sur des sujets variés » (lexique Infonet)
D’autres définitions mettent en avant la démarche politique d’ouverture de ces données.
« L’open data est un mouvement visant à rendre accessibles à tous, via Internet et sans aucune contrepartie, des informations d’intérêt public et général utiles à la communauté » écrit le Journal du net.
L’Open data est un « processus d’ouverture des données publiques ou privées pour les rendre disponibles à l’ensemble de la population sans restriction juridique, technique ou financière » affirme le site Pour l’Éco.
Le site de la CNIL (Commission nationale Informatique et Libertés) définit l’open data comme « un mouvement d’ouverture en ligne des informations détenues par leurs administrations publiques » avec trois objectifs: renforcer la transparence de l’action publique, communiquer au public une image détaillée du territoire, développer le marché de l’information publique. Et la CNIL de préciser: « Ce ne sont donc pas les données en tant que telles qui sont au centre de l’open data mais leur « mise à disposition de tout internaute des informations du secteur public, sous leur forme la moins interprétée (donnée brute) et la plus facilement utilisable (donnée directement exploitable par une machine) ».
Le Vocabulaire de l’informatique et du droit sur Legifrance souligne cette double acception d’open data en distinguant deux traductions françaises et deux définitions (Données ouvertes et Ouverture des données).
Eh oui, open est à la fois un adjectif et un verbe.
Quelle est la nature des données concernées?
On distingue deux grands ensembles de données dans ce qui est mis ainsi à disposition du public, avec une certaine porosité entre les deux, selon les modalités et la finalité de la collecte.
D’un côté, les données relatives à l’action publique de l’administration qui implique, comme acteurs, bénéficiaires ou personnes concernées, les citoyens et plus généralement la population qui vit sur le territoire (ce qui ne se réduit pas, évidemment, à des données à caractère personnel). Ainsi le site gouvernemental https://www.data.gouv.fr/fr/, intitulé « Plateforme ouverte des données publiques françaises » met en avant trois thématiques : les élections, l’emploi, le logement et l’urbanisme. Le site d’Etalab apporte une précision intéressante sur la relation entre documents et données (cf ma série de billets sur le sujet) dans sa définition de « l’open data public »: « Dans le cadre de ses missions de service public, l’administration produit et reçoit des documents administratifs. Ces documents administratifs peuvent contenir des informations publiques, qui peuvent elles-mêmes être représentées sous forme de données publiques ».
De l’autre côté, les données issues de l’observation de la nature et des phénomènes relatifs à l’environnement par de grands établissements publics ou des entreprises privées exerçant de droit ou de fait une activité au service de la collectivité nationale ou internationale, comme les données géographiques, les données énergétiques ou les données satellitaires citées plus haut.
Les annuaires administratifs et statistiques de naguèreDéformation professionnelle, peut-être, quand je suis confrontée à quelque chose supposé être nouveau, je cherche toujours à rattacher cette nouveauté, dépouillée de sa forme matérielle liée aux technologies du temps, à une pratique plus ancienne, afin de mesurer plus aisément la part d’innovation, la part de continuité, la part de la contingence.
Pour ceux qui connaissent l’histoire administrative de la France depuis la Révolution française, cette pratique de publicité des informations publiques (même si on ne les qualifie pas de « données ouvertes ») renvoie l’image des annuaires administratifs et statistiques de la France théoriquement publiés, chaque année, à partir du début du 19e siècle et jusqu’à la Seconde guerre mondiale, dans tous les départements « sous les auspices de M. le préfet et du Conseil général » et disponibles dans chaque mairie. Théoriquement car, contrairement à l’idée reçue d’une uniformité administrative sous les préfets de Napoléon 1er comme sous la IIIe République, et malgré des instructions ministérielles de cadrage, notamment la circulaire du 26 septembre 1844 (2), ces annuaires n’ont pas toujours été produits et présentent des choix éditoriaux qui varient sensiblement d’un département à l’autre, choix qui apparaissent dans les titres, surtout à partir de la seconde moitié du 19e siècle: Annuaire administratif, statistique et historique de l’Eure (1862), Annuaire statistique, historique et administratif du Morbihan (1857), Annuaire historique, statistique, administratif, militaire de la Moselle (1845), Annuaire Administratif, Statistique, Historique, Judiciaire, Agricole et Commercial de la Mayenne (1859), etc. Les différences tiennent aussi aux initiatives des rédacteurs, fonctionnaires ou personnes privées, ainsi qu’aux éditeurs locaux de cette publication territoriale.
 Certes, ces ouvrages imprimés, accessibles via un libraire, n’étaient pas gratuits mais cet aspect ne semble pas avoir été jamais contesté (à vérifier). Et le citoyen pouvait aussi le consulter en mairie ou en bibliothèque.
Certes, ces ouvrages imprimés, accessibles via un libraire, n’étaient pas gratuits mais cet aspect ne semble pas avoir été jamais contesté (à vérifier). Et le citoyen pouvait aussi le consulter en mairie ou en bibliothèque.
Il suffit de feuilleter ces annuaires pour comprendre combien ces « données » administratives, au-delà de la forme et du support papier, font écho aux bases de données accessibles aujourd’hui dans le cadre de l’open data : données statistiques sur la population, données financières, données hospitalières, données territoriales, etc. comme l’illustrent les images ci-dessous.
 Mortalité infantile dans le Pas-de-Calais entre 1806 et 1808 (Annuaire de 1810)
Mortalité infantile dans le Pas-de-Calais entre 1806 et 1808 (Annuaire de 1810)
 Dépenses départementales présentées lors de la séance du conseil général des Ardennes du 2 septembre 1849 (Annuaire de 1850)
Dépenses départementales présentées lors de la séance du conseil général des Ardennes du 2 septembre 1849 (Annuaire de 1850)
 Mouvement des malades civils à l’hôtel-Dieu de Troyes (1829-1834) – Annuaire départemental de l’Aube 1835
Mouvement des malades civils à l’hôtel-Dieu de Troyes (1829-1834) – Annuaire départemental de l’Aube 1835
Nomenclature des communes des Ardennes avec, dans la dernière colonne, la contenance du territoire communal (Annuaire de 1850)
 Longueur des routes départementales de l’Ain (Annuaire 1876)
Longueur des routes départementales de l’Ain (Annuaire 1876)
 Production de vin en Saône-et-Loire de 1896 à 1921 (Annuaire 1922)
Production de vin en Saône-et-Loire de 1896 à 1921 (Annuaire 1922)
Ces annuaires ont été très utilisés tout au long du 19e siècle et pendant la première moitié du 20e siècle avant d’être peu à peu délaissés. Les services d’archives départementaux et municipaux, ainsi que la Bibliothèque nationale, en conservent en général une ou plusieurs collections. Certaines ont été numérisées, d’autres pas (encore), avec des niveaux de qualité variable comme le prouvent les images ci-dessus pour l’Ain, les Ardennes, l’Aube, le Pas-de-Calais et la Saône-et-Loire. Ces collections présentent malheureusement des lacunes. Consolation, on en trouve sur les sites de livres anciens, par exemple l’annuaire du département de l’Eure pour 1862 à 8,5 € en PDF, moins cher qu’un paquet de cigarettes !
Quelle évolution en deux siècles?Je reviens à la question exprimée dans le titre de ce billet: qu’est-ce qui a changé dans l’accès aux données publiques depuis deux siècles?
La comparaison de ces collections d’annuaires (représentatifs d’un panel de publications administratives plus varié sur la période) avec les jeux de données dénommés aujourd’hui données ouvertes met d’abord en avant le rôle majeur des technologies dans la production des données et dans l’accès à l’information. Les progrès technologiques ont tout d’abord permis de décrire de plus en plus de réalités, non seulement les décisions des organisations ou les faits observables à l’œil humain mais aussi les phénomènes environnementaux ou scientifiques accessibles uniquement par le truchement d’outils de plus en plus sophistiqués et précis. Il en ressort une explosion de données, souvent très fines, autorisant des analyses et des exploitations toujours plus poussées. Par ailleurs, les capacités de traitement et de visualisation dont on dispose aujourd’hui n’ont plus rien à voir avec les pages imprimées d’antan; les austères tableaux de mortalité du 19e siècle n’ont plus grand-chose à voir avec les infographies et animations qui présentent aujourd’hui les mêmes types de données. Et surtout, la création d’un réseau planétaire a permis d’accéder à ces gisements d’information de n’importe où dans le monde, sans se déplacer, par le biais d’un simple ordinateur.
Voilà pour les plus. Mais il y a aussi les moins.
En effet, il est étonnant que, malgré cette progression technologique, la construction de grandes bases de données publiques se révèle finalement tardive et parfois poussive. On note ainsi, comme pondération des progrès technologiques, un aspect négatif de cette évolution biséculaire: c’est le manque de recul dans la production parfois tâtonnante ou anarchique des collections d’aujourd’hui. Comme s’il avait fallu tout réinventer depuis quelques décennies: les principes de l’accès à l’information, les méthodes de description et de présentation des données, le droit des populations à l’information publique, les pratiques de partage et d’exploitation des biens communs. Autant réinventer la poudre peut avoir du bon au plan individuel, autant une société évoluée devrait s’appuyer sur son expérience passée et ses connaissances collectives pour faire à la fois plus vite et mieux. On peut voir dans cette course aux données ouvertes depuis une dizaine d’années une illustration du règne de la donnée ignorante du passé, de l’histoire, des archives. Le manque de recul global est sans doute également imputable à la multiplicité des acteurs et des initiatives, mais ce qui pourrait être un ferment de qualité s’avère pénible quand ce sont le manque de recul et le défaut de culture qui sont démultipliés, plutôt que l’imagination et la sagacité.
À la décharge des oublieux du passé, il faut bien reconnaître l’impact d’un demi-siècle d’oubli des annuaires administratifs, passés de mode et délaissés par les historiens, même si le service de la Documentation française a continué à proposer des ouvrages statistiques aux lecteurs intéressés.
Pourquoi de si bonnes pratiques administratives ont été peu à peu abandonnées au lendemain de la Seconde guerre mondiale ? Faut-il incriminer la charge de travail administrative, la perte d’un savoir-faire, la démission des acteurs compétents, le goût du secret des responsables politiques et administratifs, le manque de considération pour le public ou encore le manque d’intérêt des citoyens pour ces informations publiques depuis un demi-siècle ?
En tout cas, il est amusant de cartographier les données mises actuellement à disposition du public. Sans vouloir faire du mauvais esprit, j’ai retenu de ma promenade sur la toile que l’internaute pouvait accéder d’un clic à la liste des objets trouvés dans les trains français depuis 2013 (ainsi que la liste des déclarations d’objets perdus) mais je n’ai pas trouvé la liste des contrats signés par le gouvernement avec les laboratoires pharmaceutiques. Bizarre.
Il faut dire que l’article 15 de la déclaration des droits de l’homme et du citoyen en faveur de la transparence administrative était lui-même relativement tombé dans l’oubli pendant les Trente Glorieuses, y compris chez les chercheurs et les archivistes, avant de connaître un regain d’intérêt à la fin du 20e siècle. Peut-être faut-il, dirait le philosophe, que tout meurt pour que tout renaisse…
Et les archives dans tout ça?Eh bien, peu de choses à dire.
La grande majorité des données ouvertes sont des archives publiques au sens le plus strict et le plus traditionnel, en droit et en archivistique.
C’est évident.
Mais cela ne semble pas évident pour tout le monde.
Même si la plupart des archivistes avec qui j’ai évoqué le sujet en conviennent sans hésiter, les responsables des bases de données de « l’open data » en France ne font apparemment pas le lien entre archives publiques et données ouvertes. J’en veux pour preuve ce support de formation élaboré par Datactivist à destination d’archivistes en 2022 qui n’évoque absolument pas les origines de la notion de publicité et de publication des documents administratifs publics au cours des derniers siècles ni même des dernières décennies.
Il y a là une perte de savoir à tous les niveaux. Et une perte de pouvoir aussi. À tous les niveaux également.
Curieux.
Notes
(1): Par exemple dans cette URL: https://adequation.fr/actualites-et-ressources/open-datas/. Cela dit, on s’habitue à tout à force de l’entendre et, à cette heure, je me dis qu’un jour, à force de voir un « s » ajouté à « data » par certains auteurs peu soucieux du génie des langues (datas, et pourquoi pas datasses tant qu’on y est ?), je finirai par m’y habituer. Il y a bien d’autres exemples dans la langue française d’orthographes plus fantaisistes que cela (le homard; la châsse, la glande lacrymale, etc.) que les défenseurs extrêmes de la langue française veulent absolument préserver. Bref.
(2) Voir la thèse de doctorat de Julie Lauvernier, « Classer et inventorier au XIXe siècle Administration des fonds et écriture de l’histoire locale dijonnaise par l’archiviste Joseph-François Garnier (1815-1903) », 2012, pp 144-147
L’article L’Open data, ce qui a changé depuis Napoléon est apparu en premier sur Le blog de Marie-Anne Chabin.
15 avril 2019
J’ai un très vif souvenir du début de soirée du 15 avril 2019, il y a juste trois ans.
Je me hâtais de terminer ce que j’avais à faire avant 20h pour écouter l’allocution radiotélévisée du président de la République qui devait présenter à la nation les résultats du Grand Débat National qu’il avait lui-même lancé quatre mois plus tôt en réponse au mouvement des Gilets jaunes.
Mais l’incendie de Notre-Dame en a décidé autrement.
Mêlée aux badauds le long des quais de la Seine, tandis que les sirènes des camions de pompiers fusaient au milieu des chaussées complètement embouteillées, j’ai observé les réactions des Parisiens et des touristes: stupeur, tristesse, crainte d’un attentat. Viendront peu après les élans de générosité pour réparer et reconstruire, mais aussi les interprétations complotistes (une statue monumentale de saint Denis s’est transformée pour l’occasion en incendiaire qui court sur les toits de la cathédrale…).
L’allocution du président de la République a été reportée puis oubliée. La conférence de presse qui devait avoir lieu deux jours plus tard s’est finalement tenue le 25 avril 2019 mais l’attention des médias et du public s’était déjà déplacée vers la cathédrale de Paris.
Une actu chasse l’autre, c’est la règle.
Dans quelles proportions l’incendie de Notre-Dame de Paris aura-t-il nuit à la publicité du Grand Débat qui s’est achevée deux mois plus tard, en juin, en jus de boudin et qui n’intéresse plus aujourd’hui hélas que quelques chercheurs ?
Les GAFAM et leurs adeptes
Aujourd’hui on est stigmatisé quand on fume du tabac, qui abime le corps. Mais on est encouragé à se shooter aux GAFAM, qui abiment l’esprit.
Les GAFAM sont là. Google, Apple, Facebook, Amazon et Microsoft.
Ils font partie du paysage, ou plutôt ils se fondent dans le paysage. Ils font partie du quotidien, comme les panneaux de la circulation, les champs de maïs, les rayons du supermarché, les cailloux dans la chaussure, les autobus, les autoroutes, les autotests…
Le développement des petites entreprises de Palo Alto and Co ont fait leur grand chemin. Elles sont devenues planétaires et tentaculaires. Au point que les inventeurs de l’Internet ne reconnaissent plus leur création et soulignent aujourd’hui ses dérives (notamment Tim Berner Lee en 2019). Et que les articles qui dénoncent la mainmise des géants du Web sur la vie des Terriens se multiplient. Par exemple:
« Les GAFA au bord du gouffre de la haine« , Jean-Marc Vittori (Les Echos, juillet 2019)
« Les GAFAM sont comparables aux grandes propriétés qui ont bouleversé l’équilibre social de la Rome antique« , Philippe Fabry (Le Figaro, avril 2020)
« Données personnelles : ce que les Gafam savent sur vous« , Léonor Lumineau (Capital, janvier 2021)
« Les Gafa ont opéré un coup d’État numérique« , Shoshana Zuboff (Courrier international, mars 2021, article original dans le New York Times: The Coup We Are Note Talking About)
« Infographie : des GAFA plus puissants que jamais« , Alexandre Piquard (Le Monde, mars 2022)
Le constat, sans appel, est que la très grande majorité de la population est accro aux GAFAM.

J’ai moi aussi cédé un temps aux voies mielleuses des sirènes gafamiques. Mais heureusement, tel Ulysse, je me suis mis des bouchons dans les oreilles pour de pas trop dévier de mon cap (l’esprit libre, ou encore mens sana in copore sano).
Google, pour commencer par le commencement. C’est formidable, séduisant, efficace. Je parle du moteur de recherche et de sa surpuissance. Évidemment, j’ai testé les concurrents qui ne sont pas si mauvais et qu’il faut encourager (vive la diversité) mais j’avoue céder régulièrement un numéro 1 de la recherche par souci d’efficacité. Mais ce n’est pas tous les jours.
La messagerie Gmail est un sujet à part entière dont on parle beaucoup moins. Que l’accès aux données publiques d’Internet soit canalisé par Google est une chose. Que les échanges privés que sont les messages électroniques soient majoritairement hébergés par Google en est une autre. Par exemple, j’ai observé depuis plusieurs années que si 100% de mes collègues à l’université ont une adresse @université, 50% de mes collègues à l’université (les mêmes donc) utilisent au quotidien une adresse perso @gmail, même pour parler des difficultés d’un étudiant ou de sujets délicats concernant la vie professionnelle. Et quand je signale cela, dans une conversation entre collègues ou dans un colloque, mes propos n’ont quasiment aucun écho. Comme si je parlais d’un sujet tout à fait banal. Tant pis, j’en parle quand même. Je refuse quant à moi à utiliser Gmail, quoi qu’il m’en coûte (problème d’accès aux contenus de certains liens).
Apple. Je ne peux en dire grand-chose car malgré mes initiales qui me prédestinaient sans doute à utiliser un Mac plutôt qu’un PC, je ne connais Apple que très peu et surtout de l’extérieur. Apple m’a toujours fait penser à une secte et Steve Jobs à un gourou. Ce qui ne m’empêche pas de discuter avec des adeptes appeliens-liennes, par curiosité et par amitié.
Facebook. Le réseau « historique » vieillit et ne séduit plus la jeunesse mais il y a WhatsApp, et le métavers qui vient. Là, mon expérience directe est encore plus limitée que pour Apple car je n’ai jamais eu de compte Facebook. Je n’ai d’ailleurs jamais été tentée d’en créer un et tant mieux (cela m’a évité de le supprimer). J’ai tout de même lu attentivement les CGU de Facebook en 2013: l’imbroglio que j’y ai lu a fonctionné comme un répulsif.
Il y a des gens qui ont résisté un temps puis fini par céder et ouvrir leur compte, avant d’être horrifiés par cet outil addictif (bien pire que de fumer un cigare de temps en temps). Je m’amuse surtout de lire les déclarations d’influenceurs qui ont atteints quelques dizaines de milliers de followers et qui, soudain réveillés et dégoûtés de la vanité de la chose, ferment tout et s’en vont élever leurs chèvres dans un hameau reculé d’Auvergne ou de Franche-Comté.
La place de Facebook dans la vie publique est impressionnante. Je me suis émue récemment de la mainmise de Facebook sur la communication des mairies. Mais ce n’est rien à côté des sites officiels (DGFiP en tête) qui vous invitent à les retrouver sur Facebook. On est tellement incité à tout bout de champ à présenter son « pass Facebook » qu’il faut vraiment le vouloir pour ne pas « signer ».
Amazon. L’entreprise en impose. C’est tentant, of course. Pour ma part, j’avoue avoir été séduite par les services proposés par Amazon en 2013: je cherchais un livre assez rare, Amazon me le dépose dans ma boîte aux lettres dans les 48 h. Cool! J’ai pratiqué quelques mois avant d’être dégrisée par un lot de notifications très déplaisantes (je n’avais peut-être pas donné au système assez de données personnelles pour avoir des notifications mieux ciblées…); il m’est tout d’un coup apparu que Big Amazon avait les yeux fixés sur moi, sans être vraiment mon frère… Sensation d’intrusion, voire d’agression. J’ai stoppé net, sans difficulté (je reconnais ne pas avoir été harcelée par la suite, c’est bien) et je me suis organisée autrement; il faut un peu de patiente et un peu d’imagination mais on arrive globalement au même résultat. Depuis, Amazon n’est pour moi qu’une réalité lointaine, un joli logo sur des cartons qui traînent ça et un sujet d’actualité économico-sociale parmi d’autres. Prouesse d’Amazon rime avec paresse du client. Tristesse.
Microsoft. Là, j’avoue, je pratique. Parce que, sauf à se retirer du monde, on doit composer avec les outils de la société. J’ai donc choisi le M que l’on ajoute aujourd’hui à GAFA, avec un usage modéré et, j’espère, maîtrisé. Refuser toute compagnie de l’Internet, ce serait comme refuser d’emprunter les routes asphaltées pour se déplacer (après avoir contribuer par ses impôts à payer le macadam). Cela limiterait sensiblement l’interaction sociale, professionnelle, familiale. J’ai observé depuis trente ans la force tranquille de l’entreprise de Bill Gates, jusqu’à devenir le fournisseur dominant dans un très grand nombre d’organisations, ce qui rend vains de nombreux projets d’équipement logiciel diversifié car il faut être Microsoft compatible, autrement dit tout Microsoft ou presque. Le choix peut être cornélien. On le fait, ou non. Et puis Microsoft, c’est aussi LinkedIn que j’utilise quotidiennement, pour dénoncer les travers et les contradictions de notre société de l’information.
Je parle des GAFAM mais il y a aussi Twitter, les NATU (Netflix, Airbnb, Tesla et Uber), les réseaux chinois, etc.
 Clairement, Internet n’a pas tenu ses promesses. Ou plutôt – car Internet n’est rien d’autre que ce que les humains en ont fait – certains en ont laissé d’autres accaparer la merveilleuse technologie.
Clairement, Internet n’a pas tenu ses promesses. Ou plutôt – car Internet n’est rien d’autre que ce que les humains en ont fait – certains en ont laissé d’autres accaparer la merveilleuse technologie.
Mais mon propos n’est pas de critiquer la liberté de tout un chacun de fréquenter les GAFAM, d’y consacrer son temps, de les adorer, de leur donner toutes ses données, voire de se faire e-tondre en chantant. Comme dit la chanson, chacun fait fait fait ce qui lui plaît plaît plaît.
La question est celle de la cohérence du comportement des internautes. Car on ne peut valablement dénoncer la stratégie monopolistique de ces entreprises internationales de l’Internet et se complaire en offrandes quotidiennes aux nouveaux dieux de l’information, ces compagnies plus puissantes que les États et qui, de surcroît se moquent de la vie des gens comme de leur première chemise.
Des adeptes de la souveraineté politique échangent sur WhatsApp qui est la propriété de Meta (plus connu sous le nom de Facebook) avec une vague conscience d’alimenter les GAFAM mais, tout de même, c’est pratique, pour voir les photos des enfants, les blagues, les amis, et tutti quanti.
Parmi ceux qui manifestent contre le pouvoir en place et pour plus de justice économique et sociale, par exemple les Gilets Jaunes, certains se regroupent sur Facebook pour discuter et s’organiser.
Etc.
Il y a là une contradiction.
À quoi tient cette contradiction?
À l’ignorance? Les gens n’ont pas conscience d’alimenter le système qu’ils dénoncent par ailleurs? Alors, il est grand temps de se former. Internet, si tendancieux soit-il devenu, offre quand même pas mal de sources pertinentes à l’internaute un tant soit peu curieux. Et tant pis si, pour la formation à l’environnement numérique, les pouvoirs publics jugent plus important d’apprendre le code aux enfants des écoles, plutôt que de leur enseigner le fonctionnement du système : qu’est-ce que le numérique? Qu’est-ce qu’un réseau ? Qu’est-ce qu’un serveur, un datacenter, un câble sous-marin qui achemine les données? Qu’est-ce qu’un fournisseur d’accès? Etc.
Et si ce comportement contradictoire est conscient et délibéré, alors, cela fait perdre à celui qui revendique une bonne part de sa crédibilité, et dénote un comportement ambigu.
Rendre un culte aux GAFAM pour soi, parce que c’est pratique, parce que c’est facile, a quelque chose d’égoïste car c’est aussi accepter une certaine politique de l’information pour tous, c’est laisser s’installer des super-règles de vie qui s’infiltrent et adhèrent au quotidien: ce qu’on peut dire, ce qu’on doit taire, comment on doit faire, etc., « on » étant l’ensemble de la population prise dans les filets des GAFAM qui font de l’Internet une grande cour de récré surveillée par quelques grands manitous (pour ne pas dire une cour de prison, cf les discours sur la servitude volontaire mais c’est bien ce dont il s’agit).
Mais que faire ?
Beaucoup pensent que la situation est inéluctable car ils croient qu’il faut être un expert en informatique pour faire autre chose que ce que les médias disent de faire…
Ce n’est pas vrai. Il y a mille choses à faire. « Changer le monde un octet à la fois » : c’est la proposition, argumentée, de l’association Framasoft qui milite contre les GAFA dans de nombreux domaines et avec de nombreux outils pour la décentralisation du Web, et le monde du logiciel libre. Voir aussi le site Degooglisons Internet.
Tout d’abord, on peut contrôler la production et le stockage de ses données (ce que l’on exprime) et de ses données personnelles (ce qui est enregistré, par soi au d’autres, sur soi). Oui, cela demande un peu de volonté et de discipline mais ce n’est pas si compliqué. Chacun sait maintenant qu’il faut réfléchir avant d’écrire n’importe quoi n’importe où car tout est enregistré et on perd la main sur le devenir de ces données, sauf à se lancer dans des procès chronophages comme le valeureux Max Schrems. Mais aussi choisir et surveiller ses fournisseurs d’accès Internet et de messagerie, lire les conditions générales d’utilisation, prendre le temps de paramétrer les outils (ça s’apprend!) et demander des comptes à ses fournisseurs.
 Comment se fait-il que si peu de citoyens aient profité de la démocratisation de la messagerie électronique à la fin du XXe siècle ou au début du XXIe pour créer leur propre nom de domaine, leur nom de famille par exemple (www.dupontel.fr) ou nom de famille + commune (www.duponteldesaintmartin.fr) ? La démarche est pourtant assez simple : vérifier la disponibilité du nom auprès de l’Afnic (cela prend dix minutes) et choisir un hébergeur, local si possible, pour le stockage des données (si on crée un site) et la gestion des adresses mails associées (minou@dupontel.fr, jojo@duponteldesaintmartin.fr, etc.). Il en coûte entre 20 et 30 euros par an pour une activité restreinte, moins qu’une seule nuit d’hôtel et on est chez soi toute l’année !
Comment se fait-il que si peu de citoyens aient profité de la démocratisation de la messagerie électronique à la fin du XXe siècle ou au début du XXIe pour créer leur propre nom de domaine, leur nom de famille par exemple (www.dupontel.fr) ou nom de famille + commune (www.duponteldesaintmartin.fr) ? La démarche est pourtant assez simple : vérifier la disponibilité du nom auprès de l’Afnic (cela prend dix minutes) et choisir un hébergeur, local si possible, pour le stockage des données (si on crée un site) et la gestion des adresses mails associées (minou@dupontel.fr, jojo@duponteldesaintmartin.fr, etc.). Il en coûte entre 20 et 30 euros par an pour une activité restreinte, moins qu’une seule nuit d’hôtel et on est chez soi toute l’année !
Être propriétaire d’un nom de domaine Internet n’empêche pas de s’exprimer sur les réseaux sociaux, mais il y a une différence entre s’exprimer directement sur un réseau et s’exprimer sur une page personnelle ou un blog (dont on gère le domaine) puis partager cette page sur un réseau social. La différence, c’est la maîtrise du stockage et de tout ce qui va avec, c’est-à-dire la conservation et/ou destruction, l’accès et la cybersécurité.
Ensuite, ceux et celles qui pensent que la gafaïsation de la société n’est pas souhaitable devraient dénoncer les incitations de plus en plus prégnantes de la part des entreprises de commerce (mais aussi de la part des institutions qui se comportent trop souvent comme des serviteurs zélés des GAFAM), incitations donc à être facebookien, amazonien, gmailien, etc. Mais cela demande encore plus de volonté, voire un engagement militant. Comme pour le réchauffement de la planète, on pense volontiers que ce n’est pas si grave et on attend de voir alors qu’il est déjà bien tard pour protéger efficacement la nouvelle génération… Comme d’hab, il faut attendre que le supermarché du canton soit en grève ou fermé exceptionnellement pour découvrir que son voisin propose depuis des années les légumes de son jardin au marché du coin. Il faut attendre l’accident mortel au carrefour pour qu’on se décide à installer un stop.
Je m’étonnais plus haut que la moitié des gens utilisent une adresse Gmail sans que cela n’émeuve personne. Je vois venir le jour, hélas, où l’adresse Gmail sera obligatoire, y compris dans l’administration française… Les mauvais jours, je me dis que j’espère mourir avant ! Les bons jours, je suis tentée par l’expérience de refuser tout échange avec une adresse Gmail; ce serait marrant.
Ce billet est une invitation à résister aux assauts des géants du web pour piloter nos vies via nos données. En langage de crise sanitaire maintenant bien connu, je dirais qu’il faut appliquer les gestes barrières face à la dépendance numérique, pour se protéger et pour protéger les autres.
___
Pour finir par une provocation (on ne se refait pas), je me demande si on ne devrait pas mettre à jour l’insulte-culte de Gabin-Grangil dans La Traversée de Paris et parler de « Salauds d’internautes »…
L’article Les GAFAM et leurs adeptes est apparu en premier sur Le blog de Marie-Anne Chabin.
Mark Zuckerberg, porte-parole de la moitié des maires de France
Ce n’est pas une fake news!
Juste une reformulation caricaturale d’une réalité que chacun peut constater.
 Une part notable des communes françaises (et bien d’autres institutions publiques également) a choisi de communiquer via les réseaux sociaux, et plus spécifiquement Facebook. « Malgré l’émergence récente de réseaux concurrents, l’emprise de Facebook confine à une telle situation de quasi-monopole que les collectivités locales l’ont désormais intégré à leur stratégie de communication« , pouvait-on lire dans le Journal des maires déjà en 2017.
Une part notable des communes françaises (et bien d’autres institutions publiques également) a choisi de communiquer via les réseaux sociaux, et plus spécifiquement Facebook. « Malgré l’émergence récente de réseaux concurrents, l’emprise de Facebook confine à une telle situation de quasi-monopole que les collectivités locales l’ont désormais intégré à leur stratégie de communication« , pouvait-on lire dans le Journal des maires déjà en 2017.
Il n’y a pas lieu de s’en étonner quand on sait que le ministère de l’Intérieur, « patron » des collectivités locales, incitait dès 2014 les préfectures à « investir » le réseau social au travers d’un Guide Facebook.
On pourra m’objecter que mon billet vient un peu tard et qu’il n’est pas vraiment d’actualité, entre la perte de vitesse de Facebook dans la compétition des réseaux sociaux aujourd’hui, l’avènement du Métavers qui change les perspectives ou la menace de Zuckerberg de quitter l’Europe proférée début février 2022, mais justement, c’est le moment de faire le point sur la valeur des données collectées et stockées par Facebook, en l’occurrence les données relatives à la vie communale.
Combien de communes sont concernées?
L’article de Ludovic Galtier « Comment les réseaux sociaux transforment la relation maire-citoyen » (avril 2019) cite les chiffres de l’Observatoire social media des territoires pour 2018: 9 % seulement des communes de moins de 10 000 habitants présentes sur les réseaux sociaux en 2018 (contre 70 % des communes de 10 000 à 20 000 habitants).
On imagine une progression de ces chiffres depuis 2018, surtout avec la multiplication des « échanges dématérialisés » induits par la crise sanitaire du Covid-19.
Il serait intéressant d’avoir des statistiques plus précises et, outre la taille des communes, de connaître celles qui ont à la fois un site Internet et une page Facebook, celles qui n’ont que l’un ou l’autre, celles qui n’ont rien. Intéressant aussi de savoir si les communes facebookiennes ont également un groupe Facebook en plus de la page « institutionnelle », si elles disposent d’autres comptes sur d’autres réseaux sociaux, si les élus ont leurs propres comptes, etc.
Mais même sans données statistiques plus pointues, le phénomène est là et mérite attention.
Plusieurs sites abordent la question de l’intérêt de créer une page Facebook pour une commune par exemple ici.
Les arguments visent la politique de communication de la commune, les fonctionnalités du réseau, sa « gratuité », la facilité d’utilisation, les ressources pour l’animation. Très bien. En revanche, le principe de la sous-traitance de la diffusion du discours d’une collectivité à une entreprise privée internationale (en l’occurrence Facebook) n’est pas abordé. C’est ce principe qui est au cœur de ce billet, avec deux questions:
- les élus locaux et les populations ont-ils conscience de déléguer à Facebook le soin de la diffusion du discours public?
- quelles conséquences de cette sous-traitance pour la conservation de la mémoire collective?
Il convient de distinguer, pour une commune donnée, la page « officielle » sur Facebook et les groupes Facebook. Ils n’engagent pas au même niveau.
La page dite « officielle » (les mots sont performatifs…) diffuse les informations sur la collectivité que la mairie doit ou veut adresser à la population concernée. Cette page au mieux double, au pire se substitue au site Internet de la mairie ou encore au bulletin municipal. C’est un discours unidirectionnel des responsables de la collectivité vers les administrés, avec une dimension engageante de la parole publique. Les groupes, eux, permettent l’interaction, les discussions et tiennent à la fois de la conversation spontanée au café du Commerce et des rencontres associatives.
On pourrait définir la page « officielle » comme la transposition technologique du système de naguère composé d’une part d’un affichage dans les locaux de la mairie, d’autre part des annonces faites par le garde-champêtre dans les différents quartiers et hameaux à l’aide de son porte-voix.
La comparaison avec le garde-champêtre exige de pointer les différences. J’en soulignerai deux:
- la tournée du garde-champêtre a pour objectif de porter l’information à toute la population concernée là où elle vit; alors que la page Facebook incite les habitants à aller s’informer à l’extérieur du territoire communal. Certes, on peut accéder à la page « officielle » sans compte Facebook (ce qui est mon cas) mais le non-facebookien subit ce sentiment de ne pas être un citoyen à part entière puisqu’une série de pop-up l’incitent à se connecter au réseau et à accepter la politique des cookies du Gafam, une façon de culpabiliser et de marginaliser ceux qui n’ont pas encore « signé là où on leur dit de signer ».
- le garde-champêtre est un employé municipal; Facebook est un prestataire (pas un service public!). D’accord, il fait le job de mettre en ligne les informations communales. Mais, contrairement au garde-champêtre qui reçoit un salaire de la commune, le réseau social est « gratuit », ce qui veut dire qu’il se paie autrement, notamment en capitalisant et en exploitant les données associées au fonctionnement de la page.
 En exagérant – bien sûr – cela me fait songer aux contes ancestraux où le personnage principal, pressé de jouir d’un bien qu’il convoite sans pouvoir se l’offrir, cède à la proposition d’un mauvais génie d’en disposer immédiatement et gratuitement, ou presque, juste un abandon de sa personnalité ou de sa volonté (au diable l’avenir!).
En exagérant – bien sûr – cela me fait songer aux contes ancestraux où le personnage principal, pressé de jouir d’un bien qu’il convoite sans pouvoir se l’offrir, cède à la proposition d’un mauvais génie d’en disposer immédiatement et gratuitement, ou presque, juste un abandon de sa personnalité ou de sa volonté (au diable l’avenir!).
Car la gratuité, ça se paie!
Les élus municipaux concernés ont-ils conscience de cette privatisation du discours public?
Il est peut-être temps d’inscrire le coût des données et de leur aliénation dans le budget communal…
Quid de l’avenir des données communales sur Facebook?La seconde question qui découle de la première est le devenir des données communales confiées à la gestion de Facebook. J’entends par « données communales » les informations formulées au nom de la commune et qui font donc partie de la mémoire de la collectivité, en toute logique comme aux termes de la loi sur les archives (code du patrimoine).
La disparition de ces pages hébergées et gérées par Facebook entraînera une disparition des contenus et des visuels qui ne sont pas sauvegardés ailleurs. Est-ce grave? Non, il y a bien d’autres destructions d’archives communales quotidiennes et inconscientes, mais cet abandon habitue insidieusement à un rétrécissement de la mémoire communale.
La question est plus généralement celle de l’archivage des réseaux sociaux. Pour les conversations de café du Commerce, la destruction des données ne serait pas une grande perte et le risque est plutôt le mésusage des données (cette dimension-là est un peu mieux perçue dans la société). Mais pour les informations qui engagent la collectivité, il faut être irresponsable pour ne pas se poser la question de la souveraineté des données essentielles de son institution ou de son entreprise (domaine du records management) et de la constitution d’une mémoire collective contrôlée par les intéressés (domaine de la politique patrimoniale).
Je suis surprise que ce sujet ne préoccupe pas davantage les archivistes. Il est vrai que la pratique courante consistant à ne transférer aux « Archives » que les « tas » visibles accumulés en local depuis cinq ou dix ans (en papier ou en numérique) est bien installée et noie le poisson.
_________
Finalement, pourquoi écrire sur ces sujets mineurs (les traces écrites de la démocratie locale, c’est mineur, non?)?. C’est comme de faire remarquer que pour avoir connaissance de certaines décisions du président de la République, il faut le suivre sur Twitter ? Allez, circulez, y a pas de sujet, y a rien à voir!
L’article Mark Zuckerberg, porte-parole de la moitié des maires de France est apparu en premier sur Le blog de Marie-Anne Chabin.
Bureaucratie et données à caractère personnel
La bureaucratie, tout le monde s’en plaint mais tout le monde y contribue. Et la bête ne fait que grossir.
Cette fois, j’ai dit non, histoire de me remonter le moral, ou de me donner l’illusion que je peux lutter contre le mammouth (ce qui revient un peu au même).
À la fin de l’année 2018, je suis intervenue dans une formation d’un établissement d’enseignement supérieur, à la demande du responsable d’un parcours universitaire, pour une conférence de trois heures, devant être rémunérées sous forme de vacations. Le jour de mon intervention, les modalités administratives n’étaient pas réglées mais ma démarche était d’abord pédagogique.
 Un mois plus tard, je reçois les formulaires à remplir pour constituer mon dossier vacataire, condition sine qua non de tout paiement. Devant le nombre de papiers à remplir en répétant les mêmes informations, le nombre et la nature des pièces justificatives à joindre, la perspective d’une expédition au bureau de Poste, mes forces m’abandonnent. Je calcule que si je défalque ce que me coûte de ce pensum (temps passé que, dans un emploi du temps très chargé, je pourrais consacrer à une autre tâche plus valorisante) de ce que me rapportent ces trois heures de vacations (moins les charges et les impôts), il ne reste pas grand-chose. Je renonce et j’informe le service que j’abandonne l’affaire. Dossier clos.
Un mois plus tard, je reçois les formulaires à remplir pour constituer mon dossier vacataire, condition sine qua non de tout paiement. Devant le nombre de papiers à remplir en répétant les mêmes informations, le nombre et la nature des pièces justificatives à joindre, la perspective d’une expédition au bureau de Poste, mes forces m’abandonnent. Je calcule que si je défalque ce que me coûte de ce pensum (temps passé que, dans un emploi du temps très chargé, je pourrais consacrer à une autre tâche plus valorisante) de ce que me rapportent ces trois heures de vacations (moins les charges et les impôts), il ne reste pas grand-chose. Je renonce et j’informe le service que j’abandonne l’affaire. Dossier clos.
Non. Trois ans plus tard, un autre fonctionnaire me relance. On me demande de remplir et d’envoyer le dossier par mail, alors que les formulaires à renseigner portent en pied de page la mention en lettres rouges « Ce document doit obligatoirement être transmis en original au CSP RH (scan ou copie non acceptés). Il est vrai que la crise sanitaire est passée par là et le virus a tué le slogan farouche « seul le papier fait foi » (il était en effet beaucoup trop vieux et souffrait de comorbidités diplomatiques patentes).
Au sujet de la bureaucratie, je me demande si la Cour des comptes s’est déjà penchée sur le coût de la gestion des enseignants-vacataires et les améliorations que l’on pourrait apporter au système dans l’intérêt des contribuables, des fonctionnaires et des enseignants. J’entends bien qu’il faut 1) collecter un minimum de données sur une personne pour la rémunérer d’un service rendu, et 2) contrôler les abus de la formule car tout dispositif de financement public a ses détourneurs et ses profiteurs. Mais qui peut croire que la réponse à ces deux bonnes questions soit toujours plus de paperasse (ou d’électronasse, ce qui est pire)? La remarque vaut d’ailleurs pour d’autres dispositifs de l’administration française relatifs à des sommes modestes dont la gestion coûte plus cher que les montants distribués. Cela me rappelle le système complexe d’affranchissement du courrier au milieu du 19e siècle quand le prix du timbre-poste était savamment calculé en fonction de la distance parcourue, parfois au kilomètre près, jusqu’à ce que les États établissent des tarifs forfaitaires selon quelques grands cas figure (national / international, tranches de poids, etc.). Ne pourrait-on imaginer un forfait selon le nombre de vacations (par tranche), avec une base de données minimales centralisées des vacataires permettant de contrôler le système et éviter les abus ? Et faire un peu plus confiance aux responsables de formation ? Bref, une gestion a posteriori plutôt qu’a priori. Tout le monde y gagnerait.
Ce n’est pas tout. Non seulement cette machine administrative de constitution de dossiers d’enseignants-vacataires est une élève zélée de la bureaucratie française mais elle est en plus peu conforme au Règlement général pour la protection des données personnelles (RGPD).
Il est en effet assez effarant de voir le nombre de données réclamées pour être indemnisé de partager son savoir avec des étudiants !
Par exemple, pour un salarié du privé, la procédure réclame:
- CV
- copie recto-verso carte d’identité (lisible et en cours de validité)
- copie carte vitale ou attestation sécurité sociale (lisible)
- RIB avec IBAN et BIC (compte courant obligatoirement) – au nom du candidat ou compte joint (uniquement Mr X OU Mme X – pas de ET ) – pas de RIB entreprise
- attestation employeur originale complétée et signée de l’autorité compétente
- copie dernière fiche de paye (non raturé, sans correcteur)
Soyons honnête, que l’intervenant soit étudiant, fonctionnaire, salarié du privé ou retraité, quelle différence s’il s’agit de rémunérer le même travail ?
Mais ce qui m’a fait le plus réagir, c’est la mention suivante dans le mail de relance: « Si vous ne souhaitez pas être rémunéré, afin de clore ce dossier, vous pouvez me retourner le dossier complété, signé, en cochant la case bénévolat et en joignant une copie de votre pièce d’identité et de votre carte vitale » (sic). Communiquer ma carte vitale comme justificatif d’une non-action ! ? !
En revanche, aucune information concrète sur la justification de la collecte de ces données (article 5 du RGPD), ni sur le lieu de leur stockage et les mesures de sécurité qui y sont associées (article 32), ni sur la durée de conservation des données (article 13). J’aimerais bien savoir, sur tous les dossiers d’enseignant-vacataire que j’ai remplis depuis trente ans, ce qui a été détruit…
Alors non, je dis non. Enfin, je ne dis rien. J’écris ce billet, qui ira rejoindre cet autre billet de 2019 Respecter le RGPD ou comment la bureaucratie m’oblige à faire des faux.
L’article Bureaucratie et données à caractère personnel est apparu en premier sur Le blog de Marie-Anne Chabin.
Mon expérience de l’enseignement à distance. Merci, Corona.
Le titre provocateur de ce billet veut souligner le fait que les crises ont cette capacité de nous obliger à revoir nos organisations, parfois en mieux.
Je dois avouer d’emblée que la contrainte d’enseignement à distance imposée quasiment du jour au lendemain à tous les enseignants en mars 2020 pour cause de Covid-19 m’a assurément moins impactée que de nombreux collègues. En effet, j’ai eu la chance de terminer mes cours du semestre juste avant le premier confinement. De plus, mon enseignement portant sur la gestion des données à risque, au sein du master « Gestion stratégique de l’information » de Paris 8, il n’est pas systématiquement lié à des outils, à des matières premières à manipuler, à des exercices de terrain. Et les promotions d’étudiants auxquelles j’ai affaire ne sont pas très nombreuses (12 à 30 étudiants). Mais, même sans cela, je crois que j’aurais réagi de la même façon.
Parler à un écran pendant toute la durée d’un cours? Non!J’ai assisté, un peu ahurie, à la ruée vers Zoom.
Pour moi, c’était non. Je n’ai pas hésité longtemps. Je n’ai pas hésité du tout.
 L’idée de transposer le cours en présentiel en un cours filmé, c’est-à-dire de parler à mon écran, partagé via une plateforme, aux étudiants connectés à la même plateforme, était même rebutante. Pour plusieurs raisons:
L’idée de transposer le cours en présentiel en un cours filmé, c’est-à-dire de parler à mon écran, partagé via une plateforme, aux étudiants connectés à la même plateforme, était même rebutante. Pour plusieurs raisons:
Un cours n’est pas une conférence. La différence, c’est la pédagogie, le cursus d’apprentissage. Une personne qui s’inscrit à une conférence ou un webinaire écoute, retient ce qui l’intéresse, peut décrocher sans que cela ait de conséquence, en tout cas moins que le décrochage des étudiants au milieu d’un cours.
Le fait d’enregistrer devant un écran le cours que l’on ne peut pas faire en présentiel est certes une solution préférable à l’annulation du cours, en cas de force majeure comme la fermeture de l’université, mais cela me fait penser à la (mauvaise) vision de la dématérialisation qui consiste à écrire un document papier puis à la scanner, plutôt qu’à concevoir la création d’un écrit numérique (by design).
Enfin, l’idée de participer à l’engraissement d’une plateforme privée qui profite de la crise sanitaire pour faire son beurre ne me souriait pas.
Il n’y a pas que des raisons négatives:
Mon expérience de responsable pédagogique de deux MOOCs m’a beaucoup servi. Le premier MOOC, présenté en 2015 sur FUN par Paris10-Nanterre et le CR2PA, Club de l’archivage managérial, sur le thème « Bien archiver, la réponse au désordre numérique » (12 000 participants !) m’avait exercée au découpage d’un cours en petits modules et aux moyens de diversifier les supports de cours. Le second MOOC, porté par le seul CR2PA en 2017 sur le thème « Le mail dans tous ses états » m’avait conforté dans l’approche pédagogique et la modularité de l’apprentissage, entre théorie, pratique, témoignages, exemples, etc.
En lien avec l’expérience MOOC, je dois citer mon intérêt depuis plusieurs années pour la classe inversée qui consiste à organiser plus de travail à la maison pour les élèves afin de consacrer les heures de cours à un échange enseignants-étudiants plus fructueux. Le cours magistral traditionnel est remplacé par une mise en commun de ce qui a été étudié avant le cours, aux questions-réponses et aux éclaircissements. J’avais déjà tenté plusieurs fois de faire étudier mes supports aux étudiants avant le cours pour organiser le débat en présentiel mais ça n’a jamais marché: puisque j’étais là devant eux, les étudiants m’écoutaient…
Une chose était sûre dès la fermeture des établissements: on ne pouvait laisser les étudiants déboussolés se déboussoler davantage.
Mais, derrière le défi immédiat d’assurer les cours, apparaissait la question de fond sur la finalité non seulement de chaque cours mais de toute la démarche d’enseignement.
Mais au fait, quel est l’objectif?Si d’autres événements/arguments ne lui suggèrent pas d’autres voies, un enseignant, comme tout professionnel du reste, a tendance à reproduire le schéma de son propre apprentissage, dans le cadre de l’évolution administrative (bureaucratique) et technique (poussive) du système scolaire et universitaire.
Le virus joue alors un rôle positif de révélateur.
Car les tenants et aboutissants de l’enseignement n’ont pas attendu le coronavirus pour évoluer mais – et c’est le sens du mot « crise » – ces changements qui étaient à l’œuvre depuis quelques temps sont soudain manifestes ou manifestés.
Parmi les signes annonciateurs d’un nouveau contexte d’enseignement, j’en retiens trois: Wikipédia, les smartphones et les bibliographies des mémoires d’étudiants.
Wikipédia, une des belles réussites d’Internet, sans contredit, symbolise un nouveau rapport à l’apprentissage, qu’il s’agisse d’ailleurs de l’université, des lycées et collèges, des professionnels ou du grand public. L’encyclopédie en ligne, globalement de bonne qualité, joue un rôle plus important dans l’acquisition du savoir que les dictionnaires et encyclopédies papier de naguère, parce qu’elle est facile d’accès (un clic de n’importe où) et surtout en raison de la somme colossale de connaissances de tous types qu’elle met à disposition. Les cours magistraux en sont ringardisés, à tort pour la cohérence d’un cours théorique tout au long d’une année, d’un semestre ou d’un trimestre (Wikipédia ne garantit pas la cohérence de sa consultation), à raison pour la somme de données et références à jour que procure L’encyclopédie numérique. Paradoxalement, Wikipédia me fait penser à l’ORTF, c’est-à-dire à une époque où la grande majorité de la population regardait plus ou moins le même programme, contrairement à la dispersion et à l’hétérogénéité des médias d’opinion et de divertissement aujourd’hui. Car l’encyclopédie en ligne fait autorité; elle doit certainement ce statut à son fonctionnement participatif mais peut-être pas seulement. À voir.
La modification des pratiques d’apprentissage apportée par la diffusion et la généralisation des smartphones depuis dix-quinze ans est d’ordre spatio-temporel. Le petit compagnon qu’on met dans la poche quand on ne le tient pas à la main a instauré le réflexe de s’informer (à défaut de s’instruire) partout et tout le temps. Y compris pendant les cours. Certes, il y a encore des professeurs de l’enseignement supérieur qui interdisent les « téléphones portables » dans les salles de cours. Est-ce bien raisonnable? Les étudiants qui téléphoneraient en cours méritent évidemment d’être rappelés à l’ordre car ils perturbent le groupe. Mais les smartphones servent de moins en moins à téléphoner et de plus en plus à prendre des notes et à vérifier ce que dit le prof sur Wikipédia! (« Madame, Internet n’est pas d’accord avec ce que vous venez de dire ! »). Est-ce grave? Pas tant que ça. Il est illusoire de vouloir arrêter cette tendance. N’est-il pas plus opérant de l’accepter, de la canaliser, de la circonvenir ?
Le troisième indice, les bibliographies, n’est pas si éloigné des deux premiers dont il est aussi une conséquence. Je suis frappée depuis que j’enseigne dans des établissements d’enseignement supérieur, soit une quinzaine d’années, par la baisse de qualité des bibliographies dans les devoirs et mémoires étudiants. Mon expérience est peut-être minoritaire mais je ne crois pas. Outre les normes de présentation des ouvrages et articles, trop négligées assurément, la question est celle de la sélection des références, de la lecture effective de ces références et de la digestion des lectures. Le fait de pouvoir accéder à de très nombreuses ressources en ligne, les algorithmes de recherche orientés trop souvent vers la pub ou l’information la plus récente, la multiplication des textes et articles courts au détriment des manuels et ouvrages de fond, voilà autant de perturbateurs de la constitution classique d’une bibliographie de recherche; ceci requiert un accompagnement spécifique dans une société hyperconnectée. Beaucoup d’enseignants le font déjà mais il y a toujours des professeurs qui exigent de leurs étudiants de se limiter aux revues scientifiques et d’exclure les articles en ligne ou les blogs. Est-ce bien raisonnable?
Ces constats suggèrent de revenir à l’objectif fondamental de l’enseignement.
Enseigner au 21e siècle, c’est transmettre un savoir (toujours) et un savoir-faire (logique) mais aussi, et de plus en plus vu la turbulence du monde de l’information dont le monde de l’enseignement fait partie, un savoir-être, les fameux (ou fameuses ?) soft skills.
L’acquisition du savoir se fait par l’écoute, la lecture, la reformulation, la réécoute, la relecture, l’appropriation des connaissances en fonction du profil et du rythme de l’étudiant. Que le vecteur soit un enseignant sans une salle de cours ou un programme de lecture, visionnage, exercices prédéfini par l’enseignant ne change pas vraiment les choses. C’est le contenu, objectif, qui prime.
La transmission du savoir-faire exige une part d’aller-retour, de questions-réponses, de propositions-corrections dont l’itération permet de consolider l’apprentissage. Et une part de démonstration et de faire-ensemble qui fait passer plus de choses entre enseignant et enseignés que les simples mots ou les simples images.
La partie savoir-être implique davantage la relation humaine, entre autorité de l’enseignant acceptée par les étudiants et volonté ou acceptation des étudiants de recevoir un message qui peut être positif (voilà ce qu’on vous demande ou qu’on vous demandera) ou négatif (on ne fait pas ça), ou encore un peu éloigné des préoccupations immédiates mais destinées à constituer une référence (un jour peut-être vous serez confronté/confrontée à telle ou telle situation et vous pourrez faire ceci ou cela). Dans cette optique, la présence dans un même lieu des uns et des autres est le meilleur cas de figure mais le lien personnel est l’essentiel, même par courrier, même par téléphone comme j’en ai fait l’expérience.
 Il est donc possible et souhaitable de réviser et d’optimiser l’organisation de l’enseignement en intégrant les atouts des technologies (récentes ou plus anciens) et les évolutions sociales du temps. Le ministre de l’éducation n’a pas pu ou voulu le faire. Les syndicats non plus. Le Covid-19 l’a fait.
Il est donc possible et souhaitable de réviser et d’optimiser l’organisation de l’enseignement en intégrant les atouts des technologies (récentes ou plus anciens) et les évolutions sociales du temps. Le ministre de l’éducation n’a pas pu ou voulu le faire. Les syndicats non plus. Le Covid-19 l’a fait.
Voici donc comment ce sont déroulés mes trois séries de cours pendant cette période sanitaire (une série de sept cours de trois heures pour les Master 1, deux séries de dix cours de trois heures pour les Master 2).
J’ai tout d’abord ajusté le programme des cours pour mieux articuler les cours entre eux, avec des rappels, afin de faciliter le travail d’itération si utile à l’apprentissage et que je faisais avant de vive voix.
Ensuite j’ai découpé mes cours et supports de cours en petits modules de 10-15 minutes en variant davantage les formats: introduction du cours en vidéo (j’enregistre une petite séquence vidéo pour expliquer aux étudiants le but du cours et comment procéder), visionnage de vidéos déjà disponibles sur une plateforme ou un site, lectures d’articles (en ligne ou envoyé par mail), slides explicatives du cours (les slides classiques sur les définitions, les concepts, les objectifs, l’état de l’art, etc. mais mieux rédigées pour être autoportantes), schémas (existants ou les miens, révisés également dans ce contexte distanciel et suivi d’un texte explicatif), exercice ou questions à se poser (avec ou sans corrigé).
Ce support était envoyé aux étudiants environ 48 h avant le cours pour lecture et réflexion, avec le planning nominatif de mes appels téléphoniques aux heures prévues pour le cours. Le nombre d’étudiants permet ces appels personnalisés, ce qui serait impossible avec cinquante étudiants, mais je pense que j’aurais trouvé autre chose. Là, les appels durent 20 à 30 minutes par étudiant, une heure s’ils ont souhaités être appelés en binôme. Pour ceux qui le demandent expressément, l’entretien a lieu en visio (un cas sur dix en réalité).
 J’appelle les étudiants à l’heure prévue et, sauf exception qui confirme la règle, la personne est au bout du fil et, ayant étudié le support de cours, me pose les questions qu’elle a préparées. Je réponds et parfois aussi relance l’étudiant sur le pourquoi de telle question qui me surprend. On essaie de ne pas déborder du créneau dédié pour respecter le rendez-vous suivant mais parfois l’entretien est plus court car il n’y a plus de questions.
J’appelle les étudiants à l’heure prévue et, sauf exception qui confirme la règle, la personne est au bout du fil et, ayant étudié le support de cours, me pose les questions qu’elle a préparées. Je réponds et parfois aussi relance l’étudiant sur le pourquoi de telle question qui me surprend. On essaie de ne pas déborder du créneau dédié pour respecter le rendez-vous suivant mais parfois l’entretien est plus court car il n’y a plus de questions.
En fin de journée, je saisis l’ensemble des questions avec mes réponses. Il faut dire que, à part deux ou trois questions récurrentes (que j’apprends à anticiper avec l’expérience), je suis frappée par la variété et la pertinence des questions d’un étudiant à l’autre. J’envoie ce petit bilan à tous dans la foulée.
On m’objectera que la communication téléphonique est un peu ringarde quand la visio est possible. Eh bien, non, je ne suis pas de cet avis. Au contraire. Du moins pour les conversations à deux, trois ou quatre personnes. Le téléphone exonère de ses insupportables « Vous m’entendez? », « Votre caméra n’est pas activée!, « Allo… », « Excusez-moi, j’ai un problème technique, je dois me reconnecter »; déjà 15% du temps d’entretien perdu… Le téléphone permet de se concentrer sur la voix, qui laisse passer beaucoup de choses du comportement ou de l’état d’esprit de l’interlocuteur pour peu qu’on soit attentif. Or, l’image distrait, souvent inutilement. J’ajouterai pour ma part que le téléphone me permet d’écouter et de prendre des notes en même temps, ce qui est plus compliqué si je dois regarder mon interlocuteur. On peut bien sûr désactiver la caméra de la visio et ne garder que le son, notamment pour soulager la bande passante et réduire le coût numérique, mais alors, si on se contente de la voix, le téléphone est plus approprié et ces écrans gris ou noirs, pour moi du moins, sont pires que l’image.
Après avoir évalué les plus et les moins de cette nouvelle formule, j’ai décidé de la conserver à mi-temps lors de la réouverture des universités, en alternant cours en présentiel / cours à distance sur ce modèle.
Les inconvénients tout d’abord. Bien sûr, rien ne vaut a priori le face à face pour la transmission d’un message; le présentiel est la seule configuration où la communication a le plus d’atouts (gestuelle, vraie vie…). Sur un autre plan, cette organisation demande un peu plus de travail, en tout cas à l’enseignant mais cet investissement peut être rentabilisé dans la durée en capitalisant un nouveau savoir-faire.
À noter également, parmi les points négatifs, le relatif isolement des étudiants du à la baisse des rencontres avec leurs camarades et plus généralement avec la communauté universitaire mais il est possible, dans la limite des contraintes sanitaires, de maintenir des liens sociaux, peut-être moins nombreux mais d’une qualité renforcée.
Les avantages s’avèrent plus nombreux: moins d’heures pénibles passées dans les transports en commun (les usagers de la ligne 13 du métro parisien sauront de quoi je parle…) ; moins d’interruptions de cours dues aux arrivées tardives des étudiants dans la salle, pour de bonnes ou de moins bonnes raisons; moins de soucis techniques liés au vidéo-projecteur en panne ou autres problèmes logistiques ou bâtimentaires.
Surtout, cette formule est pédagogiquement plus efficace. Elle est plus exigeante de la part de l’enseignant donc plus ciblée. Et les étudiants jouent le jeu, étudient avant mon appel et posent des questions qu’ils ne poseraient pas en cours. C’est là que la contrainte du confinement a été productive : les étudiants se sont montrés beaucoup moins passifs qu’auparavant, et sans exception pour ce qui concerne mon master. En tout cas, la majorité a validé cette forme d’apprentissage mixte.
_________
Plutôt que de classe inversée, on parle davantage aujourd’hui d' »apprentissage hybride« . Peu importe le flacon, pourvu qu’on ait l’ivresse !
Cette organisation pédagogique, avec la sobriété que j’ai voulu y mettre ou sous une forme plus technologique, n’est peut-être pas transposable à d’autres matières que celles que j’ai le plaisir d’enseigner, à savoir la gestion des données à risque dans l’entreprise (records management, archivage managérial, gouvernance de l’information) et je serais ravie si mes lecteurs enseignants faisaient part de leur expérience, similaire ou opposée.
Personnellement, j’aimerais pouvoir aller encore plus loin et, à la façon des philosophes grecs, enseigner la gestion des données à risque en visitant les entreprises avec mes étudiants, pour commenter les problèmes et les solutions. Peut-être un jour ou dans une autre vie…

L’article Mon expérience de l’enseignement à distance. Merci, Corona. est apparu en premier sur Le blog de Marie-Anne Chabin.
Les données ont-elles évincé ou éclipsé les documents? 3/3
Pour filer la métaphore politique du « règne » de la donnée, disons que la primauté du document, c’est l’Ancien Régime. Or, le changement de régime, même rapide, même brutal (heureusement nous n’en sommes pas ici aux effusions de sang) ne se fait pas sans résistance dans la population (les utilisateurs), sans interférences, sans résurgence à terme de certaines idées.
Le document ne s’avoue pas vaincu (ce serait dommage) et les concepts dont il a été si longtemps le porteur, notamment celui d’un objet d’information fini, délimité, daté, sourçable et référençable, ou encore le vecteur que représente le document entre un auteur qui a une intention et un destinataire concerné, ne sont pas effacés par la domination des données. Je dirais même au contraire, ils sont invités à défendre leur cause et fourbir leurs arguments, quitte à changer de nom. En politique, ça se fait…
 Le document fait de la résistance…
Le document fait de la résistance…
Face à la donnée qui s’impose dans le monde de l’information, dans le monde du travail, dans les médias, le mot « document » résiste. Le contraire eût été inquiétant.
On peut observer plusieurs formes de résistance, en considérant le document comme objet, ou comme notion de droit, ou encore comme habitude de langage.
Pour beaucoup de gens et plus encore dans le monde des bureaux, le mot document renvoie visuellement à un objet rectangulaire, le plus souvent de couleur blanche avec des petits signes noirs fixés dessus. Qu’il se présente sur support papier ou sous forme numérique, le document est un objet visible sur une table ou un écran. L’aspect visuel ne doit pas être négligé dans la force du mot.
Le document papier n’est pas véritablement en situation conflictuelle avec la donnée. Il vit sa vie, déclinante (le courrier papier a été remplacé par les mails, les documents administratifs sont devenus des formulaires en ligne, etc.). Le document papier en quelque sorte est arrivé à une patte d’oie : à gauche les archives, à droite les données. Ou bien le document s’attache aux pratiques de naguère, avec leur charme désuet, ou bien il saute dans le bain de la production numérique native qui est désormais la règle pour les échanges d’information quotidien. Il doit faire un choix.
La situation du document numérique est un peu différente. En effet, le document numérique est plus une transposition en numérique d’un document « pensé en papier » qu’une production du monde numérique. Le document numérique est né dans les années 1980 par le biais des outils de numérisation (scan) et des systèmes de GED (gestion électronique de documents). C’est en fait de cette époque pas si lointaine que date l’image du document A4 comme représentation quasi unique du document (alors qu’il est bien autre chose). Le format PDF est inventé une décennie plus tard et normalisé par l’ISO en 2008 (grande victoire d’Adobe). Et aujourd’hui PDF est presque devenu un nom commun (c’est même un nom de chat, Pédéèf).
Mais l’époque « je produis du papier et je le scanne ; je continue à produire du papier pour continuer à le scanner » est révolue. La résistance du document numérique comme scan du document papier A4 atteint ses limites face à la diffusion des technologies de production numérique native « libérée », c’est-à-dire conçue avec les nombreuses possibilités du monde numérique, combinant les fonctionnalités logicielles et la mise en réseau. Les tenants de la GED qui étaient naguère les modernes sont devenus les anciens face aux data managers. La GED a atteint l’âge canonique (quarante ans) et ne va plus résister longtemps.
Je ne suis pas la seule à le dire. « La GED, c’est fini ! » déclarait déjà Philippe Goupil en 2017 : « Il est maintenant trop tard pour considérer la GED comme une solution d’avenir! ». Le document numérique s’est affranchi du carcan dont l’avait enveloppé sa génitrice la GED pour se jeter dans les bras de la data. Le match n’est pas encore tout à fait terminé ; je le vois bien aux questions de mes étudiants qui m’interrogent sur les systèmes de GED (parce que les entreprises où ils font leur stage en sont parfois encore là) mais, malheureusement pour elle, la fin de la GED est réellement programmée.
Sur un autre plan, le document résiste aussi parce qu’il est inscrit dans les codes de loi français depuis le code Napoléon et que, si les données ont fait une entrée en force dans la loi, deux siècles de législation ne se balaient pas en un jour.
Une requête sur le site Legifrance, réalisée il y a quelques jours, donne les résultats suivants : les articles des 67 codes totalisent 8631 occurrences du mot « document ». Difficile de dire si c’est beaucoup ou non car quel serait la base de la comparaison ? Ce qu’on peut préciser, c’est que la même requête donne 5750 pour « données ». Après avoir constaté que « donnée(s) », dans plus de 50% des cas, est tout simplement le participe passé du verbe donner – ce qui biaise la comparaison – on arrive grosso modo à la conclusion que les documents sont trois à quatre fois plus nombreux dans le corpus législatif et réglementaire. L’utilisation du mot données étant surtout le fait des textes des dernières années, le « rapport de force » documents/données ne devrait pas tarder à s’inverser. Et l’étude est plus intéressante encore si on inclut les 14061 occurrences du mot « information » mais j’arrête ici ma digression.
Quelques remarques sur l’échantillon d’extraits de loi fournit par Legifrance à ma requête :
- les adjectifs ou compléments de nom liés au mot document précisent généralement le contenu ou le processus qui donne lieu auxdits documents : documents comptables, documents d’aménagement, documents électoraux, documents d’objectifs, documents d’identité ;
- d’autres qualificatifs soulignent le statut du document : obligatoire, justificatif, nécessaire, patrimonial ;
- document est associé à autres substantifs dans diverses expressions qui mettent en évidence des rôles différents et complémentaires entre : renseignements et documents (code de la consommation), livres et documents sociaux communiqués aux associés (code civil), documents et rapports communiqués au commissaire aux comptes (code de commerce), œuvres ou documents à caractère pornographique (code du cinéma), titres et documents (code du domaine de l’État), registres et documents dont la tenue est à la charge des exploitants d’aérodromes (code l’aviation civile).
Les occurrences du mot données « à la place de document » sont généralement récentes et liées à la protection des données personnelles et plus précisément à la durée de conservation de ces données : « les données d’état civil et les données relatives à la situation sociale » (code de l’entrée et du séjour des étrangers et du droits d’asile, article R142-56); « Les données relatives à la traçabilité des échanges sont conservées pendant une durée de trente-six mois […] » (code des relations entre le public et l’administration, article R114-9-7); « Les données relatives au taux d’alcoolémie des conducteurs ne doivent être ni consultées, ni communiquées, ni utilisées. […] » (code de la route, article L234-15).
Le processus de « datification » de la réglementation est en marche. On peut toutefois se demander si les données pourront se substituer aux documents dans tous les cas de figure, même en repensant la production de l’information dans un contexte numérique ? Hum…
Les deux extraits de code ci-après comportent les deux mots, document et donnée, dans la même phrase.
La section 4 du code de la santé publique est titrée « Conditions de reconnaissance de la force probante des documents comportant des données de santé à caractère personnel créés ou reproduits sous forme numérique et de destruction des documents conservés sous une autre forme que numérique », d’où on peut comprendre que les documents numériques comportent des données (à caractère personnel ou non) et peut-être aussi autre chose (ou pas), mais on ne saurait dire, à partir de cette formulation, si les documents non numériques comportent aussi des données.
Le code pénal, sans son article 413-11 sur le secret de la défense nationale énumère les « choses » dont l’accès non autorisé, la destruction ou la divulgation est passible de cinq ans d’emprisonnement et de 75 000 euros d’amende ; il s’agit de : « procédé, objet, document, information, réseau informatique, donnée informatisée ou fichier ». Les articulations potentielles entre ces différentes entités ne sont pas précisées. On peut noter au passage que l’utilisation de donnée au singulier est très rare dans les textes réglementaires…
On pourrait poursuivre pendant des pages et des pages cette analyse lexicale pour le détail mais la tendance générale est claire.
Deux exemples pour conclure sur ce point de la résistance du document :
Le document unique d’évaluation des risques (DUERP), obligatoire dans toutes les entreprises dès l’embauche du premier salarié, ne ressemble quasiment jamais à un document traditionnel A4 ; c’est un fichier Excel à X onglets ou carrément une base de données, mais le mot a été conservé.
Lors des fuites de données dont notre époque est friande, le mot document a une bonne place : le mot anglais « papers » est même très présent (Panama papers, Pandora papers), les médias soulignant la fuite de millions de « documents », à côté des données, fichiers ou archives (records).
Le document sous forme d’agrégation de donnéesLaissons de côté les mots pour revenir aux réalités qu’ils désignent.
Les technologies numériques ont brisé le cadre contraignant du support matériel et en quelque sorte libéré les contenus.
Dès lors, le document tend à s’effacer derrière les données qu’il comporte (le document contient des données) ou qui le composent (le document est constitué de données). Dans les deux cas, le document devient secondaire car les données occupent la première place et captent l’attention.
C’est ce qui se passe notamment avec le traitement numérique des livres dans les bibliothèques ou avec la documentation technique dans les services d’ingénierie. Le document « pré-numérique » est décomposé en données individualisées, cherchables par un moteur de recherche, isolables, extractibles. « En permettant le traitement informatisé du contenu lui-même, la numérisation a peu à peu provoqué une modification dans l’appréhension des choses » ; « le document est un ensemble de données exploitables », écrit Gautier Poupeau, auteur du blog Les petites cases, dans une présentation pédagogique intitulée Visite guidée au pays de la donnée. L’auteur souligne le changement de granularité de l’information traitée, grâce à la technologie.
Cet effacement du document derrière les données voire « la » donnée intervient également lorsque le document n’existe plus que virtuellement, postérieurement à la production des données, par agrégation conjoncturelle d’un groupe de données.
Plusieurs normes internationales, relatives au records management électronique (archivage des informations numériques engageantes) utilisent le concept d’agrégation (aggregation). C’est le cas de MoReq2010 et d’ICA-Req publiée en 2008 et devenu ultérieurement ISO 161875).
L’agrégation ou agrégat est vu comme un regroupement de documents (records) mais aussi comme regroupement de données: « Any accumulation of record entities at a level above record object (document, digital object), for example, digital folder, series ». Bien que ces normes, rédigées il y a déjà dix ou quinze ans, mettent d’abord en évidence l’agrégation de documents en dossiers, le terme agrégation illustre bien cette construction logique de données existantes pour produire un objet d’information que l’on appelait document dans le monde pré-numérique, sans se poser de question. La figure ci-après, extraite du module 3 de ICA-Req (Recommandations et exigences fonctionnelles pour l’archivage des documents dans les applications métier) s’intitule « Identification des composants d’information (ou données) constituant un document électronique engageant dans une base de données »:
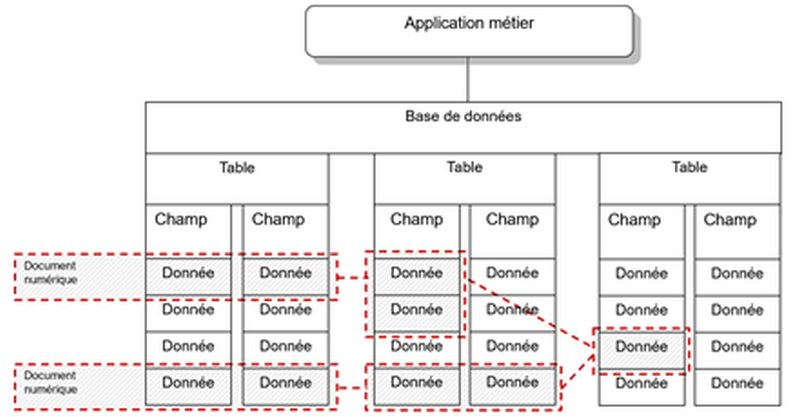 La notion est simple quand on a affaire à des données dites structurées produisant un « document » de type formulaire, avec des champs bien individualisés, comme un bulletin de paie ou une facture.
La notion est simple quand on a affaire à des données dites structurées produisant un « document » de type formulaire, avec des champs bien individualisés, comme un bulletin de paie ou une facture.
Pour autres cas, c’est-à-dire les documents répondant à la définition de « données non structurées », l’agrégation est plus complexe.
Pour illustrer ce cas de figure, je vais m’appuyer sur un des articles figurant dans ma revue de presse au début de la partie 1 de mon étude: « Une copie d’examen manuscrite est-elle un ensemble de données à caractère personnel ? » proposé par l’excellent blog Droit et technologies. Il concerne un document papier mais l’analyse de la relation entre document et données n’en est que plus parlante.
La Cour de Justice de l’Union Européenne (CJUE) a eu à examiner la requête d’un Irlandais, candidat malheureux à un examen, à qui on refusait de consulter sa copie, au motif que la copie « ne constitue pas des données à caractère personnel au sens des lois sur la protection des données. Il en ressort que, oui, la copie d’une épreuve écrite contient des données à caractère personnel : « dès lors qu’elle matérialise des informations relatives au candidat, elle est dans cette mesure, un faisceau de données à caractère personnel ». Il est précisé que l’écriture elle-même peut contenir une information sur la personne; et encore que les annotations du correcteur sont également considérées comme des données personnelles du candidat.
Dans cet exemple de la copie d’examen, il est patent que les données sont aujourd’hui bien autre chose que des chiffres ou des valeurs que l’on met dans des cases, bien que cela reste la définition la plus courante dans les glossaires et dictionnaires qui, comme je le soulignais dans la première partie, ne sont pas à jour.
Pour le dire autrement, ne faut-il pas considérer qu’une copie d’examen est un tout insécable, indissociable (rédaction et correction) et que, si des données peuvent en être extraites pour tel ou tel traitement, cet agrégat (ce fichier, ce jeu de de données) n’en garde pas moins son statut de « document » au sens de la définition « recorded information or object which can be treated as a unit / tout écrit ou enregistrement considéré comme une unité documentaire (ISO 15489)?
C’est pourquoi le fait que le mot document soit évacué du RGPD (comme celui de record de la GDPR) m’a marquée par sa radicalité. Le RGPD demande que l’on détermine la durée de conservation des données à caractère personnel et que la personne concernée en soit informée. Soit, mais comment appliquer une durée de conservation à des données élémentaires? Et comment appliquer une durée de conservation (et une action de destruction) à un groupe de données qui n’est pas appréhendé comme l’expression d’une interaction entre deux personnes (émetteur et destinataire, source et producteur) avec une intention (finalité) particulière à une date identifiée?
Bertrand Müller, déjà cité dans la partie 2 de ce long billet, dit encore: « Une donnée isolée, c’est-à-dire coupée de son contexte de production mais aussi de son contexte de validité est une donnée in-signifiante. Documenter une donnée revient à noter comment elle a été conçue, ce qu’elle signifie, et préciser son contenu et sa structure. La documentation est également décisive pour assurer une longue conservation des données. » Je suis plus que d’accord.
Pour illustrer cette non-signification de la donnée isolée, j’utilise volontiers le dessin suivant (où la représentation de LA donnée par une petite fille en robe pourra être saluée par les uns et moquée par les autres, selon la vision du féminisme de chacun, peu importe):
 Mon propos est de montrer à ceux qui n’en aurait pas conscience que le règne de la donnée n’est pas une génération spontanée et s’appuie, en renommant les choses comme on fait en politique, sur un substrat documentaire existant et souvent ancien. On peut voir par exemple dans le schéma: un document structuré (un bulletin de paie par exemple), un flux de données de connexion, et deux dossiers thématiques. Le document, comme agrégation de données, est virtuel – même s’il peut faire l’objet d’un enregistrement spécifique – et tient par le lien de valeur commune des données ainsi regroupées.
Mon propos est de montrer à ceux qui n’en aurait pas conscience que le règne de la donnée n’est pas une génération spontanée et s’appuie, en renommant les choses comme on fait en politique, sur un substrat documentaire existant et souvent ancien. On peut voir par exemple dans le schéma: un document structuré (un bulletin de paie par exemple), un flux de données de connexion, et deux dossiers thématiques. Le document, comme agrégation de données, est virtuel – même s’il peut faire l’objet d’un enregistrement spécifique – et tient par le lien de valeur commune des données ainsi regroupées.
Dans la partie 2 de cet article, je soulignais l’importance accordée par Jérôme Denis, dans son étude sociologique des données, aux activités d’écriture et de lecture qui participent de la fabrication et de la circulation des données.
On parle de plus en plus du cycle de vie des données comme on parlait (et on parle encore) du cycle de vie des documents, avec des points de vue très différents : certains considèrent le statut de la donnée de sa création à sa réutilisation, d’autres limitent la question aux étapes de gestion et de circulation dans un système d’information ou une entreprise; et j’ose à peine évoquer la vision paradoxalement étroitement logistique des Archives de France et de la CNIL.
Il me semble important de prendre en compte l’origine des données (qu’il s’agisse de noms, de valeurs, de chiffres, de signes, d’opinions, etc.), c’est-à-dire la première fois où elles sont enregistrées, inscrites quelque part, formalisées, écrites, avant d’être transmises, stockées, « travaillées » pour reprendre de terme de Jérôme Denis afin, le cas échéant, d’être lues, interprétées, réutilisées, réenregistrées, réinscrites, reformalisées, réécrites, dans un nouveau contexte, avec de nouveaux acteurs, avec une nouvelle intention, une nouvelle finalité.
Depuis la loi sur la loi du 13 mars 2000 portant adaptation du droit de la preuve aux technologies de l’information et relative à la signature électronique (en transposition de la directive européenne du 13 décembre 1999 sur le même sujet), on entend dire régulièrement, parmi les acteurs de la « dématérialisation » et de la GED, qu’un document électronique est juridiquement recevable au même titre qu’un document papier dès lors que son auteur est authentifié et que l’intégrité du document a été préservée depuis sa création. Mais la loi ne parle pas de document dans cette affaire; elle parle d’écrit. L’article 1366 du code civil dit précisément: « L’écrit électronique a la même force probante que l’écrit sur support papier, sous réserve que puisse être dûment identifiée la personne dont il émane et qu’il soit établi et conservé dans des conditions de nature à en garantir l’intégrité ». À noter que c’était l’article 1316-1 avant 2016 mais la rédaction était la même à deux mots près: « l’écrit sous forme électronique » est devenu « l’écrit électronique ». J’y vois une appropriation commune de la chose. Peut-être une prochaine version passera-t-elle à « l’écrit numérique » ?
Écrit est par ailleurs défini par l’article 1365 du même code civil: » L’écrit consiste en une suite de lettres, de caractères, de chiffres ou de tous autres signes ou symboles dotés d’une signification intelligible, quel que soit leur support ». Cette rédaction, qui date également de 2016, s’inspire du précédent article 1316 définissant la preuve par écrit « La preuve littérale, ou preuve par écrit, résulte d’une suite de lettres, de caractères, de chiffres ou de tous autres signes ou symboles dotés d’une signification intelligible, quels que soient leur support et leurs modalités de transmission ». Voir à ce sujet l’article de Béatrice Fraenkel et David Pontille: L’écrit juridique à l’épreuve de la signature électronique, approche pragmatique, dans Langage et société 2003/2 (n° 104), pages 83 à 122.
Cette définition de l’écrit, comme on le voit, est bien plus large que celle de document qui à la fois beaucoup veut dire plus (autres acceptions) et évoque beaucoup moins (restriction constatée de la rectangularisation du document avec la GED, voir supra).
L’écrit est tout à fait données-compatible.
De sorte que le terme écrit, malgré sa connotation un peu vieillotte (on pense à manu-scrit, on visualise un stylo plutôt qu’un clavier) se prête malgré tout assez bien à la désignation de cette chose qui résulte de l’enregistrement d’une information par un individu qui s’exprime, et même par un individu qui énonce quelque chose sur autrui.
L’expression de « documents écrits » pourrait avantageusement être éclatée entre l’écrit qui trace (enregistrement) et le document qui enseigne (doceo, documentum). L’écrit au sens d’inscription est le fait d’un sujet, l’auteur; le document informe sur un objet. Cependant une même entité, disons un groupe de données pour utiliser le vocable qui a le vent en poupe, peut être tantôt écrit, tantôt document, ou plutôt les deux ensembles mais pour des regards différents.
Par exemple, cette copie d’examen évoquée un peu plus haut dans sa dimension d’ensemble de données à caractère personnel, y compris à l’extérieur des mots (l’écriture du candidat – au sens de représentation graphique – n’est pas dans un mot mais dans tous), cette copie d’examen donc – que j’ai qualifiée d’agrégation indissociable pour l’usage que l’on veut en faire – est d’abord le produit d’une inscription par le candidat, d’une écriture – au sens d’action d’écrire – sur un support dont la production ne s’arrête pas avec la fermeture de la salle d’examen mais est bornée par le processus de l’examen et inclut par conséquent les corrections des examinateurs. Cette copie est à la fois la trace d’une action engageante et la source d’un enseignement. J’aouterai qu’elle est doublement engageante (pour le candidat et pour le correcteur et l’institution qu’il sert).
L’étude du champ de l’écrit est vaste. Elle l’est par la masse déjà produite et accessible (archives). Elle l’est aussi par l’explosion des formes d’écrits permises et suggérées par les technologies numériques. C’est le domaine de la diplomatique, discipline pluriséculaire pour l’étude de l’authenticité des actes anciens dans une approche rétrospective, mais aussi, plus largement et dans une démarche également prospective, une étude de la justesse des écrits, de leur complétude et de leur impact. Quelles sont les caractéristiques formelles d’un écrit qui permettent d’exploiter de manière fiable les informations qu’il véhicule? Quelles sont les imperfections qui fragilisent, aujourd’hui et dans la durée, son auteur, son détenteur ou les personnes concernées?
Ma réflexion là-dessus doit encore et toujours à ma lecture du chapitre de Georges Tessier dans L’Histoire et ses méthodes (La Pléiade, 1961) où le mot écrit est très présent. Extrait (p 665): « tout acte juridique peut être consigné dans un écrit destiné à lui servir de preuve. On a alors affaire à un acte écrit, à un instrument, comme on disait autrefois, à l’imitation des Romains, et comme on le dit encore dans le langage du droit international public. L’acte écrit, l’instrument « documente » l’acte juridique. Il s’en présente comme le témoignage, et le mot allemand Urkunde a précisément la vertu d’associer étroitement l’idée de témoignage à celle d’acte écrit. Mais un acte écrit peut témoigner d’autre chose que d’un acte juridique. Il peut attester « des faits matériels qui ne comportent aucune disposition de volonté, mais qui sont pourtant susceptibles de conséquences juridiques » [citation du diplomatiste A. Dumas]…. ».
Soixante ans plus tard, cette appréciation est aisément transposable au monde numérique des entreprises connectées, des plateformes et des réseaux sociaux.
ConclusionPour conclure ce triple billet et répondre à la question de savoir si les données ont évincé ou ont éclipsé les documents, je dirai que le règne de la donnée a, à ce jour, marginalisé plutôt que terrassé la notion de document, en le poussant de ce fait à s’adapter, techniquement, culturellement, linguistiquement, s’il veut défendre ses couleurs (qui ne se limitent au noir et blanc…) et son patrimoine.
On peut, à partir de là, imaginer deux scénarios: ou bien le monde de la donnée se carre dans son fauteuil technologique et ignore les autres cultures de l’information, les condamnant à se replier sur un sous-continent à la dérive; ou bien il s’instaure un dialogue fructueux entre innovation et expérience, dans une optique de capitalisation du savoir et d’acculturation de tous.
Je reconnais volontiers que ma réflexion n’est pas aboutie. Ces quelques pages sont plutôt un bloc-notes après certaines lectures d’horizons variés, une sorte de « problématique par petites touches » qui est malgré tout le début de quelque chose.
Comme l’a remarqué une de mes commentatrices sur LinkedIn, il y a assurément matière à organiser un grand colloque sur la donnée, regroupant les chercheurs de diverses disciplines qui se rattachent tant aux sciences dites humaines (sociologie, droit, diplomatique) qu’aux sciences dites dures, plus précisément les sciences dites « du numérique » (algorithmique, apprentissage profond, visualisation, etc.) mais aussi des responsables administratifs ou politiques. Rêvons un peu…
L’article Les données ont-elles évincé ou éclipsé les documents? 3/3 est apparu en premier sur Le blog de Marie-Anne Chabin.
Les données ont-elles évincé ou éclipsé les documents? 2/3
Pour tout dire, l’idée de ce billet m’est venue il y a quelque temps déjà, lorsque j’ai lu l’ouvrage de Jérôme Denis, Le travail invisible des données. Éléments pour une sociologie des infrastructures scripturales, Paris, Presses des Mines, Collection Sciences sociales, 2018.
Cette lecture m’a donné envie de creuser la question de la relation entre documents et données. Elle m’a renvoyée à d’autres constats et m’a fait revisiter d’autres lectures. Ce sont ces constats que j’aborde dans cette seconde partie, après un petit panorama de publication autour des données (voir partie 1 – Le règne de la donnée) et avant de me livrer à un examen diplomatique du sujet (ce sera la partie 3).
 Les données s’imposent dans la recherche
Les données s’imposent dans la recherche
Le livre Le travail invisible des données me semble représentatif d’un nombre croissant de publications de recherche (sociologie, sciences de l’information) où le document, naguère très présent, s’efface devant le mot données. C’est une impression subjective qui mériterait d’être confirmée ou infirmée par une analyse textométrique en bonne et due forme.
Jérôme Denis est sociologue, avec une longue expérience de la gestion des données dans le monde des ingénieurs. Dans ce livre sur « le travail invisible des données », il fait le choix de laisser de côté la « sociologie avec des données » pour s’intéresser à la « sociologie des données ». Notant qu’il n’existe pas encore de définition satisfaisante de la donnée, il dépasse la question de définition du concept (« Qu’est-ce qu’une donnée ? ») pour poser la question de savoir « Quand est-ce une donnée?« . Prenant quelque distance avec les idées généralement admises que a) nous assistons à une « révolution des données » et b) que les données seraient toutes disponibles dans le big data, il s’attache à observer « les activités d’écriture et de lecture » qui participent de la fabrication des données et accompagnent leur circulation.
Jérôme Denis introduit sa réflexion par le récit d’une expérience personnelle. Lors, du décès de son père, sa famille et lui ont été confrontés (comme bien d’autres familles) à un enchevêtrement de démarches et d’échanges d’information (administration, banque, service, compte Facebook, etc.), passage obligé pour que cette réalité du décès d’un proche, en quelque sorte une donnée non écrite, devienne une donnée validée dans la société.
Ce qui m’a d’emblée frappée à cette lecture – compte tenu sans doute de ma propre culture – c’est combien la notion de « document », pourtant si ancrée dans la vie administrative et les relations contractuelles avec tous types de fournisseurs, disparaissait derrière la notion de « donnée ». Certes, il est question de documents, notamment de documents qu’il faut signer à cette occasion, et Jérôme Denis reconnaît que les documents ne sont peut-être pas aussi accessoires pour la compréhension des faits sociaux que d’autres sociologues semblent le penser. « Les documents qui accompagnent la mort, écrit Jérôme Denis, permettent de se faire une idée assez claire du caractère performatif de certaines informations. Ils font comprendre que la production des données et les activités de lecture et d’écriture qu’elle suppose, participent pleinement à la fabrique de la réalité que nos partageons ». J’ai envie d’ajouter que ce constat ne se limite pas au contexte du deuil. Donc le document est bien-là (certificat, attestation, courrier, contrat, formulaire, relevé de compte …) mais l’auteur met en avant la notion de données, collectées dans des bases de données, embarquées dans différents flux d’information, restituées dans des documents plus formels.
À la lumière de cette expérience personnelle mais aussi universelle, Jérôme Denis se livre à une observation quasiment ethnographique des données, de la façon dont elles sont « travaillées » et de leurs « travailleurs » dans différents environnements : laboratoire, administration, banque. Il relie notamment cette manipulation des données à la notion d’inscription, ou d’écrit, terme sur lequel je reviendrai dans la partie 3.
Ce travail de recherche sur les données qui nous environnent – quand elles ne nous encerclent pas…- serait peut-être à mettre en relation avec la réflexion initiée il y a quinze ans par le groupe R.T. Pédauque sur « Le document à la lumière du numérique« ; ces travaux insistaient notamment sur la redocumentarisation permise par les technologies de décomposition-recomposition des documents, alors que les données, le big data, n’avait pas encore déferlé sur le monde.
Les données s’imposent dans la réglementationIl est loisible d’observer cet effacement progressif du document derrière la donnée, à la fois dans le discours et dans la réalité. En effet, le terme document se teinte peu à peu d’archaïsme; on est tellement habitué au document papier A4 et au fichier PDF que le qualificatif « document » accolé à des objets d’information numériques qui se présentent sous une autre forme (bases de données, vidéos, formulaires en ligne, posts sur les réseaux…) est de moins en moins compréhensible.
Mais qu’est-ce qu’un document ? La définition la plus courante dans les sciences de l’information est celle de l’ensemble formé par un support et l’information qui y est enregistrée. Ce qui est assez large et très accueillant pour les données numériques. Si on rappelle encore que l’étymologie du mot document renvoie au fait qu’il véhicule une information ou plutôt qui un enseignement (doceo en latin), on est toujours dans un concept qui dépasse largement le format A4.
Pour ceux qui n’ont jamais lu le petit ouvrage de Suzanne Briet Qu’est-ce que la documentation? (1951), il n’est pas trop tard et je les invite à cliquer sur le lien. Ils y verront, entre autres, comment une antilope capturée par un explorateur peut être considérée comme un document initial auquel sont associés divers documents scientifiques descriptifs.
Discutons, cela est toujours utile, et souvent agréable. Mais n’oublions pas l’impact de la réglementation sur les pratiques administratives et les mots qui les accompagnent. La réglementation aussi formate la réalité des choses.
De ce point de vue, le RGPD (Règlement général pour la protection des données personnelles), applicable depuis mai 2018, est un événement terminologique majeur.
En effet, ce texte essentiel pour la protection des données à caractère personnel, ce texte qui façonne largement la gouvernance des données dans les entreprises depuis plus de trois ans, ce texte qui a conduit au recrutement de dizaines de milliers de « délégués à la protection des données » (DPO), ce texte qui certes vise les excès des GAFAM mais qui oriente aussi le comportement de dizaines de milliers d’entreprise, ce texte donc parle exclusivement de données et jamais de documents.
Officiellement, dans le monde de la protection des données personnelles, le document n’a plus droit de cité. Ce n’est pas une fake news!
Plus marquant encore, la version anglaise du texte, titré GDPR (General Data Protection Regulation), a totalement évacué la notion de « record » au profit des « data ». Le mot « record » est pourtant bien plus précise que « document » en français (les records et les documents sont en archivistique anglosaxonne deux choses bien distinctes); il est aussi bien plus large dans la forme car « record » n’évoque pas uniquement un fichier A4 pour un anglo-saxon mais tout type d’enregistrement de données. Le RGPD/GDPR est assurément un coup dur porté au records management. Dès lors que les « records » sont évacués, au moins terminologiquement parlant, du champ d’application du RGPD, il est encore plus difficile qu’avant de proposer à une entreprise de déployer un projet de « records management » (archivage managérial, gouvernance des documents engageants) et cette évolution réglementaire internationale porte un coup peut être fatal à la norme ISO 15489 (2001, 2016) sur le records management naguère si vantée (et à juste titre) et aujourd’hui, bien qu’encore adolescente, si délaissée. Voir mon billet sur les mots du RGPD.
Chacun peut le vérifier, dans les 99 articles du RGPD, le mot document n’est quasiment pas utilisé pour désigner un objet documentaire constitué partiellement ou intégralement de données à caractère personnel. Une exception confirme la règle avec l’article 86 consacré aux « données à caractère personnel figurant dans des documents officiels ». Cela ne signifie pas bien sûr que les documents – car il en existe un certain nombre dans les entreprises – ne comportent pas de données à caractère personnel ni que les données à caractère personnel ne peuvent être « travaillées » pour constituer un objet documentaire nommé « document » mais la révolution terminologique est là. On pourra se consoler en remarquant que le RGPD insiste en revanche à plusieurs reprises sur la nécessité de « documenter » quelques situations, par exemple la violation de données…
Dans l’article 4 du Règlement (Définitions), les données à caractère personnel sont définies comme « toute information se rapportant à une personne physique… ». Le « traitement » de données, terme nouveau et essentiel dans réglementation, est défini comme « toute opération ou tout ensemble d’opérations effectuées ou non à l’aide de procédés automatisés et appliquées à des données ou des ensembles de données à caractère personnel, telles que la collecte, l’enregistrement, l’organisation, la structuration, la conservation, l’adaptation ou la modification, l’extraction, la consultation, l’utilisation, la communication par transmission, la diffusion ou toute autre forme de mise à disposition, le rapprochement ou l’interconnexion, la limitation, l’effacement ou la destruction ». Il serait intéressant de confronter cette énumération à la formule de Jérôme Denis: « les activités d’écriture et de lecture qui accompagnent la circulation des données ».
L’article 13 précise que le responsable du traitement (le représentant de la personne morale productrice des données) doit fournir à la personne concernée, entre autres, la durée de conservation des données à caractère personnel ou, à défaut, les critères pour déterminer cette durée », opération parfois délicate sur laquelle je reviendrai dans la troisième partie.
Une question qui, à mon avis, n’a pas été assez étudiée est le recouvrement entre le périmètre informationnel relevant du RGPD et le périmètre informationnel du records management (gouvernance des documents engageants, archivage managérial). Car il est manifeste que les personnes chargées dans l’entreprise de la protection des données au titre du RGPD et celles qui sont chargées de l’archivage (i.e. la mise en sécurité dans la durée) s’intéressent sur le terrain aux mêmes « machins », quel que soit le nom qu’on leur donne. La question, posée en 2017 lors d’une table ronde organisée par le CR2PA (Club de l’archivage managérial) chez L’Oréal laissait voir diverses interprétations de ce recouvrement. Le débat, toujours actuel, est sans doute faussé par la séparation des disciplines universitaires et des fonctions en entreprise, bien que dans un nombre de cas non négligeable, les responsabilités de DPO et de responsable de l’archivage soient exercées par les mêmes personnes.
Le document, coincé entre archives et donnéesEn 2015, l’historien Bertrand Müller écrivait ceci (dans un texte non publié mais que l’auteur m’avait transmis): « Ces deux notions [les données et l’archive] paraissent avoir désormais un destin lié bien que ce lien soit à la fois paradoxal et récent. Paradoxal, parce que ces deux notions ont envahi l’espace sémantique du web ; elles sont l’une et l’autre omniprésentes. En même temps, ces deux notions désignent aussi des choses ou des phénomènes différents entièrement redéfinies par les pratiques numériques ».
Le document est sorti du débat…
Si le document disparaît, qu’archivera-t-on demain?
Des données?
Traditionnellement les archives sont définies comme des « documents » produits dans l’exercice d’une activité présentant un intérêt de conservation (cette formulation est un résumé de l’article 1 de la loi sur les archives de 1979). Lors de la révision de la loi sur les archives en 2008 (intégrée dans le code du patrimoine créé lui-même en 2004), on reste sur l’équivalence « archives=documents » avec une acception large de la notion de document (tous supports, toutes formes…), le cercle étant réduit par la qualité et la finalité des documents qui en font des « documents d’archives ».
Les données n’apparaissent dans définition légale des archives qu’en 2016 (il y a cinq ans, deux ans avant le RGPD) avec l’article 59 de la loi n°2016-925 du 7 juillet 2016 qui remplace « Les archives sont l’ensemble des documents, quels que soient leur date… » par « Les archives sont l’ensemble des documents, y compris les données, quels que soient leur date… ». On voit que le sujet est expédié par une brève incise qui laisse perplexe. Faut-il entendre que les données sont un sous-ensemble des documents ? Ou bien que les documents comprennent forcément données et on le mentionne juste en passant pour ceux qui en doutent? Ou encore que les documents d’archives sont composés pour certains de données, d’autres pas? Dans ce cas, les données qui ne sont pas incluses dans un document ne seraient pas des archives, ne seraient pas archivées? On aimerait en savoir plus et la question mérite d’être développée dans un environnement où la grande majorité de l’information susceptible d’être archivée est produite avec des technologies numériques.
Attendons.
Les archivistes, par ailleurs, s’intéressent à la donnée dans la réflexion, menée avec les chercheurs, sur l’exploitation des archives à l’aide des technologies. Les historiens, comme les archivistes du reste, travaillent depuis longtemps en utilisant des bases de données, alimentées par l’analyse et l’étude des documents d’archives. Ce fut le sujet de la journée d’études organisée en juin 2019 par le groupe régional Aquitaine de l’Association des archivistes français, en partenariat avec l’axe E3D du MICA Université Bordeaux-Montaigne. Le titre du colloque: « Le document, parent pauvre de la donnée. À la recherche du fonds d’archives perdu » est particulièrement alléchant avec son tryptique document-donnée-archives. L’approche est nouvelle, exploratrice, et on peut comprendre qu’elle commence par s’intéresser aux fonds d’archives existants, déjà collectés, constitués sur des supports analogiques, avant l’entrée dans le monde du tout numérique. L’expérience, et pour cause, porte davantage sur la numérisation d’archives papier (démarche postérieure à la production d’archives) que sur la fabrication de « documents » nativement numériques. Cependant il est intéressant de voir l’articulation entre les documents d’archives et les données qu’on peut en extraire, avec la projection possible du processus en sens inverse, des données vers les documents.
La brochure rédigée en 2017 par Gilbert Coutaz, avec la collaboration de Gilles Jeanmonod, et intitulée « La place de la donnée personnelle dans les archives historiques, essai d’interprétation à travers les archives de santé aux Archives cantonales vaudoises » (40 pages), propose une réflexion au carrefour de l’archivistique et du droit, plus précisément au carrefour de l’archivistique et de la réglementation sur la protection des données personnelles. Au moment où le texte a été rédigé, les archivistes européens ont fait entendre leur voix face au projet de réglementation européenne (le futur RGPD) et face à certaines interprétations radicales du droit à l’oubli conduisant à la destruction irrémédiable d’archives ou à la non-conservation d’archives qui sont pourtant, dans leur dimension de trace des vies individuelles, des sources irremplaçables de l’histoire collective. L’étude aborde « la place de la donnée nominative dans les processus d’archivage et l’ensemble du cycle de vie des documents partant de son élaboration à son sort final, soit élimination, soit versement aux Archives à des fins patrimoniales et de recherche historique ». Citant le rapport d’un groupe d’historiens sur l’histoire et les archives médicales publié en 2002, les auteurs rappellent que l’évaluation des documents contenant des données personnelles présuppose que l’on propose ces documents à l’archivage avant de pouvoir évaluer la pertinence de leur conservation. Reste à voir comment a évoluée la production de l’information médicale depuis deux décennies, entre les fichiers numériques qui s’affichent comme les héritiers des documents papier de naguère et les bases de données de santé alimentées par des flux permanents, partagées, connectées, « travaillées »… En attendant, le comptage dans ce texte des occurrences des trois mots en cause donne: donnée(s): 185; archives: 251; document(s): 50.
Partie 1 (Le règne de la donnée) – Partie 3 (à venir)
L’article Les données ont-elles évincé ou éclipsé les documents? 2/3 est apparu en premier sur Le blog de Marie-Anne Chabin.
Les données ont-elles évincé ou éclipsé les documents? 1/3
Les données. Nos données. Les données de l’entreprise. Les données ouvertes. Les données personnelles. Web de données… Les données sont partout. C’est le règne de « la donnée ».
 Le mot données figure dans un nombre croissant de titres de presse et d’articles de revues ou de blogs.
Le mot données figure dans un nombre croissant de titres de presse et d’articles de revues ou de blogs.
Voici une sélection de titres d’articles des dernières années abordant les nombreuses facettes de la donnée (liste chronologique et un peu longue mais la matière est riche et la lecture passionnante; à noter aussi que l’anglicisme « data » a été exclu de la sélection, tant pis pour les Franglish!):
Je suis mort. Comment transmettre mes données en héritage ? (février 2014)
Le piratage de Yahoo! est le plus important vol de données de l’histoire (décembre 2016)
Aux Etats-Unis, un refuge pour les données en danger (février 2017)
La Norvège crée un coffre qui protègera les données en cas d’apocalypse (avril 2017)
Une copie d’examen manuscrite est-elle un ensemble de données à caractère personnel ? (septembre 2017)
Les données des entreprises françaises éparpillées aux 4 vents (octobre 2017)
La Société Générale dévoile son plan de bataille sur la donnée (datalake) (novembre 2017)
Qui est le propriétaire des données de ma santé ? (février 2018)
La donnée est-elle le nouveau pétrole ou un nouvel environnement ? (mai 2018)
1 entreprise sur 2 ne sait pas où sont stockées ses données sensibles ! (juillet 2018)
La protection des données, un enjeu essentiel pour l’organisation interne de l’entreprise (juillet 2018)
La classification des connaissances et le web de données : une opportunité pour la recherche (octobre 2018)
Supprimer les données reste un enjeu pour l’entreprise (octobre 2018)
Danone : « dans l’usage de la donnée, il faut passer d’abord par la case business » (novembre 2018)
Et si vous archiviez vos données dans le cloud (MagIT) (novembre 2018)
La Transformation Digitale Est Celle De La Donnée Partagée (novembre 2018)
Big Data : le volume de données mondial multiplié par 5 d’ici 2025 (décembre 2018)
Fragmentation des données secondaires : un problème historique, de nouvelles solutions (février 2019)
« Gardez la maîtrise de vos données ! », lance Thierry Breton, PDG d’Atos (mars 2019)
Gouvernance des données et algorithmes publics : quelle stratégie pour l’État ? (mai 2019)
La qualité de la donnée au cœur de la modernisation des infrastructures (mai 2019)
Paris se dote de sa propre infrastructure pour héberger les données de ses administrés (mai 2019)
La donnée “non-personnelle” (anonyme) existe-t-elle ? (août 2019)
Peut-on payer avec ses données personnelles ? (septembre 2019)
Intelligence artificielle et bases de données : que dit le droit ? (octobre 2019)
La lutte contre le terrorisme ne justifie pas la conservation généralisée des données personnelles (janvier 2020)
Le gouvernement américain investit dans le stockage de données dans l’ADN (mars 2020)
Données non-effacées des terminaux : une faille de sécurité par négligence (mars 2020)
Data analysis, la science des données est devenue un art (mai 2020)
La Sécurité intérieure américaine va extraire encore plus de données des appareils aux frontières (août 2020)
Peut-on encore héberger légalement ses données dans le cloud ? (novembre 2020)
Cyberattaques : voici les différentes méthodes criminelles pour voler des données (mars 2021)
Savoir-faire en matière de destruction des données (avril 2021)
Peu d’entreprises parviennent à exploiter correctement les données en améliorant leur qualité et leur traitement (avril 2021)
Notre clinique des données intéresse beaucoup les autres hôpitaux français (mai 2021)
Comment protéger ses données, si on ne sait même pas où elles sont! La cartographie des données (juillet 2021)
Une brève histoire de la donnée publique (août 2021)
Afghanistan : quand la protection des données biométriques devient une question de vie ou de mort (septembre 2021)
Vos données ne valent pas grand chose mais le problème n’est pas là ! (septembre 2021)
Pourquoi et comment visualiser la donnée pour augmenter la performance de votre entreprise (octobre 2021)
etc.
Mais qu’est-ce qu’une donnée?Cette floraison – ou intrusion des données sur le devant de la scène (selon le point de vue où on se place) – suscite quelques questions:
- à quoi renvoie exactement le mot « données » (au pluriel ou au singulier)?
- qu’est-ce qui n’est pas « donnée »?
- les données sont-elles une création récente, originale, inédite ou sont-elles une métamorphose d’une réalité préexistante?
- quel est le lien entre les données et les documents dont on parlait naguère: les documents personnels, les documents de l’entreprise, l’accès aux documents, le classement des documents, etc.?
- les données ont-elles évincé ou vont-elles évincer pour de bon les documents de la scène informationnelle, les envoyant ad patres ou ad matres (i.e. aux archives), ou bien assiste-t-on à une simple éclipse temporaire des documents sous leurs atours des dernières décennies en attendant leur résurgence, drapés dans de nouveaux habits numériques?
L’étude de la première question (qu’est-ce que la donnée? Que sont les données ?) conduit assez vite au constat d’un décalage flagrant entre les définitions existantes, généralistes ou techniques, et ce que l’on peut imaginer en parcourant la liste de titres ci-dessus, qu’on la lise comme un digest de la problématique des données au 21e siècle ou comme un poème des temps nouveaux.
Les dictionnaires de langue, tout en restant précieux pour l’histoire du mot, sont manifestement dépassés sur l’usage actuel des données (les dictionnaires suivent toujours l’usage mais sur ce coup-là, ils semblent prendre du retard).
Le dictionnaire de l’Académie française indique données comme un terme de mathématique à partir du 18e siècle (les données d’un problème à résoudre).
La définition qui en découle, la plus courante aujourd’hui, renvoie à la notion de raisonnement: « Ce qui est connu et admis, et qui sert de base, à un raisonnement, à un examen ou à une recherche » (CNRTL) et on trouve la même idée chez Larousse, Wikipédia ou Robert.
Diverses publications scientifiques et techniques proposent des définitions, comme le site www.techno-science.net qui dit: « Dans les technologies de l’information (TI), une donnée est une description élémentaire, souvent codée, d’une chose, d’une transaction d’affaire, d’un événement, etc. Les données peuvent être conservées et classées sous différentes formes : papier, numérique, alphabétique, images, sons, etc. ».
On est passé, et tout le monde l’a bien constaté, des mathématiques à l’informatique.
Les glossaires qui proposent une définition de données (ou recopient celles des dictionnaires ou celles d’autres glossaires) sont assez nombreux et il n’y a pas de valeur ajoutée à en faire la liste. Pour ma part, je m’en tiens à la définition originale que donne la norme OAIS publiée en 2001 (devenue ISO14721), relative à la pérennisation des données scientifiques (Open Archival Information System). La norme OAIS dit ceci: « Données (Data) : une représentation formalisée de l’information, adaptée à la communication, l’interprétation ou le traitement. Exemple : une séquence de bits, un tableau de nombres, les caractères d’une page, un enregistrement de paroles ou un échantillon de roche lunaire ». Définition d’autant plus intéressante qu’elle fait écho à la définition du mot information que l’on associe trop souvent à données sans savoir bien expliquer la différence entre les deux notions. OAIS précise donc qu’une information est « toute connaissance pouvant être échangée. Lors de l’échange, elle est représentée par des données. Exemple : une chaîne de bits (les données) accompagnée d’une description permettant d’interpréter cette chaîne de bits comme des nombres représentant des mesures de températures en degrés Celsius (Information de représentation) ».
Cette définition de données par l’OAIS a inspiré celle que j’ai formulée dans mon Nouveau glossaire de l’archivage (2010): « Donnée: Mot, nombre, signal, chaîne de caractères, séquence de bits, morceau de matière ou tout autre élément brut enregistré dans un système d’information où il pourra être corrélé à d’autres objets et interprété pour constituer une information », avec le commentaire suivant: Une donnée n’est qu’une composante d’une information ou d’un document. Archiver des données élémentaires n’a donc pas de sens, à l’inverse de l’opération de sauvegarde qui a pour but de restituer les éléments du système en cas de panne ». Mais je reviendrai ultérieurement sur la notion de document.
Il est manifeste que l’on est passé depuis le début du 21e siècle du domaine de l’informatique à ceux de l’économie, de la vie quotidienne, de la gouvernance des populations. C’est vaste. De sorte que les « autorités compétentes » (hum…) seraient bien inspirées de s’emparer du sujet pour proposer une définition qui réponde, disons à au moins 90% des sens réels des mots données (au pluriel) ou donnée (au singulier) dans les publications d’aujourd’hui. Ceci éviterait peut-être aux uns et aux autres de publier des définitions « sottes et grenues » telle que celle qu’on peut lire à la fin du dernier ouvrage d’Aurélie Jean, Les algorithmes font-ils la loi ? (éditions de l’Observatoire) dont le lexique final propose: » Data : c’est une information sous forme de données qui décrivent un individu, une personne morale, un pays, une société, un objet ou encore un scénario », énoncé aussi choquant au plan linguistique que technique (à croire que l’autrice n’a pas relu les épreuves…).
La plupart des définitions glissent malheureusement sur la différence entre singulier et pluriel, entre donnée et données, en prenant l’anglais data pour un féminin singulier (syndrome de rosa, rosa, rosam…) alors que c’est, comme en latin, un neutre pluriel (pour ne pas évoquer l’affreux barbarisme « datas » – avec un « esse » pour pendre les écorcheurs d’orthographe?). Cela dit, au-delà de la donnée élémentaire (data element, en anglais, est singulier de data qui, je me répète, est un pluriel), il faut reconnaître l’usage croissante de donnée en tant que singulier collectif comme on dit « la voiture électrique », « le vaccin », « la bande dessinée ».
Pour poursuivre, je vais comparer l’utilisation du mot données à l’utilisation (ou la non-utilisation) du mot documents.
Partie 2/3 : Les données éclipsent les documents (bientôt en ligne).
L’article Les données ont-elles évincé ou éclipsé les documents? 1/3 est apparu en premier sur Le blog de Marie-Anne Chabin.
Lecture de « L’enfer numérique » de Guillaume Pitron
Le livre de Guillaume Pitron, Guillaume Pitron, L’enfer numérique. Voyage au bout d’un Like (éditions LLL) est un des livres de la rentrée sur la question très actuelle des relations entre technologies et écologie. On y trouve de très nombreuses informations sur la question et de larges extraits des interviews réalisées par l’auteur auprès de divers profils d’acteurs de la société numérique. J’avoue cependant avoir été un peu frustrée par le style journalistique facilement superficiel (c’est long sur 300 pages) et également déçue que le sous-titre (« Voyage au bout d’un like ») ne donne pas lieu à une analyse plus poussée du phénomène like (mon attente était sans doute trop exigeante en tant que contributeur au MOOC « Le mail dans tous ses états » proposé par le CR2PA en 2017). Ce que je retire positivement de cette lecture, et que j’ai envie de partager ici, concerne trois sujets: la matérialité du numérique, les coulisses de l’empreinte écologique du numérique, et les comportements des utilisateurs face à l’enfer numérique (dans l’illustration, l’enfer tout court vu par Jérôme Bosch).
 Matérialité du numérique
Matérialité du numérique
Immatériel. Dématérialisation. Enfin, on en revient!
On nous a rebattu les oreilles dans les années 1990 et encore en 2000 du caractère immatériel du numérique: les supports étaient « virtuels », les données étaient dans les nuages (cloud) que chacun se représentait de manière plus ou moins éthérée.
Je me rappelle fort bien comment, il y a dix ou quinze ans, de nombreux utilisateurs et décideurs étaient convaincus de la nature virtuelle du numérique et de la possibilité de s’affranchir des problèmes de stockage et des coûts associés puisqu’on pouvait stocker toute la documentation technique d’un avion comme le Rafale sur un simple disque compact alors que pour transporter l’ensemble des mêmes documents sous forme papier il eût fallu un semi-remorque (j’ai entendu cette comparaison au milieu des années 1990).
Je note aussi que, quand j’évoque avec mes étudiants cette « ancienne » croyance que les données ne sont nulle part vu qu’il n’y a plus de support, ils rigolent car ils savent très bien que « si les données ne sont pas dans ton ordinateur, c’est qu’elles sont dans celui de quelqu’un d’autre! ».
Le livre de Guillaume Pitron est à cet égard très clair. La « dématérialisation est impossible sans matière » (p. 61). Les 34 milliards de smartphones et d’ordinateurs utilisés sur terre sont bien des appareils tangibles, produits à l’aide de matières extraites de la croute terrestre. Et il y a les datacenters (trois millions aujourd’hui dans le monde, cf p. 115), constructions austères ou usines réaffectées qui ressemblent plus à des bunkers qu’à des cumulonimbus. Et les câbles sous-marins sans qui la transmission des données est réduite à pas grand-chose sont bien réels eux aussi; ce sont eux les véritables « autoroutes de l’information » (l’annexe 10, p. 338, montre la carte mondiale des câbles sous-marins en 2021, et il faudra la mettre bientôt à jour car la guerre des câbles n’est pas terminée).
Les quelques pages dédiées à l’Estonie, réputée pour être le plus numérique des pays européens, exposent les motifs de cette croyance collective à l’immatérialité du numérique. Trois discours convergent vers la « dématérialisation »: tout d’abord, il y a comme un quiproquo sur ce dont on parle car l’absence de matière ne réside que dans la perception de l’utilisateur qui ne peut pas toucher ce qu’il voit; l’écran est l’instrument de la dématérialisation car il met une barrière entre l’information et la matérialité du support; l’objet matériel s’efface derrière le service et l’information, ce que l’on peut résumer par la formule: on ne vend plus de disque, on fournit de la musique. Le discours marketing abonde dans le même sens: le cloud virtuel est plus séduisant que le bunker surchauffé; là, encore, la formulation est orientée vers l’utilisateur (ce qui est, il est vrai, le rôle du marketing). Tout ceci est encore conforté par l’idée que les outils numériques finaux (smartphone, tablette) sont de beaux objets et qu’un bel objet ne saurait être associé à quelque chose de moche ou de sale tels que les sites de stockage ou les mines d’extraction de métaux.
Les coulisses de l’empreinte écologique du numériqueLes technologies numériques ont, depuis l’origine, suscité des interrogations, en plus des craintes et réticences inhérentes à tout progrès technique. Et ces interrogations évoluent, au fur et à mesure des solutions apportées par les technologies elles-mêmes ou reformulées par le contexte global d’utilisation. À la fin des années 1990 et au cours de la décennie suivante, on se préoccupait particulièrement de la pérennité des données numériques (« Pourrons-nous relire nos documents dans dix ans? » titrait le Monde presque chaque année); on cherchait à savoir comment les technologies numériques pourraient résoudre la question de l’obsolescence des formats d’encodage des données, etc.
Aujourd’hui, dans la gouvernance de l’information, ce sont la protection des données personnelles et la cybercriminalité qui dominent, mais la question de l’empreinte écologique du numérique dans le contexte du grand combat pour le climat gagne des « parts de marché »; c’est la question qui est au centre du livre de Guillaume Pitron.
En 2021, tout internaute a plus ou moins entendu parler de l’impact écologique du numérique au travers de l’émission de CO2 des appareils numériques, à côté de l’impact écologique des moyens de transports et de chauffage. Les slogans sur l’impact écologique d’un mail viennent remplacer les avertissements « N’imprimez pas ce mail, sauvez un arbre! » qui clôturaient les messages électroniques au cours de la précédente décennie.
Cependant, limiter l’empreinte écologique à l’émission de CO2 d’un appareil est très restrictif, ainsi que l’explique l’ouvrage, car c’est faire fi de ce qui s’est passé avant cette émission polluante, c’est ignorer ce qu’a coûté à la Terre la fabrication dudit appareil. Il y aurait donc une unité de mesure plus juste, plus globale. C’est le MIPS pour Material input per service unit, qui prend en compte la quantité de ressources nécessaires à la fabrication d’un produit ou d’un service, ressources utilisées (matières premières) mais aussi consommées (combustibles, eau, électricité), d’autant qu’une bonne partie de l’électricité de la planète est produite à partir du charbon… Avec ce système, on dira qu’un kilomètre en voiture coûte 1 kg de ressources, un SMS coûte 0,6 kg, tandis que 183 kilogrammes de matières sont nécessaires à la fabrication d’un smartphone de 150 grammes. À l’échelle d’un datacenter, ce qui entre en ligne de compte, c’est la consommation d’eau et d’électricité qui, dans certains cas (exemples cités pour les USA et pour les Pays-Bas, p. 134 et p. 154), pourrait se faire au détriment de la fourniture d’énergie aux populations.
Le MIPS s’évalue en kilogrammes, avec un système de calcul qui gagnerait à être explicité davantage car on additionne des matières premières avec des combustibles ou de l’eau… Cela dit, cette vision de la réalité met clairement en lumière la contradiction de ceux qui ont renoncé au bifteck pour sauver la planète mais changent régulièrement leur smartphone ou visionnent quotidiennement des films sur leur smartphone avec la 5G.
L’augmentation fulgurante des données contribuent aussi à augmenter l’empreinte écologique globale, en raison du développement des infrastructures qu’elle impose: nouveaux câbles, nouveaux datacenters, etc.
Citant Frédéric Bordage (Sobriété numérique, les clés pour agir, Buchet Chastel, 2019), Pitron fait remarquer que le poids d’une page Web a été multiplié par 115 entre 1995 et 2015, c’est-à-dire en vingt ans. Selon une estimation de 2018, chaque internaute génère 150 Gigaoctets chaque jour (p. 129). Autre exemple: une voiture connectée, équipée d’environ cent cinquante calculateurs, peut produire plus de 25 Go de données par heure (p. 217).
Certes les avancées technologiques permettent de gagner en efficacité et en temps, d’où l’on pourrait déduire de possibles réductions de l’empreinte écologique. C’est sans compter sur la réalité des comportements humains, en tout cas jusqu’à présent, car on ne voit guère de signes de décroissance de cette empreinte écologique du numérique. On constate que la consommation électrique du numérique continue d’augmenter de 5-7 % chaque année (p. 39).
Comportements des utilisateursL’ouvrage de Guillaume Pitron ne développe pas les aspects comportementaux car ce n’est pas son propos principal mais la part de l’humain dans l’avenir des usages des technologies est abordée à plusieurs reprises.
La prise de conscience de la pollution numérique ou du moins de son impact sur la consommation des ressources de la planète, et l’inégalité induite de la distribution de ces ressources, conduisent à certaines initiatives de la part des utilisateurs. Elles sont de deux ordres: d’une part, des consommateurs ou des associations de consommateurs voire des associations d’entreprises militent pour une sobriété numérique, pour une maîtrise de la production, pour des appareils durables et recyclables, pour la fabrication maison (les « makers ») et la réparation (à cet égard, voir par exemple le site de l’Institut du numérique responsable); d’autre part, des pouvoirs publics confrontés à la menace que peut représenter l’appétit de l’ogre numérique pour les besoins quotidiens des populations, par exemple avec la campagne du républicain Marc Roberts pour refuser la fourniture d’eau nécessaire au datacenter que la NSA a installé en 2013 à Bluffdale dans l’Utah (p. 134-138); dans cette affaire, c’est le pouvoir fédéral qui a gagné contre le pouvoir local, et il faut admettre que les États eux-mêmes pèsent de moins en moins face aux GAFAM…
D’autres formulent l’espoir que les technologies trouvent encore et toujours une réponse aux problèmes qu’elles créent (création de datacenters sous-marins, informatique quantique, stockage des données avec l’ADN, etc.), ce qui n’est pas encore avéré. À noter également les controverses d’experts et d’industriels sur les analyses d’impact de telle ou telle technologie, par exemple sur le coût écologique d’un véhicule électrique, avec la contre-enquête de Marc Müller dans le film Contresens.
La sobriété triste, c’est-à-dire contrainte par la réglementation, est-elle possible? Dès lors que la possibilité technologique existe, il paraît illusoire de limiter son usage par les utilisateurs, même par la force, d’autant que la question n’est pas nationale mais mondiale. Une anecdote rapportée par Guillaume Pitron est révélatrice de cette situation « infernale »: en 2010, Facebook, sollicité par Suède, décide d’installer un datacenter à Lulea, dans le nord de la Suède où les centrales hydroélectriques apportent l’énergie nécessaire; le datacenter est mis en service en 2013 et stocke les données des utilisateurs européens (ce qui évite effectivement aux données européennes de traverser l’Atlantique à longueur de journées). Or, la centrale hydroélectrique de Lulea fonctionne grâce au barrage de Letsi construit dans les années 1960 au détriment de l’inondation de six kilomètres de vallée. Un vieux monsieur, nostalgique du fleuve de son enfance qui a disparu, partage ses photos d’antan sur Facebook…
Le discours militant pour la diète numérique a quelques adeptes: idée d’un World Digital Cleaning Day lancé en 2020 par l’Estonienne Anneli Ohvril, consistant à se mobiliser une journée au travail pour nettoyer ses espaces de stockage personnel ou de proximité ; c’est ailleurs la recommandation de regarder une vidéo en WiFi plutôt qu’avec la 4G car c’est 23 fois moins énergivore, etc. Qui est prêt à se mortifier en regardant les autres s’envoyer dans les nuages ?
Pourtant, la « politique des petits gestes » (p. 198) ne semble pas pour l’instant porter de grands fruits : les cleaning days – qui n’ont pas attendu le numérique et qui sont pratiqués en France « en papier » depuis dix-quinze ans – sont partiellement efficaces et parfois festifs mais restent du curatif tandis que le préventif piétine.
Une piste qui n’est pas évoquée dans l’ouvrage mériterait d’être étudiée : ce serait non pas de limiter autoritairement l’accès à Internet pour les utilisateurs mais que les utilisateurs n’aient plus envie d’autant d’Internet. Passer de la frustration face à un modèle idéalisé mais bridé à l’adhésion à un autre modèle. Difficile toutefois aujourd’hui de proposer quelque chose à la collectivité sans passer par les réseaux sociaux et, conséquemment, rester piéger dans les tentacules auxquelles on tente d’échapper.
L’enfer a toujours un côté séducteur. Et l’expérience humaine d’une génération sert rarement aux générations suivantes.
Par ailleurs, que se passera-t-il le jour (peut-être déjà là) où la majorité des données produites sera le fait exclusif de robots indifférents aux états d’âme des humains ?
À suivre.
L’article Lecture de « L’enfer numérique » de Guillaume Pitron est apparu en premier sur Le blog de Marie-Anne Chabin.
Illustration du vol de données
À la mi-septembre 2021, un certain nombre de médias relayait l’information selon laquelle l’Assistance publique-Hôpitaux de Paris (AP-HP) avait été victime d’une attaque informatique (cyberattaque) au cours de l’été. Agression réussie puisque les pirates ont dérobé les données d’environ 1,4 million de personnes, données collectées dans le cadre d’un test de dépistage du Covid19 dans le courant l’année 2020. La faille technologique qui a facilité le vol ne concerne pas les applications informatiques de l’AP-HP mais un serveur de partage de fichier (un prestataire externe en quelque sorte) utilisé pour accélérer la transmission des données de dépistage à l’Assurance maladie dans le but d’optimiser le « tracing ». Pourtant, le Règlement général pour la protection des données personnelles (RGPD) dit très clairement que la sécurité informatique ne doit pas se limiter aux systèmes internes mais aussi à celui des sous-traitants, même quand on est pressé…
Il s’agit là d’une énième attaque au rançongiciel dont la litanie jalonne les sites spécialisés dans la sécurité informatique. Un énième incident dans une série en croissance de piratages massifs de données. Les autorités s’inquiètent et se mobilisent sans pouvoir stopper la vague des cyberattaques. Les prévisions sont alarmistes: « Une grande crise est possible et comporte un risque systémique » déclare Guillaume Poupard, directeur général de l’ANSSI. La CNIL estime quant à elle que les violations de données personnelles vont doubler en 2021. Et le criminologue et orateur Alain Bauer déclarait déjà il y a dix-huit mois: « Le prochain virus sera cyber« .
On peut se demander si les petites entreprises, les collectivités locales, la population en général ont vraiment pris la mesure du phénomène. L’attaque de l’AP-HP, du fait qu’elle touche à la santé de tous, est peut-être de nature à sensibiliser davantage bien que les cyberattaques d’hôpitaux ne sont pas tout à fait nouvelles (attaque de l’hôpital de Marmande à l’été 2020 et des hôpitaux de Dax et de Villefranche-sur-Saône en février 2021) mais avec l’AP-HP, on monte encore d’un cran. Pour ceux qui en douteraient encore, non les pirates ne sont pas gênés de s’en prendre aux hôpitaux qui, au contraire, peuvent potentiellement rapporter plus car plus fragiles que certaines entreprises qui se protègent mieux. Pas d’état d’âme dans la cybermalveillance.
Le point positif – si j’ose dire – est que cette cyberattaque de l’AP-HP n’a pas bloqué le fonctionnement du système informatique de l’hôpital (voir la notion de déni de service) et a « simplement » siphonné le contenu d’une bases de données. Les données personnelles des personnes testées se trouvent vraisemblablement à vendre sur le dark web, avec des milliards d’autres. Ça ne se voit pas et le problème n’en est que plus insidieux.
Comment sensibiliser l’ensemble des acteurs économiques et l’ensemble de la population à ce danger quand on a du mal à visualiser le risque? Le vol de données, n’est pas très concret. Si on me vole ma voiture, je le vois et j’en subis immédiatement les conséquences: déclaration à l’assurance, plainte, location d’une voiture, annulation ou déplacement de rendez-vous, etc. Mais si on me vole mes données… D’abord, je les ai encore (c’est un peu comme si ma voiture existait en cinquante ou cent exemplaires sans souci de parking, ou presque… ). Ensuite, ça ne m’entrave pas dans la poursuite de mes activités. Du moins pas systématiquement, pas tout de suite, pas directement. C’est après que ça peut être l’enfer, avec une usurpation d’identité, un vol de coordonnées bancaires par phishing (hameçonnage), etc. On pourrait comparer au vol de vos clés d’appartement; même si vous avez un double et que vous pouvez rentrer chez vous, vous risquez un cambriolage; vous allez bien sûr changer la serrure, mais on ne peut pas changer son numéro de sécurité sociale… pas encore en tout cas…
Comment convaincre du risque quand il n’est pas immédiatement visible?
Mon propos ici n’est pas de revenir sur le détail du piratage, sur ses causes et ses conséquences, cela a déjà été fait (voir par exemple l’article des Échos, celui de l’Express ou celui de Numerama qui est le plus fouillé).
Mon billet s’intéresse tout simplement à la façon dont les médias donnent à voir ce problème aux internautes car, on le sait, l’information textuelle glisse si elle n’est pas accrochée à une image dont le rôle est d’accrocher l’œil (notamment lors des partages sur les réseaux sociaux) et de favoriser la visualisation du message.
Plusieurs dizaines de médias ont relayé cette cyberattaque de l’AP-HP. J’en ai parcouru une vingtaine. Le plus souvent, il s’agit d’un copié-collé de la dépêche AFP, présentée dans la rubrique « société » ou bien dans la rubrique « santé », ou encore dans la rubrique « technologies » et parfois – quand même – dans la rubrique « sécurité informatique » (qui ne devrait pas intéresser que les informaticiens – à renommer peut-être?).
Or, la dépêche de l’AFP n’inclut pas d’image. La relayer exige d’ajouter une image, une image dite « prétexte » qui paraîtra « à la une », l’élément que le lecteur, l’internaute verra en premier, qui devra attirer son regard, qui restera mentalement le support visuel de l’information délivrée. L’image retenue, dans la limite de la banque d’images utilisées, est censée illustrer le vol de données, ou l’évoquer au mieux, disons au moins mal.
L’objet de mon billet est donc de regrouper les différentes images choisies par les uns et les autres pour « supporter » la nouvelle de la cyberattaque de l’AP-HP.

 La question se pose de l’efficacité de ces images, entre les écouvillons, les soignants, les cartes vitales, les murs de l’hôpital et les écrans d’ordinateurs.
La question se pose de l’efficacité de ces images, entre les écouvillons, les soignants, les cartes vitales, les murs de l’hôpital et les écrans d’ordinateurs.
N’y aurait pas intérêt à réfléchir plus sérieusement à cette question?
L’article Illustration du vol de données est apparu en premier sur Le blog de Marie-Anne Chabin.
Citations de Georg Christoph Lichtenberg
Georg Christoph Lichtenberg est un philosophe allemand du XVIIIe siècle dont l’œuvre principale, vue d’aujourd’hui, est la rédaction au quotidien de ses Cahiers sous forme d’aphorismes et de réflexions personnelles, cahiers tenus entre 1764 et 1799, année de sa mort.
Un auteur, par ailleurs sinologue que j’affectionne particulièrement pour sa conception de la traduction, à savoir Jean-François Billeter, publié il y a deux ans aux excellentes éditions Allia une sélection des observations de Lichtenberg, choisies en fonction de son propre intérêt et traduites en français par ses soins (la notice Wikipédia sur Lichtenberg, qui n’était pas à jour sur ce point, l’est maintenant, à la suite de ce billet, merci).
J’en reprends ici quelques-unes dont la lecture et l’actualité m’ont sinon confortée dans mon analyse de la société de l’information, du moins convaincue qu’elles méritaient d’être largement partagées. À noter que les références alphanumériques sont celles de l’édition allemande des Cahiers.
Citations:
Résiste à la contagion, ne donne pas pour tienne l’opinion d’un autre avant d’avoir jugé qu’elle te convient; aie de préférence la tienne propre. (D121)
Les gens qui ont beaucoup lu font rarement de grandes découvertes. Je ne dis pas cela pour excuser la paresse, car faire des découvertes exige qu’on l’on observe par soi-même beaucoup de choses. Il faut plus voir soi-même que se laisser dire. Association. (E467)
On prévient aussi le malentendu quand on apprend aux hommes comment penser, et non pas sempiternellement quoi penser. C’est là une sorte d’initiation aux mystères de l’humanité. Celui qui, pensant par lui-même, aboutit à une proposition bizarre s’en détachera tôt ou tard si elle est fausse, mais quand une proposition bizarre est enseignée par un homme respecté, elle peut induire en erreur par milliers ceux qui ne réfléchissent pas. […] (F441)
Chez nos poètes à la mode, on voit si bien comment les mots produisent la pensée. Chez Milton et Shakespeare, c’est toujours la pensée qui donne naissance aux mots. (F496)
Il faut un temps à Rome où on élevait mieux le poisson que les enfants. Nous élevons mieux les chevaux. Il est tout de même étrange que l’écuyer qui présente les chevaux à la cour reçoive une solde de milliers d’écus et que ceux qui lui amènent ses sujets, les maîtres d’école, crèvent de faim. (H133)
Je considère les comptes rendus comme une sorte de maladie infantile qui touche plus ou moins les livres nouveau-nés. On voit que parfois les plus robustes en meurent et que souvent les plus faibles s’en tirent. Certains ne l’attrapent pas du tout. On a souvent essayé de les protéger par les amulettes des préfaces et des dédicaces, et même de les vacciner par des jugements de l’auteur lui-même, mais cela n’est pas toujours suivi d’effet. (J854)
J’ai souvent été blâmé pour des fautes que mon censeur n’avait ni l’énergie ni l’esprit de commettre. (K37)
Quand on considère la nature comme la maîtresse d’école et les pauvres humains comme ses élèves, on est porté à se faire une bien curieuse idée de l’espère humaine. Nous sommes tous assis dans une même salle de classe, nous avons les principes nécessaires pour comprendre le cours et l’assimiler, mais nous préférons écouter le babillage de nos camarades plutôt que l’exposé de la maîtresse. Ou quand l’un de nos voisins note quelque chose, nous copions, nous lui volons ce qu’il a peut-être mal entendu et nous y ajoutons nos propres erreurs d’orthographe et d’opinion. (K70)
Dans beaucoup de sujets d’études, il n’est pas mauvais de réfléchir d’abord dans un léger état d’ébriété, en prenant des notes; puis de tout terminer de sang-froid et en raisonnant posément. Une certaine élévation due au vin favorise les sauts de l’invention et de l’expression; seule la raison tranquille assure l’ordre et la méthode. (K181)
Pour mesurer tout ce qui dans le monde dépend de la présentation, il suffit de voir du café servi dans des verres à vin, ce qui en fait une boisson misérable, ou de la viande découpée à table avec des ciseaux, ou même, ce que j’ai vu une fois, du pain beurré avec un vieux rasoir, quoiqu’il fût tout à fait propre. (L504)
Si on ne se souvenait pas de la jeunesse, on ne sentirait pas l’âge. Le mal vient seulement de ce qu’on n’est plus en état de faire ce qu’on faisait alors. Car le vieillard est assurément un être aussi parfait en son genre que le jeune homme. (L535)
L’article Citations de Georg Christoph Lichtenberg est apparu en premier sur Le blog de Marie-Anne Chabin.
Proposition féministe?
Les temps/l’époque étant ce qu’ils/elle sont/est, je précise aux lecteurs.trices trop sérieux.ses que ce billet/cette proposition est aussi « modeste » que badin.e.
Le combat soutenu des mouvements féministes a conduit récemment à faire adopter l’expression « égalité femmes-hommes » à la place de la formule « égalité hommes-femmes » à laquelle l’oreille s’était habituée (« FAMOM » n’est pas très euphonique mais on comprend bien que c’est le fond qui l’emporte).
Cette inversion de l’ordre des mots suggère une revendication que je n’ai pas entendue dans le débat alors que toutes les femmes, et même les jeunes filles, et aussi les fillettes sont concernées. Il s’agit du numéro de sécurité sociale dont le premier des treize chiffres indique le sexe: 1 pour les hommes, 2 pour les femmes (laissons ici de côté l’usage des chiffres 3 à 9 qui est une autre histoire).
Ainsi – trois fois hélas – plus de la moitié de la population française (les femmes étant légèrement majoritaires) doit subir au jour le jour l’affront de se voir rappeler qu’elles viennent en second, qu’elles sont abonnées au numéro deux, que c’est la deuxième place qui leur est assignée et que la première place leur est interdite. Humiliation répétée à chaque fois qu’une femme remplit une feuille de soin, se connecte à son compte Ameli ou complète un formulaire administratif! Et pour les (rares) cas où c’est le conjoint qui remplit pour sa conjointe, on imagine l’effet désastreux de renforcement du sentiment du supériorité chez celui qui, lui, a le droit d’écrire un 1.
On aura beau jeu d’expliquer que ce désagrément trouve une compensation non négligeable dans les règles traditionnelles de la politesse et de la courtoisie selon lesquelles les femmes doivent passer devant (l’argument est étranger aux valeurs du militantisme féminin). Ou bien d’expliquer que ce numéro d’identification des individus a été créé à des fins militaires sur douze chiffres et que le treizième, en l’occurrence le premier, a été ajouté après coup à des fins administratives. Les faits sont là, sournois, insistants, et ils sont insupportables! N’est-il pas temps là aussi d’inverser un peu les choses pour rétablir une offense qui dure depuis trop longtemps? L’heure a sonné d’attribuer le 1 aux femmes! Mais que fait le gouvernement?
En cherchant un temps soit peu sur Internet – merci Wikipédia – j’ai appris que la question avait déjà été soulevée en 1985, justement par Yvette Roudy, ministre des Droits de la femme (mai 1981- 1986) durant le premier septennat de François Mitterrand. La ministre avait protesté auprès du directeur de l’INSEE en pointant la discrimination envers les femmes qui résulte de cette codification. L’INSEE avait alors botté en touche en se rangeant derrière la norme ISO/CEI 5218 de 1976 sur la représentation du genre. Mais une réponse plus perfide avait circulé officieusement, évoquant le code 0 en remplacement du 2, en insistant sur la charge négativement symbolique du 0 dans le but de refroidir les ardeures de la ministresse (dans ladite norme, le 0 signifie « inconnu »…).
La question a-t-elle été étudiée sérieusement, alors ou depuis?
Plusieurs questions se posent: quel système adopter? Comment le mettre en œuvre? À partir de quel date?
Sur le choix du système, le cabinet du directeur de l’INSEE de 1985 n’avait pas tort sur toute la ligne: remplacer le 2 par un 0 serait à coup sûr plus économique dans la mesure où, avec le doublet 0 (femmes)-1 (hommes), la presque moitié de la population n’aurait rien à changer à ses habitudes mais l’opération, on l’a compris, pourrait se révéler contre-productive en termes d’image. Pourtant, à l’heure des données numériques, codées comme chacun.e sait avec des 0 et des 1, il y aurait de quoi argumenter de la part des féministes et revendiquer le premier de ces deux symboles de l’écriture du monde moderne.
Les observateurs.trices auront remarqué que dans l’image pédagogique qui illustre ce billet, la légende du premier chiffre du numéro de sécurité commence par le 2 et finit par le 1: piètre consolation!
Une solution plus radicale consisterait à revenir à un numéro à douze chiffres (tant pis ou tant mieux pour les superstitieux – cochez la case de votre choix); en effet, qu’a-t-on besoin d’indiquer le sexe des individus/des personnes dans le registre national d’identification? On s’en passerait facilement. On pourrait encore suggérer cette solution réaliste et moins onéreuse de remplacer le 1er caractère par une lettre, F ou H, car F présente l’avantage naturel de se trouver avant H dans l’alphabet latin (évidemment, l’anglicisation ambiante pourrait balayer cet avantage…).
La mise en œuvre passe par le déploiement d’un gros projet national impliquant plusieurs ministères (économie, santé, intérieur…et évidemment égalité entre les femmes et les hommes). Le choix du prestataire est une première étape à ne pas négliger car si jamais l’appel d’offre public est déclaré infructueux, la réforme gouvernementale perdra en crédit. Le problème est que le projet requiert des compétences à la fois technologiques et communicantes pour mener parallèlement la réorganisation des outils de gestion administrative et l’adhésion de la population à ce nouveau geste quotidien de respect envers les femmes. En effet, il ne faut pas minimiser la communication sur la réforme: dans un pays où 70% des citoyens restent chez eux le jour des élections, quel pourcentage adhérera du premier coup à l’opération et fera un sans-faute jusqu’à l’adoption collective du nouveau réflexe? Pour aider à la manœuvre, on pourrait recruter des formateurs.trices et des accompagnant.e.s; bien sûr, ces emplois/activités ne seront pas pérennisables mais ils/elles présentent l’avantage de pouvoir être réalisé.e.s en télétravail (sauf cas/situations particulier.es).
Mais quid de la « reprise de l’existant » ou de la « reprise des données » comme on dit dans les projets de dématérialisation : que fait-on du stock?
Pour les feuilles de maladie et les notifications de remboursement de la Sécu, on peut évacuer le problème assez vite puisqu’elles sont généralement détruites dans les trois ans (article D253-44 du code de la sécurité sociale)
Pour les bulletins de paie, c’est plus gênant; en effet, avec une conservation à 50 ans de millions et millions de pages, la tâche de modification de la totalité de la masse ou du stock (laquelle/lequel est on ne peut plus dispersé.e entre les domiciles des salarié.e.s et les caves de leurs employeur.e.s) est inqualifiable avec les mots du dictionnaire: bénédictine, herculéenne, titanesque, abracadabrantesque…
Et pour le grand basculement dans les bases de l’INSEE et de la Sécurité sociale, il faut trouver un jour J précis, en anticipant au mieux un incident, une faille ou une cyberattaque qui bloquerait le système au point qu’on ne saurait plus revenir à l’état précédent et qu’il serait définitivement impossible de savoir qui est in et qui est out, enfin qui est 1 et qui est 2 (notons que cette analyse de risque milite en faveur d’un effacement complet du 1er caractère pour revenir à un numéro à douze chiffres).
Finalement, la question de la date du lancement de l’opération est peut-être le point le plus délicat: faudra-t-il suivre la logique de l’année civile et démarrer un 1er janvier (01/01)? On pourrait y voir de la part de la gent masculine une tentative de s’accrocher à son ancien privilège. Toute date correspondant soit à un jour pair soit à un jour impair, toute proposition pourra être instrumentalisée à leur profit par les pros et les cons, je veux dire les pour et les contre la réforme.
Que faire? On pourrait peut-être créer une commission Théodula?
L’article Proposition féministe? est apparu en premier sur Le blog de Marie-Anne Chabin.
Pagina's







")

































































")

")






























")























")







")
")
")




")
")







]")







")
")



































")






")
")

")

















")








")






")

")






Geheel van gegevens in eenzelfde bestandsformaat.