U bent hier
Rechten
Scraper Internet avec Chromium et puppeteer
A l’heure de l’ouverture des données, du « tout API », il devient facile d’exploiter, transformer, réutiliser les données mises à dispositions. De nouveaux services émergent.
Nombreux sont ceux qui voient dans l’ouverture des données une manière d’être à la base de certaines innovations d’usages, et une manière, plus mercantile, de valoriser leurs données, « ce nouvel or noir ».
Pour d’autres, il est plus difficile de concevoir la mise à disposition de leurs données, soit parce qu’ils n’y voient pas l’intérêt, soit parce qu’ils veulent rendre captifs leurs clients en empêchant leur libération.
Le web scraping est une technique qui rend le pouvoir aux utilisateurs. Son principe consiste à extraire de l’information non structurée d’un site internet afin de la rendre structurée et exploitable par un système informatique.
On développe alors des robots dont l’objectif est d’automatiser la saisie et la collecte de résultats dans des applications (sites internet, applications métier). Dans leur version intelligente, ces robots, couplés à des systèmes de workflow, observent les actions des utilisateurs afin d’apprendre ce qu’il faut faire à un instant donné. C’est le RPA ou Robotic process automation.
Dans cet article, nous nous concentrerons sur la partie scraping. Nous répondrons à la question « Comment extraire automatiquement de l’information d’un site internet qui n’a pas ouvert ses données ? ».
Pour cela, nous allons travailler avec puppeteer et Chromium sur le site http://quotes.toscrape.com/js/
Quelques usages du web scrappingAvant cela, posons-nous et interrogeons-nous sur les usages que nous pouvons faire de cette technique. Ainsi, parmi les usages, on notera :
- L’opendata : il s’agit de rendre disponible auprès de tiers les données collectées pour qu’elles en fasse un usage à définir.
- L’interopérabilité : il s’agit ici d’intégrer le site internet à une étape d’un processus pour qu’il puisse échanger des données avec un autre système sans que les deux ne se connaissent.
- La mobilité : pendant du point précédent, il s’agit de rendre accessible une application web depuis d’autres types de terminaux. Ainsi, il est par exemple possible de faire une application mobile qui discuterait avec un système automatisant les saisies dans une application non prévue pour l’usage mobile.
- L’archivage de sites internet : avec ce type de technique il est possible d’automatiser la navigation et l’enregistrement du site et de ses ressources afin d’en conserver une représentation. Cela peut prendre différentes formes : enregistrement des fichiers reçus lors de la navigation c’est à dire fichiers html, css, js ou prise de copies d’écrans, …
- La surveillance de mises à jour de sites internet : il s’agit de vérifier périodiquement la publication de nouvelles informations et les modifications d’informations existantes comme par exemple les informations sur les prix d’un produit afin d’en mesurer la variation ou les comparer avec d’autres sites internet.
Entrons maintenant dans le vif du sujet. Avant de collecter toute donnée, nous devons observer comment fonctionne le site Internet auquel nous nous attaquons et plus précisément par quels moyens sont publiées les informations qui s’y trouvent. Pour simplifier, je dirais qu’il y a deux manières d’afficher de l’information sur un site internet:
- de manière statique : le site internet publie de l’information dans le contenu de la page affichée.
- de manière dynamique : le site internet publie l’information sur sa page via un script exécuté côté client qui va collecter l’information de manière dynamique (appel API, résultat d’un calcul en fonction d’un comportement de l’utilisateur). La page principale est alors une coquille vide, au moins en partie, et elle est remplie dynamiquement par l’exécution de code.
Pour la partie mise en oeuvre, nous allons extraire les contenus du site de citations. A destination des développeurs, le site propose les deux méthodes sus-citées de génération de son contenu.
Dans mon navigateur, le site ressemble à cela :

Dans sa première version, le contenu est directement généré dans la page html côté serveur. Il est alors très facile d’extraire le contenu avec un simple wget :
wget http://quotes.toscrape.com/Si j’ouvre le fichier téléchargé, j’obtiens le résultat suivant :

Ce n’est pas très joli, mais le résultat est satisfaisant puisque vous pouvez en lire le contenu. Il est inutile donc de charger d’autres ressources, telles que les images, les feuilles de style et le javascript. Il est possible de travailler ensuite sur le contenu pour en extraire les informations souhaitées.
Si l’on prend un contenu généré dynamiquement (via javascript) et qu’on lance la même commande :
wget http://quotes.toscrape.com/js/Nous obtenons ceci :

Zéro contenu !? C’est tout à fait normal, puisque c’est le javascript qui génère le contenu et le place dans la page web. Notre premier outil de web scraping, wget, n’offre pas la possibilité d’exécuter le code javascript. C’est là tout l’intérêt d’une solution qui utiliserait un navigateur complet.
Ainsi, on notera que pour scraper un site internet, il convient de bien choisir ses outils.
Quelques exemples d’outils de web scrapingParmi les outils, Chromium est en train de rebattre les cartes. De nombreux projets majeurs ont annoncé qu’ils arrêtaient de poursuivre leur développement suite à la sortie de la dernière version de Chromium incluant des fonctionnalités d’automatisation.
Chromium est à la base de Chrome, bien connu de tous comme étant un navigateur complet, supportant les fonctionnalités avancées de CSS et de javascript. Il risque de rapidement supplanter toutes les autres librairies qui n’offrent pas ce type de fonctionnalités ou fonctionnant sur des moteurs de navigation plus anciens (phantomjs par exemple).
Il est cependant possible d’utiliser d’autres outils pour scrapper des sites. Les plus basiques, ce sont wget ou curl. Ne vous attendez pas à récupérer autre chose que du html brut comme vu plus haut. Exit donc les résultats de calcul en javascript, la navigation dynamique gérée par un module javascript… Ici, vous récupérez de la donnée brute par un appel direct. Certains sites (via leur CDN) détectent ce type de comportement (via le user agent, ou via la détection de l’activation du javascript) et bloquent ce type d’initiative.
D’autres sont de très bonnes alternatives telles que :
- phantomjs associé à casperjs : phantomjs fonctionne sur une ancienne version de WebKit. Le projet est arrêté suite à la sortie de la dernière version de Chromium.
- Selenium associé à tous les navigateurs : très utilisé dans le domaine des tests unitaires, Selenium permet d’automatiser des tâches dans le navigateur.
- Cheeriojs, Scrapyjs, BS4 pour python : Ces libraires extraient le contenu de la page mais ne chargent pas d’autres ressources comme un navigateur le ferait. Ils sont quoi qu’il en soit très utilisés dans de nombreux projets.
Comme précisé au début de l’article, nous nous efforcerons de répondre à la question « Comment extraire automatiquement de l’information d’un site internet qui n’a pas ouvert ses données ? » par la pratique.
Pour cela, nous allons travailler avec puppeteer et Chromium sur le site http://quotes.toscrape.com/js/.
Installation de nodejsL’installation de node est détaillée à l’adresse suivante : https://nodejs.org/en/download/package-manager/
A noter que node embarque NPM, le gestionnaire de paquets node.
Pour ma part, utilisant une base de debian, j’ai exécuté les commandes suivantes :
curl -sL https://deb.nodesource.com/setup_8.x | sudo -E bash - sudo apt-get install -y nodejs Initialisation du projetL’initialisation du projet se fait en créant un répertoire dédié dans lequel nous allons travailler :
mkdir marionnette cd marionnette npm initEt comme vous êtes poli, vous répondez aux questions (elles n’ont pas d’influence ici mais sont indispensables à la bonne gestion du projet).
Installation de puppeteerPour cet exercice, nous allons utiliser puppeteer. Puppeteer est une bibliothèque node offrant des interfaces pour Chrome et Chromium. Ces interfaces permettent de piloter en javascript le comportement du navigateur.
L’installation de puppeteer embarque une installation de Chromium. C’est parfait car cela nous évitera une configuration avancée inutile.
L’installation de puppeteer se fait via la commande :
npm i puppeteer -saveL’installation est supérieure à 100 Mo incluant Chromium.
Travaillant sur une machine sans écran, il m’a manqué de nombreuses dépendances liées aux librairies graphiques. Le lien ci-après m’a été utile :
et notamment la commande suivante pour savoir ce qu’il me manquait :
ldd chrome | grep not Notre Hello WorldLa première étape est de vérifier que tout fonctionne. Pour cela nous allons faire une copie d’écran du site toscrape.com.
Nous créons un répertoire screenshots dans le lequel se trouvera notre copie d’écran :
mkdir screenshotsPuis nous créons un fichier que l’on nommera scrape.js qui contiendra les instructions suivantes :
const puppeteer = require('puppeteer'); async function scrape() { const browser = await puppeteer.launch({headless: true}); const page = await browser.newPage(); await page.setViewport({width:1920, height:2160}); await page.goto("http://toscrape.com", {waitUntil: 'networkidle2'}); await page.screenshot({ path: 'screenshots/toscrape.png' }); browser.close(); } scrape();Voici ce que fait le code:
- Importation et initialisation de puppeteer;
- Déclaration d’une fonction asynchrone scrape;
- Lancement d’une instance du navigateur sans qu’il ne s’affiche headless = true;
- Ouverture d’une nouvelle page du navigateur;
- Initialisation de la vue de la page, ici 1920 sur 2160 (écran en mode portrait);
- Navigation vers la page du site http://toscrape.com et attente que tout soit bien chargé;
- Prise d’une copie d’écran et sauvegarde vers le chemin screenshots/toscrape.png;
- Fermeture de l’instance du navigateur;
- Enfin, appel de la fonction scrape().
Lançons le script de la manière suivante :
node scrape.jsNous obtenons ce résultat :
TADAAA ! Nous venons de scraper notre premier site web.
Scraping du site internet de citationsDans cette seconde partie, nous allons extraire le contenu du site de citations sous forme de données. Le site propose différentes méthodes de génération de contenu pour exercer son automate. Comme expliqué en introduction, nous allons utiliser la version dont le contenu est généré par du javascript.
Pour commencer, nous allons observer le site en question. Il s’agit d’une page contenant les citations. Chaque citation est composée d’un texte, d’un auteur et d’une série de mot-clés. Le site est paginé. On accède à la page suivante en cliquant sur le bouton « Next » et ainsi de suite.
Dans cet article, je vais laisser de côté la pagination pour me concentrer sur l’extraction de contenu.
Pour commencer, et par praticité , nous allons définir une citation comme ceci :
function Quote(text, author, tags) { this.text = text; this.author = author; this.tags = tags; }Nous allons ensuite créer une boucle sur chaque citation affichée sur la page.
Avant de nous lancer dans l’écriture du code, nous allons inspecter la source de la page afin de déterminer comment sont structurées les citations dans le contenu de la page (clique droit sur un élément > Inspecter).

Ici, on remarque que chaque citation est contenue dans une div qui porte la classe quote. Nous allons donc lancer une requête dans le contenu de la page pour obtenir toutes les div.quote de notre document et enregistrer cela dans un tableau.
Un petit tour dans la documentation de puppeteer nous permet d’écrire :
const elements = await page.$$("div.quote"); // returns [] if nothingNous avons donc dans elements des ElementHandle de chacune des citations de la page.
Dans la suite, nous allons itérer sur ces élements afin d’en extraire ce qui nous interesse. Pour cela, retournons faire un tour dans la source de la page.

On remarque que le texte des citations se trouve à l’intérieur d’une balise qui porte la classe text, le nom de l’auteur à l’intérieur d’une balise portant la classe author, et les tags tags. Et c’est comme cela pour chacune des citations. Nous écrivons donc :
for (var element of elements){ // Loop through each element let text = await element.$eval('.text', s => s.textContent.trim()); let author = await element.$eval('.author', s => s.textContent.trim()); let tags = await element.$eval('.tags', ar => ar); console.log(text +" - "+author); }- On boucle pour chaque element de elements;
- Dans cet élément, on sélectionne l’élément qui a la classe text. On en extrait le contenu que l’on débarrasse des éventuels espaces en trop;
- Dans cet élément, on sélectionne l’élément qui a la classe author. On en extrait le contenu que l’on débarrasse des éventuels espaces en trop;
- Dans cet élément, on sélectionne l’élément qui a la classe tags. Ici on ne fait rien. Il contient un ensemble d’éléments de classe tag. Nous allons d’ailleurs modifier cette ligne juste après;
- Enfin, nous loguons dans la console le texte et l’auteur de la citation.
Comme précisé précédemment, intéressons-nous aux tags. La source de la page nous indique que pour chaque citation, les tags sont dans des balises a qui portent chacune la classe tag. Une manière de faire serait de refaire une boucle sur chaque élément de la variable tags récupérée précédemment et de renseigner une tableau. Il se trouve que puppeteer propose la fonction pour le faire. Notre code devient:
let tags = await element.$$eval('.tag', ar => ar.map(a => a.text) );Ce code sélectionne tous les élements de classe tag et les met dans un tableau. Nous avons un talbeau d’ElementHandle de type a. La partie ar => ar.map(a => a.text) extrait pour chaque élément du tableau le texte contenu dans la balise a.
Une fois ceci fait, il ne nous reste plus qu’à stocker le contenu dans un tableau. Le code complet devient :
const puppeteer = require('puppeteer'); function Quote(text, author, tags) { this.text = text; this.author = author; this.tags = tags; } async function scrape() { const browser = await puppeteer.launch({headless: true}); const page = await browser.newPage(); await page.setViewport({width:1920, height:2160}); await page.goto("http://quotes.toscrape.com/js/", {waitUntil: 'networkidle2'}); const elements = await page.$$("div.quote"); // [] if nothing var mydata = new Array(); // Create an empty array for (var element of elements){ // Loop through each element let text = await element.$eval('.text', s => s.textContent.trim()); let author = await element.$eval('.author', s => s.textContent.trim()); let tags = await element.$$eval('.tag', ar => ar.map(a => a.text) ); let item = new Quote(text, author, tags); mydata.push(item); // Push the data to our array } console.log(mydata); browser.close(); } scrape();Vous pouvez tester le résultat avec la commande suivante :
node scrape.jsCela donne le résultat suivant :
[ Quote { text: '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”', author: 'Albert Einstein', tags: [ 'change', 'deep-thoughts', 'thinking', 'world' ] }, Quote { text: '“It is our choices, Harry, that show what we truly are, far more than our abilities.”', author: 'J.K. Rowling', tags: [ 'abilities', 'choices' ] }, Quote { text: '“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”', author: 'Albert Einstein', tags: [ 'inspirational', 'life', 'live', 'miracle', 'miracles' ] }, Quote { text: '“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”', author: 'Jane Austen', tags: [ 'aliteracy', 'books', 'classic', 'humor' ] }, Quote { text: '“Imperfection is beauty, madness is genius and it\'s better to be absolutely ridiculous than absolutely boring.”', author: 'Marilyn Monroe', tags: [ 'be-yourself', 'inspirational' ] }, Quote { text: '“Try not to become a man of success. Rather become a man of value.”', author: 'Albert Einstein', tags: [ 'adulthood', 'success', 'value' ] }, Quote { text: '“It is better to be hated for what you are than to be loved for what you are not.”', author: 'André Gide', tags: [ 'life', 'love' ] }, Quote { text: '“I have not failed. I\'ve just found 10,000 ways that won\'t work.”', author: 'Thomas A. Edison', tags: [ 'edison', 'failure', 'inspirational', 'paraphrased' ] }, Quote { text: '“A woman is like a tea bag; you never know how strong it is until it\'s in hot water.”', author: 'Eleanor Roosevelt', tags: [ 'misattributed-eleanor-roosevelt' ] }, Quote { text: '“A day without sunshine is like, you know, night.”', author: 'Steve Martin', tags: [ 'humor', 'obvious', 'simile' ] } ]Nous disposons donc des citations sous une forme structurée et pouvons les utiliser dans notre projet suivant.
Bonus Track : Mettre à disposition les données via une API RestVous êtes arrivé jusqu’ici. Bravo !
Pour la suite, nous allons publier sous une forme structurée les données fraîchement collectées.
Pour cela, nous allons utiliser express. Express est un module Nodejs. Il fournit un ensemble de fonctionnalités pour les applications Web et mobiles.
Il dispose notamment d’outils pour HTTP permettant d’accélérer la création d’API.
Depuis le terminal, installons express :
npm i express -saveNous allons créer une série de répertoires :
mkdir routes mkdir controlers mkdir models- routes : Ce répertoire contiendra tous les fichiers permettant de gérer les points d’entrée de notre application. Les routes redirigeront le traitement vers le bon contrôleur.
- controlers : Ce répertoire contiendra tous les fichiers permettant de gérer les traitements de notre application. Le contrôleur réalise le traitement en lisant ou écrivant les données depuis un ou plusieurs modèles.
- models : Ce répertoire contiendra tous les fichiers permettant de gérer les données de notre application.
Nous allons ensuite déplacer le fichier scrape.js dans le répertoire contenant les modèles :
mv scrape.js modelsNous allons modifier le fichier scrape.js et faire en sorte que la fonction scrape() retourne le tableau des résultats en ajoutant return mydata; à la fin de la fonction. Ensuite nous allons modifier la dernière ligne. Au lieu d’appeler scrape(); nous allons exporter la fonction pour qu’elle puisse être utilisée dans un autre module :
module.exports = scrape ;
Dans le répertoire controlers, nous créons un fichier quoteControler.js qui contiendra :
'use strict'; var scrape = require('../models/scrape'); exports.list_all_quotes= async function(req, res) { let response = await scrape(); res.status(200).json({ results: response }); };Nous créons ensuite un fichier quoteRoute.js dans le répertoire routes qui contiendra le code suivant :
'use strict'; module.exports = function(router) { var quoteCtl = require('../controlers/quoteControler.js'); // Routes router.route('/quotes') .get(quoteCtl.list_all_quotes); };Le code des fichiers précédents permet de faire en sorte que quand le point d’entrée /quotes de notre API est appelé avec la méthode GET, l’application appelle la méthode list_all_quotes qui déclenche le scraping du site et retourne les résultats sous forme d’une réponse formatée json.
Enfin, pour que tout cela fonctionne, il nous faut un moyen de démarrer l’application pour qu’elle écoute les requêtes entrantes.
Nous créons donc un fichier server.js à la racine de notre projet avec le code suivant :
var express = require('express'); var app = express(); var router = express.Router(); var port = process.env.PORT || 8080; var bodyParser = require('body-parser'); app.use(bodyParser.urlencoded({ extended: true })); app.use(bodyParser.json()); var routes = require('./routes/quoteRoute'); //importing route routes(router); //register the route router.use(function(req, res) { res.status(404).send({url: req.originalUrl + ' not found'}) }); app.use('/', router); app.listen(port); console.log('Quotes RESTful API server started on: ' + port);Il n’y a plus qu’à tester.
Pour cela, nous lançons notre application de la manière suivante :
node server.jsLe serveur est démarré si ceci apparaît :
Quotes RESTful API server started on: 8080Avec notre navigateur, rendons-nous à l’adresse de notre serveur, ici en l’occurrence http://localhost:8080/quotes. Le résultat est stupéfiant :

Vous venez d’extraire automatiquement vos premières données structurées à partir d’informations non structurées publiées sur Internet. Maintenant que vous avez ces données, vous pouvez les retravailler et les réutiliser dans vos programmes. Vous avez aussi pu créer une API pour mettre à disposition des données qui n’étaient initialement pas structurées.
Evidemment, vous remarquerez de nombreuses pistes d’optimisation. Parmi celles-ci :
- La mise en cache des données : En fonction de la fréquence de collecte des données, il devient vite indispensable de mettre en place un mécanisme de cache. Cela permet de ne collecter que les nouvelles données ou de ne les rafraîchir que sous certaines conditions;
- La prise en compte du temps de traitement : le web scraping imite l’utilisateur qui navigue sur un site internet. Un scénario de navigation élaboré pourra nécessité du temps. Il conviendra donc de rendre asynchrone le traitement de la demande;
- La validation des données : les données des applications qui sollicitent l’API tout comme les données collectées des sites internet doivent être validées afin de s’assurer que les données saisies ou reçues correspondent bien aux types attendus;
- La gestion des erreurs : le scrapping dépend de nombreuses variables en cela qu’il s’agit de travailler avec un site dont on ne maîtrise pas grand chose. Ainsi il est indispensable de prévoir tous les types d’erreur auquel nous pouvons être confrontés (coupure réseau, instabilité de Chromium, modification de la structure du site internet distant, changement des types des données …);
- et bien d’autres encore…
Avant de nous quitter, sachez que si vous cherchez à automatiser le téléchargement de fichier, il y a actuellement une limitation qui n’est pas des moindres : il est impossible de télécharger un fichier avec Chromium et puppeteer pour l’instant. Certains ont trouvé des solutions de contournement qui ne fonctionnent que dans des cas très spécifiques. La fonctionnalité est heureusement prévue. Elle est en priorité 1 et devrait arriver prochainement.
Image d’entête : EL DUDUSS DE PAPEL, Toctoc (Instagram : @bytoctoc) | photographie : Kevin Lagaisse | CC BY-NC-ND 3.0
Cet article Scraper Internet avec Chromium et puppeteer est apparu en premier sur Kevin Lagaisse.
Adoptez le CMMN, la notation du Case Management
Tenter de modéliser une activité et se rendre compte qu’il est difficile de se la représenter avec les outils classiques, c’est une chose qui a dû tous nous arriver au moins une fois.
Quand je parle d’outils classiques, je pense au BPMN (Business Process Management Notation) qui permet de modéliser les processus.
Sauf qu’aujourd’hui les activités ne sont plus si procédurées. Dans une organisation où il est demandé à tous de s’adapter, de revenir sur des choses déjà traitées, de gérer l’inattendu ou de réaliser des tâches difficilement prévisibles, il devient indispensable de disposer des bons outils pour les modéliser.
C’est là qu’intervient le Case Management, ou Gestion de Dossier. BP Trends definit le Case Management :
Le Case Management consiste en la gestion de processus collaboratifs dont la durée de vie peut être longue, qui coordonnent de la connaissance, des contenus et des ressources pour faire avancer un dossier dans un contexte métier particulier ; avec un déroulement qui peut ne pas être connu à l’avance (non prédictif) ; dans lequel une appréciation humaine est nécessaire pour déterminer dans quelle mesure le but à atteindre peut être atteint réellement ; et où l’état du dossier peut être altéré par des événements externes à l’organisation.
La Notation du Case Management ou CMMN (Case Management Modeling Notation) permet de prendre en compte cette évolution. Le sujet n’est pas nouveau et commence à être déjà très mature. Il est d’ailleurs facilement possible de trouver des logiciels de case management auprès d’éditeurs.
Chacun y va de sa vision qui correspond à sa spécialité :
- orientée processus,
- orientée document,
- orientée dossier à traiter (les puristes)
Le support que je vous propose vous apprendra à débuter avec la notation du Case Management.
J’espère qu’il vous aidera à mieux appréhender les concepts du Case Management et pourquoi pas à utiliser la notation dans vos futurs dossiers.
Télechargez le support Case management Modeling notation
Et si vous voulez vous exercer à la modelisation sans dépenser un euro, visitez https://demo.bpmn.io/cmmn et commencez à modéliser votre premier dossier.
Image d’entête : Filing System | David Goehring | CC BY 2.0
Cet article Adoptez le CMMN, la notation du Case Management est apparu en premier sur Kevin Lagaisse.
Introduction à la blockchain des archivistes
Le 28 septembre 2017, j’étais invité par eFutura pour introduire une table ronde concernant la blockchain des archivistes. Exercice inédit pour moi qui avais pour objectif d’introduire un maximum de concepts en seulement 10 minutes. Autant dire que c’était très chaud.Je vous livre ici le support légèrement modifié ainsi qu’un résumé de la présentation.Si au premier abord, vous pouvez vous demander si on peut trouver un rapport entre blockchain et archiviste. Quand on parle de blockchain, on pense automatiquement à bitcoin et là il y a tout un imaginaire qui s’offre à nous :

Imaginaire de la blockchain
Les archivistes vont-ils s’échanger une monnaie appelée archivecoin ? Et se lancer dans le trafic de « trésors nationaux »? Pourquoi pas. Nous connaissons tous leur goût pour les endroits sombres (mais surtout pas trop humides).Il existe cependant aussi d’autres outils quotidiens de l’archiviste qui se rapprochent de la blockchain et qui méritent que nous les observions de plus près.
La journalisation NF Z42-013Le rapport entre blockchain et archiviste se trouve dans la norme NF Z42-013:2009 dans sa partie journalisation.Quand elle parle de l’attestation, la norme indique les choses suivantes :
L’attestation doit contenir au minimum l’empreinte des documents déposés.
Afin d’empêcher la modification d’un enregistrement effectué dans le journal de cycle de vie des archives, il est obligatoire d’horodater celui-ci au minimum une fois par jour y compris en cas d’absence d’activité.
La continuité de la journalisation doit être assurée.
Dans les clauses de sécurité pour les tiers-archiveurs électroniques (TAE), le norme indique que ce dernier doit garantir la sécurité et l’intégrité du journal du cycle de vie des archives et du journal des événements.Dans un système d’archivage électronique, il y a différentes manières de procéder afin de produire les journaux. Toutes ces manières respectent les trois principes précédemment cités:
- Empreinte
- Horodatage
- Continuité des journaux
Prenons l’exemple d’un versement d’archives. Quand les archives sont versées, le système va prendre une empreinte de chaque document. Les systèmes peuvent pousser jusqu’à prendre non seulement l’empreinte d’un document versé mais aussi de toute la trace, c’est à dire : la date et l’heure précise de l’événement, l’action réalisée et l’empreinte du document. Il est aussi possible de le sceller pour assurer son intégrité.Cette trace est ensuite ajoutée au journal.En fin de journée, le journal est clôturé. Le journal du jour suivant est alors ouvert avec le versement du journal tout juste clôturé. Nous avons alors notre premier chaînage.

Principe de la journalisation NF Z 42-013
Une blockchain, c’est exactement la même chose. Enfin presque…Si nous faisons le parallèle : une blockchain, c’est un grand registre (ensemble de journaux pour la NF Z42-013) sur lequel on inscrirait tout type d’informations (des événements sur un système ou des archives pour le NF Z42-013).Ce registre est dupliqué chez chaque participant. C’est la différence avec la NF Z42-013 où il n’y pas de notion de participant et donc personne chez qui dupliquer notre registre. Chaque participant dispose du registre au complet.Des nœuds sont chargés de tenir à jour le registre et de vérifier les inscriptions qui y sont faites. Ces inscriptions sont faites par les participants en transmettant leur transaction aux noeuds du réseau.Ainsi, si vous avez compris la « logchain », vous avez compris la blockchain. Le reste n’est que mécanismes cryptographiques et consensus algorithmique.
Les types de blockchainJe catégorise les blockchains en trois types:

Types de blockchain
- Publique : tout le monde y a accès pour y faire « ce qui est prévu d’y faire ». Généralement c’est de l’échange de cryptomonnaie ou de bonds.
- De consortium : des gens très sérieux décident de partager de l’information ou des preuves d’existence et de consistance d’information. Par exemple les compagnies aériennes pourraient s’échanger des moyens de vérifier des informations sur les passagers. Une compagnie pourrait échanger ce type d’information avec des hôteliers ou des loueurs de véhicules.
- Privée : Celle qui ne sert à rien. Vous êtes tout seul et vous l’utilisez pour stocker de l’information. Autant faire une base de données. Sauf si vous avez l’idée à terme de partager la blockchain.
Parmi les technologies, on retrouve des plateformes assez différentes :

Exemples de technologies de blockchain
Dans ce domaine, les alliances se forment. IBM mise sur Hyperledger et s’assure une diffusion large (et une sorte de blanc seing) grâce à la Linux Foundation.En réponse, Microsoft, Intel, Accenture et des banques s’associent pour adapter Ethereum aux pratiques de la banque. Réponse du berger à la bergère.Les technologies ne sont pas figées: ainsi Microsoft adapte Ethereum au lieu de la reprendre telle quelle.De plus, cela bouge aussi du côté de Ethereum. Les développeurs ont décidé de changer de type de consensus en 2018.
Anatomie de la blockchainUne blockchain, c’est donc trois éléments importants:
- Un bloc
- Des transactions dans les blocs
- Le chaînage entre les blocs

Anatomie d’une blockchain
La transactionUne transaction, c’est une ligne inscrite dans le registre de compte.Construisons notre propre transaction:

La transaction
“Bob donne à Alice une montre à gousset le 1er Mars”. C’est notre transaction. Bob signe cette transaction (en la chiffrant avec sa clé privée) afin de résoudre quelques problèmes « mineurs » :
Bob signe cette transaction (en la chiffrant avec sa clé privée) afin de résoudre quelques problèmes « mineurs » :
- l’authentification
- la non-répudiation
- L’intégrité de la transaction
Vu que la transaction est chiffrée, nous indiquons que c’est bien Bob qui l’a signée. Cela permet de savoir que c’est sa clé publique qu’il faut utiliser #astuceDeGrandMère.Nous pouvons faire évoluer notre transaction en lui ajoutant une valeur (pratique si l’on envisage de créer une monnaie), une date (on reviendra sur la notion d’horodatage plus loin) ou des frais si notre blockchain rémunère ceux qui vont s’accorder sur la validité de nos transactions.Le bitcoin, quant à lui, ne conservera que la valeur, les frais étant fixés par le système.Une fois que notre transaction est bien formée, elle est diffusée dans le réseau puis est raccrochée à un bloc.
Le blocLe bloc, c’est une enveloppe. C’est l’équivalent de notre page du registre sur laquelle sont inscrites des transactions. Nous allons y retrouver l’ensemble des transactions mais pas uniquement cela. Le noeud qui va tenter de faire accepter le bloc doit d’abord le finaliser. Nous y ajoutons donc :
- l’empreinte du bloc auquel on veut le raccrocher
- une date (on va y venir concernant l’horodatage, promis)
- L’arbre de Merkle

L’arbre de Merkle permet de réaliser un chaînage des transactions entre elles. Il s’agit d’un arbre dont chaque niveau est l’empreinte des niveaux inférieurs. Alors que les transactions n’ont rien à voir entre elles, l’arbre de Merkle matérialise une interdépendance.

Construction de l’arbre de Merkle
La racine de l’arbre de Merkle se retrouve dans l’entête du bloc. Avec cet arbre, nous pouvons faire de nombreuses vérifications.Pour les acteurs d’une blockchain qui disposent d’une copie chez eux, il leur est possible de vérifier que la racine de l’arbre d’un bloc qu’ils ont en leur possession correspond bien à celle des autres participants, ainsi qu’à toutes les transactions qu’ils stockent. Cela rend toute altération du bloc impossible.Celui qui ne dispose que d’une transaction peut assez rapidement vérifier que celle-ci a eu lieu. Il suffira alors de ne télécharger auprès d’une première source que l’entête du bloc qui contient la transaction. Il pourra y retrouver la racine de l’arbre de Merkle.Ensuite, le client récupère, auprès d’autres sources, les éléments manquants afin de réaliser la vérification de l’empreinte de la racine de l’arbre de Merkle.Cette vérification ne nécessite pas de télécharger tout l’arbre de Merkle, seules certaines parties suffisent :

Vérification d’une transaction
A terme, quand la blockchain sera trop grosse pour être stockée par tous, il sera possible de ne conserver que des versions allégées des anciens blocs. Ainsi, en interrogeant d’autres sources, il sera possible de télécharger et vérifier les éléments manquants tout en s’assurant que tout le monde parle bien du même bloc.
Le nonce ou comment faire accepter un bloc au réseauA ce stade, tout est prêt pour transmettre le bloc aux autres participants. Cependant qu’est-ce qui me prouve que je peux vous faire confiance et que vous n’êtes pas en train de tenter de réaliser des transactions malhonnêtes ?Pour cela, un concept génial on été inventé : le consensus. Des gens se mettent autour d’une table et se débrouillent pour se mettre d’accord selon des règles préétablies au départ. Un peu comme des chefs d’Etat qui tenteraient de trouver un accord sur le nucléaire Nord Coréen.Il y a différents types de moyens de se mettre d’accord selon les cas :
- Le proof of work : C’est la méthode « bitcoin ». Il consiste à produire un bloc ayant la plus petite empreinte possible.
- Le proof of stake : Celui qui a le plus d’enjeux dans la blockchain décide. Pour de la monnaie, il doit posséder une certaine quantité de celle-ci. Il devient un « validateur ». –Peercoin, Ethereum en 2018
- Le proof of activity : il s’agit d’un mélange de proof of work et de proof of stake. le calcul s’arrêtera quand un certain nombre de signatures de nœuds aura été apposé sur le bloc candidat.
- Proof of burn : il s’agit de dépenser de l’argent vers une adresse qui n’existe pas afin d’être sélectionné par le réseau pour miner le bloc.
Et beaucoup d’autres :
- Proof of capacity
- Proof of elapsed time
- Byzantine fault tolerance
Pour bitcoin, le proof of work est utilisé. Le minage consiste à atteindre la plus petite empreinte possible. Cela se fait en introduisant une variable (un nonce) qui va faire varier l’empreinte du bloc.Avec ces algorithmes, il est impossible de prévoir à l’avance à partir d’une empreinte, à quel fichier cela correspond. Ainsi il est nécessaire réaliser des tentatives de calcul d’empreinte en faisant varier une variable (le nonce) jusqu’à l’atteinte d’une empreinte satisfaisant aux règles du consensus.

Consensus Proof of Work
Une fois que le bloc est bien formé et qu’il fera consensus, il peut être distribué.
La notion de « date certaine » avec la blockchainPetit aparté sur l’horodatage: Sujet ô complexe (en fait pas du tout).À la notion de date certaine, la blockchain répond par le principe du consensus.Dans notre blockchain, nous avons choisi de dater les transactions. Il peut s’agir de la date de réalisation de la transaction ou dans le cas de bitcoin de la date de réception de la transaction par le noeud. A peu de choses près, cela s’est passé au même moment et n’est pas très important.Ce qui va être important, c’est le scellement du bloc. Dans notre blockchain, nous pouvons décider que la date du bloc valide doit dater de moins de deux heures pour être accepté par tous les autres noeuds. C’est d’ailleurs le principe adopté par bitcoin.Ainsi, on repose encore une fois sur une règle de consensus écrite à l’avance pour déterminer la “date certaine” du bloc. Tout ce travail pour faire consensus n’aura donc pas été vain.
En conclusion : blockchain ou base de données ?
Vous pouvez récupérer la présentation ici Principes de la blockchain
Image d’entête : Fingerprint, Sculpture outside Wagner Park, Manhattan | Charles Dyer | CC BY 2.0
Cet article Introduction à la blockchain des archivistes est apparu en premier sur Kevin Lagaisse.
Le SHA1 est mort, vive le SHA1
Cela fait plus de 10 ans que l’on nous dit d’arrêter d’utiliser SHA1 comme algorithme cryptographique dans le cadre des relations de confiance. Google vient de nous annoncer qu’il est vraiment temps de passer à autre chose, en théorie.
Suite à la publication des travaux de Google et du CWI Institute d’Amsterdam, il est possible de générer sans aucun coût des fichiers différents ayant la même empreinte sha1.
This is how the SHA1 collision PDF format trick works (it's really an embedded JPEG format trick) pic.twitter.com/ogPuPegKL6
— Hector Martin (@marcan42) February 24, 2017
Si certains systèmes risquent de planter car ils se basent sur sha1 pour se repérer (systèmes de dédoublonnage notamment), dans la pratique il y a peu de cas où cela risque de se produire en dehors de la malveillance.
Cependant, quand cela se produit, les conséquences peuvent être importantes que cela soit en matière de perte de confiance ou de perte d’information dans le cadre d’un acte de malveillance.
Le risque de perte de confiancePour illustrer le risque que pose cette découverte en matière de confiance, prenons un exemple :
Kevin doit 10€ à David. En bon amis et vue la somme importante en jeu, Kevin prépare une reconnaissance de dettes.
En bon filou, Kevin réalise deux documents:
- Dans le premier, il inscrit qu’il doit 10€ à David
- Dans le second, il inscrit que c’est David qui lui doit 10€
Les deux documents ont la même empreinte sha1 :
C87BC2A068B741FF2F3CD0AFE8D10EE324717C27Ensuite, Kevin et David signent le premier document avec leurs clés privées respectives, toutes deux basées sur sha1 (ce qui devrait être très peu probable en 2017).
View FullscreenKevin, de son côté, archive le second document et la signature du premier document dans son système d’archivage légal.
View FullscreenDavid fait de même avec le premier document.
Comme les deux documents ont la même empreinte, il n’est pas possible de dire sur quoi porte exactement la signature, et donc de prouver qui est redevable à qui. Imaginez la tête du juge qui doit trancher entre Kevin et David.
Les conséquences d’un acte de malveillancePour cela prenons un exemple très concret :
David est administrateur d’une plateforme d’archivage conforme NF Z 42-013. Le système choisi par son entreprise réalise une empreinte sha1 de tout document versé, signe cette empreinte et inscrit l’action de versement dans les journaux.
David, en conflit avec son employeur, décide de se connecter aux baies de stockage SAN avec son compte admin. Il y remplace tous les contrats concernant le patrimoine de son entreprise par des fichiers contenant la littérature anglo-saxonne.
Le système d’archivage continue d’indiquer que les documents sont intègres mais l’entreprise de David a perdu tous les documents relevant de son patrimoine.
ConclusionA ce stade, la meilleure solution reste à vérifier que l’analyse des risques couvre bien ces cas. Il se peut même que des actions mises en place pour d’autres événements redoutés couvrent les cas de malveillance liés à l’obsolescence du sha1.
Au final, il n’est pas nécessaire de se lancer dans une migration des empreintes déjà réalisées. Au mieux, il est possible de patcher les systèmes en place pour détecter les fichiers qui exploitent cette vulnérabilité.
Pour les nouveaux systèmes, il est préférable de passer à du sha256, sha512 ou encore mieux Blake2.
Le site : https://shattered.io/
La publication : https://shattered.io/static/shattered.pdf
Le schéma explicatif (png) : PDF format collision
Le collisionneur de PDF : https://alf.nu/SHA1
Image d’entête : Kryptos sculpture, Smithsonian | wanderingYew2 | CC BY 2.0
Cet article Le SHA1 est mort, vive le SHA1 est apparu en premier sur Kevin Lagaisse.

Une blockchain pour l’archivage à valeur probatoire
Pour faire de l’archivage électronique à valeur probatoire, les organisations doivent faire l’acquisition de produits coûteux offrant des mécanismes de traçabilité sécurisés. Ces mécanismes ont pour objectif d’assurer l’intégrité des archives et l’imputabilité des actions qui sont réalisées. C’est ce qu’on appelle de l’archivage électronique à valeur probatoire. Nous allons voir que l’on peut se reposer sur la technologie Blockchain pour assurer ce caractère tout au long de la conservation des archives.
Il faut savoir que le caractère probatoire d’un document ou d’une archive ne s’acquière pas. On peut faire un peu le rapprochement entre l’inné ou l’acquis. La valeur probatoire du document est une valeur en soi du document. Ce n’est pas parce que vous archivez un document dans un système dit “à valeur probatoire”, qu’il a valeur de preuve. Cependant si vous avez un document (un contrat par exemple) qui fait foi face une partie, vous devez vous assurer de son intégrité au risque qu’il perde son caractère de preuve. Dans ce cas, il n’est plus possible de prouver que le contrat est fidèle à ce qui a été signé.
Le régime juridique de la preuve
Code civil des Français (Paris: De l’Impr. de la République, 1804) | Yale Law Library, CC BY 2.0
Il existe actuellement deux régimes de preuve :
- La preuve libre : Elle permet d’utiliser tous les moyens pour démontrer les faits juridiques, transactions civiles (<1500€ actuellement) ou transactions entre commerçants. Elle est aussi la règle en droit pénal et administratif. En cas de contestation d’une preuve, c’est l’appréciation du juge qui permettra de trancher.
- La preuve légale : elle est utilisée dans tous les cas où la loi impose formellement un moyen de preuve déterminé. Le régime juridique de la preuve légale relève des articles 1341 et 1316 à 1316-4 du code civil, et à partir d’octobre 2016, des articles 1375 et 1363 à 1368 du code civil (et peut-être d’autres).
Ainsi, l’article 1316-1 du code civil nous indique que : « L’écrit sous forme électronique est admis en preuve au même titre que l’écrit sur support papier, sous réserve que puisse être dûment identifiée la personne dont il émane et qu’il soit établi et conservé dans des conditions de nature à en garantir l’intégrité. »
A partir d’octobre 2016, il est remplacé par l’article 1366 du code civil qui nous indique que : « L’écrit électronique a la même force probante que l’écrit sur support papier, sous réserve que puisse être dûment identifiée la personne dont il émane et qu’il soit établi et conservé dans des conditions de nature à en garantir l’intégrité. »
On retrouve bien là deux notions importantes que sont l’imputabilité et l’intégrité. Mais la preuve relève d’un régime juridique qui distingue les notions d’original électronique et de copie électronique :
- L’original électronique : « l’exigence d’une pluralité d’originaux est réputée satisfaite pour les contrats sous forme électronique lorsque l’acte est établi et conservé conformément aux articles 1316-1 et 1316-4 et que le procédé permet à chaque partie de disposer d’un exemplaire ou d’y avoir accès. » (Article 1325 du code civil)
- La copie: « Toute reproduction littérale d’un original qui, n’étant pas revêtue des signatures qui en feraient un second original ne fait foi que lorsque l’original ne subsiste plus et sous les distinctions établies par l’article 1335 du code civil, mais dont la valeur est reconnue à des fins spécifiées (notamment pour les notifications), sous les conditions de la loi (copies établies par des officiers publics compétents…) » selon l’ouvrage de G.CORNU « Vocabulaire juridique » PUF 2001
A partir d’octobre 2016, ces éléments sont remplacés par :
- L’original électronique : « L’exigence d’une pluralité d’originaux est réputée satisfaite pour les contrats sous forme électronique lorsque l’acte est établi et conservé conformément aux articles 1366 et 1367, et que le procédé permet à chaque partie de disposer d’un exemplaire sur support durable ou d’y avoir accès. » (Article 1375 du code civil)
- La copie : « La copie fiable a la même force probante que l’original. La fiabilité est laissée à l’appréciation du juge. Néanmoins est réputée fiable la copie exécutoire ou authentique d’un écrit authentique. Est présumée fiable jusqu’à preuve du contraire toute copie résultant d’une reproduction à l’identique de la forme et du contenu de l’acte, et dont l’intégrité est garantie dans le temps par un procédé conforme à des conditions fixées par décret en Conseil d’État. Si l’original subsiste, sa présentation peut toujours être exigée » (Article 1379 du code civil)
Ainsi le document qui doit tenir lieu de preuve, s’il est conservé dans des conditions assurant son imputabilité et son intégrité, est recevable s’il est un original électronique. Exit donc les copies numériques sauf si la copie est fidèle à l’orignal et intègre ET que l’original ne subsiste plus. Cependant le caractère fidèle s’apprécie par rapport à l’original, ce qui est un autre débat.
L’archivage à valeur probatoire
Archives | Marino González, CC BY-NC-ND 2.0
En résumé, la conservation du caractère probatoire d’un document doit impliquer les assurances suivantes :
- Imputabilité : on doit pouvoir identifier la personne (physique ou morale) dont émane le document
- Intelligibilité : le document doit conserver son caractère lisible
- Intégrité : le document doit être protégé contre la destruction, l’altération, la modification, qu’elle soit intentionnelle ou accidentelle
- Traçabilité : Tous les accès et modifications de documents doivent être tracés
Ces assurances doivent être garanties dans le temps. C’est la notion de Pérennité.
Le caractère probant reste toujours à l’appréciation du juge. Il reste donc recommandé de conserver l’original et donc de ne pas considérer un archivage électronique des copies électroniques (on en reparle dans 6 mois, la réglementation européenne évoluant rapidement).
A noter que la conservation doit être durable et concerner toutes les pièces accompagnant le document (Recommandé avec Accusé de Réception par exemple).
Pour respecter ces principes, un certain nombre des normes ont été produites. La plus connue en France est la norme NF-Z 42-013, normalisée au niveau international sous le nom ISO 14641-1. Cette norme peut donner lieu à une « certification » du système d’archivage et de l’organisation qui le supporte. Il s’agit de la marque NF-461.
La norme NF-Z 42-013 se lit en complément de la norme ISO 14721 (OAIS). Elle est adaptée aux archives quand la norme ISO 15489 (Records Management) est adaptée aux documents.
La norme NF-Z 42-013 “fournit un ensemble de spécifications techniques et de mesures organisationnelles à mettre en oeuvre pour l’enregistrement, l’archivage et la communication de documents numériques afin d’assurer la lisibilité, l’intégrité et la traçabilité de ces documents pendant la durée de leur conservation et de leur utilisation.”
L’imputabilité est gérée en amont via la traçabilité qui peut mettre en jeu des mécanismes de signature électronique avancée.
La pérennité doit être vue comme un processus à mettre en oeuvre au cours de la vie des archives afin d’en assurer la lisibilité dans le temps. Nous ne traiterons pas ce sujet ici même si la norme le traite sur tous ses aspects (formats, supports, matériels, signatures, …).
Les principes de la norme NF-Z 42-013
Constitution in the National Archives | Mr.TinDC, CC BY-ND 2.0
La norme pose certains principes. Elle décrit notamment les modes de captures des archives, les modes de stockage des archives et des métadonnées, l’autorisation de la compression, le cycle de vie des archives, ainsi que le recours au tiers archivage.
Mais elle décrit aussi les principes de journalisation. La norme impose deux types de journaux:
- Le journal des événements : Il contient tous les événements liés à l’application d’archivage, à la sécurité, et au système. Il contient pèle-mêle toutes les actions réalisées dans le système, à savoir les accès, l’identification des documents, la création de copies de sécurité, les mouvements des supports, les conversions de format pour n’en citer que quelques exemples.
- Le journal du cycle de vie des archives: il contient l’ensemble des attestations relatives aux archives (cf. http://www.archivesdefrance.culture.gouv.fr/static/7645) , à savoir :
-
- Validation du dépôt
-
- Migration de format
-
- Modification des métadonnées
-
- Restitution d’une archive
-
- Restauration d’une archive (en cas de problème d’intégrité)
-
- Destruction d’une archive
Chaque journal est considéré comme une archive et doit être conservé de la même manière. Les attestations d’opérations contenues dans les journaux doivent donc être imputables et intègres dans le temps. Pour y arriver, l’organisation peut soit se reposer entièrement sur des processus idoines pour s’assurer de la conservation des ses archives soit mettre en place des mécanismes techniques et des procédures moins contraignantes pour le métier.
Parmi ces exigences complémentaires pour avoir un système conforme à la norme se trouve la mise en place des mécanismes suivants:
- Signature électronique et horodatage des attestations d’opérations et événements de façon unitaire ou par lots
-
- Horodatage qui peut soit être interne (exigence minimale) ou être externe en faisant appel à un tiers horodateur
- Périodicité d’archivage des journaux
Si vous avez lu mon article sur le fonctionnement de la blockchain, vous devez commencer à comprendre ou je veux en venir. Sinon je vais vous éclairer dans la suite.
La notion d’attestationUne attestation électronique est un « ensemble d’éléments permettant d’assurer qu’une action ou un échange électronique a bien eu lieu ». Il s’agit ni plus ni moins que d’une transaction.
Dans un système d’archivage qui respecte la norme NF-Z 42-013, les attestations sont produites pour chaque action et sont signées par l’acteur ou l’organisation qui a réalisé l’action. Elle contiennent non seulement l’identifiant de l’objet manipulé mais aussi son empreinte (avant et après manipulation le cas échéant). Ces attestations sont stockées dans des journaux les unes à la suite des autres. En fin de journée, le journal est clôturé et archivé comme n’importe quelle archive.
Son archivage donne donc lieu à une attestation de dépôt dans le journal qui vient d’être ouvert pour la journée suivante. On dit alors que les journaux sont scellés et chaînés. Comme les blocs d’une blockchain.
Si l’on souhaite modifier une archive intentionnellement, il faut alors être capable non seulement de resigner l’archive générée mais aussi de modifier tous les journaux jusqu’au dépôt initial. Ce qui est très coûteux.
Imaginons une blockchain documentaireUne entreprise dispose en interne d’une solution d’archivage électronique. Cette solution repose sur une blockchain partagée par toutes les entreprises souhaitant conserver la valeur probatoire de leurs archives. Dans la suite, elle est même utilisée par les Archives Nationales. Cette blockchain contient tous les éléments de traçabilité des archives cités plus haut.

Blockchain et Arbre de Merkel | Wikimedia, CC BY-SA 3.0
Versement d’archivesUne archive est versée dans le système d’archivage d’une entreprise. Une attestation est produite. Cette attestation contient notamment l’empreinte du fichier et des métadonnées. Elle est signée avec la clé privée de l’entreprise.
Elle est alors transmise aux nœuds du réseau qui réalisent le minage pour constituer le bloc. Dans le bloc, on retrouve un timestamp qui fait office de tiers horodatage.
L’intégrité et l’imputabilité de notre archive est alors assurée. En effet, pour modifier le bloc, il faudrait modifier tous les blocs de toutes les blockchains des noeuds ainsi que leurs blocs suivants. Mission Impossible !
Consultation d’archivesUn utilisateur souhaite accéder à une archive électronique via l’interface de consultation. Le système se connecte à la blockchain et via la référence de la transaction vérifie l’intégrité du fichier et d’autres informations stockés dans le système. En cas de succès, la système présente à l’utilisateur l’archive demandée.
Modification d’une métadonnéeSupposons qu’il soit nécessaire de modifier une métadonnée de notre archive. L’utilisateur la modifie dans le système ce qui génère une nouvelle attestation. Celle-ci référence la précédente afin de chaîner les actions sur l’archive. Elle est signée avec la clé privée de l’entreprise puis transmise aux nœuds du réseau.
Migration de formatAu fil du temps, les technologies évoluent et les formats de fichier peuvent devenir obsolètes. Le risque est alors grand de ne plus pouvoir ouvrir les fichiers si l’on ne dispose plus les logiciels adéquats. Les archives deviennent donc illisibles.
Afin de remédier à cette situation, des migrations de formats peuvent être opérées. Ces migrations sont réalisées dans le cadre de projets qui vont non seulement réaliser la conversion mais aussi s’assurer que l’archive est toujours lisible et fidèle à l’original.
Lors des opérations de conversion et de vérification, des attestations sont produites qui sont transmises aux noeuds du réseau. Afin de renforcer la confiance de cette migration, les étapes de vérifications pourront toujours être réalisées par un tiers qui alimentera la blockchain en attestations de vérification.
Transfert d’archivesMon entreprise est une entreprise semi-publique. Elle a donc des obligations envers les Archives Nationales. A ce titre elle doit lui transmettre les archives jugées comme ayant un intérêt historique.
Une fois la liste établie, l’entreprise réalise le transfert des archives et produit pour chacune d’elle une attestation de transfert d’archives en la signant avec sa clé privée et la clé publique des Archives Nationales.
Il n’est pas nécessaire de transférer les journaux puisqu’ils sont partagés entre tous les nœuds du réseau. Les Archives Nationales peuvent alors réaliser leurs propres actions de conservation sur les archives transférées.
Pourquoi la blockchain au lieu d’un système interne ?La reconnaissance du caractère de preuve d’un document repose sur les moyens mis en oeuvre pour assurer l’imputabilité et l’intégrité des archives. Ces moyens peuvent être techniques ou organisationnels.
L’intégrité globale d’un système d’archivage repose sur les moyens préventifs en terme de sécurité mis en oeuvre par l’organisation. Sans ces moyens il devient plus facile d’attenter à l’intégrité des archives.
Je vois donc deux avantages à un système de blockchain par rapport à un système interne :
- Le coût : Point discutable puisque les systèmes d’archivage électronique à valeur probatoire existent déjà. Cependant ils sont encore très peu nombreux et les licences très coûteuses (cela se compte en centaines de milliers d’euros). Ainsi, pour se dégager d’une partie des mesures de sécurité pour assurer l’intégrité, les entreprises sont tentées de faire appel à des tiers qui nous offrent un niveau d’abstraction supplémentaire (horodatage, signature, tiers archivage). Ces services tiers ont aussi un coût d’entrée et un coût récurrent qui dépend du volume archivé. En se reposant sur un système décentralisé telle qu’une blockchain, il s’agit de faire supporter le coût de la gestion de l’intégrité de vos archives à la communauté. Idéalement, cette blockchain aura été mise en place par les Archives Nationales qui ont un fort intérêt dans le domaine.
- Une assurance d’intégrité plus forte : Comme décrit précédemment, l’intégrité repose essentiellement sur la tenue des journaux. Il est bien plus facile de casser l’intégrité d’un journal (moyennant l’accès au support de stockage) que de casser l’intégrité de N journaux vérifiés constamment par N tiers grâce à la technologie Blockchain.
Image d’entête: National Archives Film Canisters, Mr.TinDC, CC BY-ND 2.0
Cet article Une blockchain pour l’archivage à valeur probatoire est apparu en premier sur Kevin Lagaisse.
Hacker le monde réel avec les ondes radio et les capteurs
Depuis quelques temps, je m’intéresse aux objets connectés, aux ondes radio et aux villes intelligentes en tant qu’usager et aux possibilités qu’il y aurait à hacker le réel au bénéfice des citoyens. Quand je dis hacker, je n’envisage pas de m’introduire dans les systèmes des entreprises ou des personnes. Il s’agit plus précisément de voir comment, de manière très simple, il est possible d’exploiter des informations présentes autour de nous mais invisibles en temps normal.
Sans entrer dans de grandes théories sur ce que doit être une ville intelligente, nous avons je pense tous été confrontés à un moment ou à un autre à la difficulté de vérifier un ressenti que l’on a dans la rue, dans les transports, dans un parking avec des choses du réel. A nous demander « et si je pouvais le mesurer, là, tout de suite ? »
Histoire n°1 : Il fait froid dans les transportsCela m’est arrivé dans les transports pendant l’hiver 2014-2015 où je trouvais que, malgré les annonces faites par la RATP sur la modernité des systèmes de climatisation des trains, je n’avais pas vraiment l’impression que c’était si efficace que cela. Il y faisait soit trop chaud soit trop froid, et c’est un reproche qui est semble-t-il partagé par bon nombre de voyageurs.
Pour en avoir le coeur net, il fallait que je mesure la température dans le wagon du train. Mais comment ? La première idée est de prendre un vieux thermomètre à mercure et de mesurer le température immédiate. Sauf que ce n’est pas suffisant de mesurer une seule fois, il faut le faire sur la longueur du trajet. Les portes du train s’ouvrent, la climatisation peut disjoncter au passage d’une jonction électrique…
Prendre un crayon et noter les mesures ? Je me dis que je ne vais tout de même pas faire cela à l’heure du tout numérique (on en reparlera plus tard).
Je me mets donc à la recherche d’un capteur autonome capable d’enregistrer des mesures.
Vous connaissez Texas Instruments ? Mais, si ! Le fabricant de votre calculatrice au collège ! Et bien Texas Instruments est avant tout fabricant de semi-conducteurs.
Afin de démontrer les capacités de ses puces bluetooth, le fabricant propose des démonstrateurs embarquant des capteurs.
Ni une ni deux, je commande sur le site d’un distributeur. Une fois le produit reçu, l’application compagnon téléchargée et l’apairage entre le module et le téléphone fait, il ne me suffisait plus qu’à prendre les transports.

Kit de développement Ti Sensor Tag CC2541
Parmi les fonctionnalités:
- Capteur de température ambiante : C’est justement pour cela que je l’ai acheté.
- Capteur de température infrarouge : Pratique pour mesurer à distance la température d’une surface qui serait soumise à un flux de ventilation (ma peau ou une vitre par exemple).
- Capteur d’humidité : Parfait pour mesurer le degré de promiscuité dans les transports.
- Magnétomètre : Je n’ai pas trouvé d’utilité immédiate à cette fonction
- Baromètre : Pour jouer à Señor Météo.
- Accéléromètre : Intéressant pour mesurer le niveau de délicatesse de nos conducteurs.
- Gyroscope : Pour mesurer les mouvements angulaires au cours du voyage.
Il dispose aussi de deux boutons de service utiles pour vos développements, parce qu’à la base, c’est fait pour cela.

interface du logiciel pour le Sensor Tag CC2541
Le produit enregistre toutes les secondes les données dans un fichier qu’il est possible d’exporter. Fini le calepin et le crayon !
Conclusion de cette histoire:- La température est bien régulée comme promis par la RATP.
- Il fait 19-21°C en plein mois de décembre dans les trains.
- C’est le flux d’air qui donne un ressenti plus chaud ou plus frais.
- Il peut faire jusqu’à 5°C en sortie des ventilations sur les plateformes.
Parmi les usages, je me suis imaginé qu’avec cet ensemble de capteurs très peu coûteux (25€) on pouvait collecter des données intéressantes sur les voyages et communiquer auprès des voyageurs:
- Afficher la température extérieure et intérieure sur les écrans d’informations. C’est bête mais c’est un élément de communication fort vis-à-vis du voyageur qui se plains des température dans les trains de banlieue.
- Afficher la vitesse et l’accélération du train pour savoir si l’on se traîne vraiment ou si le cycliste qui nous dépasse a pris des vitamines avant de partir.
- Vérifier l’état des voies en analysant les données du gyroscope et de l’accéléromètre. Le passage d’un train sur un élément de voie abîmé donnerait des informations gyroscopique et accélérométrique anormales par rapport à d’autres trajets du même type.
- Diffuser la position exacte du train en plaçant des tags de type NFC, qui coûtent quelques centimes, le long du trajet (poteaux, murs). Ces tags seraient détectés par le train afin de fournir une localisation plus précise que les balises actives (et donc très coûteuses et à entretenir) positionnées le long des voies actuellement.
A l’hiver 2014-2015 toujours, il faisait un froid glacial au bureau passé 11h. La maintenance avait beau venir régler le thermostat de notre bureau, dire que tout était réglé, nous avions avec les collègues l’impression de vivre “le jour d’après” en plein mois de janvier.

Mes collègues et moi arrivant au travail | Le Jour d’Après de Roland Emmerich | 20th Century Fox
Aucune idée de la température qu’il y faisait. Le thermostat indiquait 26°C. Le technicien appelé à la rescousse nous annonce: “La sonde se trouve sous le plancher, Monsieur, mais de l’autre côté de la cloison”. Suis-je bête, c’est logique… Je me demande encore aujourd’hui, pourquoi des sondes de température ont été posées si éloignées des souffleries, au point qu’elles se retrouvent dans une autre pièce.
Ici, pas de nouveau capteur. J’ai mon super capteur autonome. Il m’a suffit de le poser sur une table pour connaître la température : 18°C.

Temperature du bureau
Conclusion de cette histoire:On a froid, on le sait mais le fait de ne pas avoir d’information chiffrée nous fait douter de nous-mêmes : « le thermostat indique pourtant 26°C, cela doit bien fonctionner, et puis les techniciens sont passés et ont dit que tout était ok; cela doit donc venir de moi ».
Usages imaginés dans les tours de bureaux:- Avoir cette fichue température affichée dans le bureau ! Comme cela, on sait que l’on ne rêve pas.
- Pouvoir brancher des capteurs de température autonomes aux thermostats via radio-fréquence. Je ne sais pas qui a conçu les tours mais mettre des sondes dans le sol, ce n’est pas très malin, éloignées de souffleries encore moins. Pouvoir positionner des sondes autonomes au grè des mouvements de cloison des étages serait un grand pas en avant.
- Dans le même esprit, avoir des interrupteur appairés avec les éclairages par radio-fréquence permettrait d’éviter d’éteindre le bureau du voisin en même temps que le sien.
- Plutôt que de passer par un site inadapté ou un appel téléphonique à l’autre bout du monde, il serait malin de multiplier à côté des équipements la présence de bouton Dash de Amazon pour déclencher automatiquement une opération de maintenance (fonctionne aussi dans les transports, dans la rue, …).
Je me baladais sur l’avenue le coeur ouvert à l’inconnu, … Oui donc, pendant mes trajets, je me renseignais sur les transports, et la transmission des incidents jusqu’aux voyageurs, et j’ai appris à l’occasion d’un incident que cela se faisait par radio. Lors de cet incident, le conducteur nous annonce « suite à une alerte radio, notre train est immobilisé pour une durée indéterminée, je me renseigne schkrkrkrkrkr[bruit de fond de radio] et je reviens vers vous »
Un petit coup de google et j’apprends que les alertes radios sont des messages automatiques émis par les trains sur une fréquence que je n’ai pas trouvée, dans un encodage qui date un peu (et c’est un avantage). J’apprends aussi que la SNCF expérimente la radio par GSM (le GSM Rail) pour remplacer son système analogique. D’ailleurs le GSM Rail fonctionne sur les bandes de fréquences du GSM et que cela pose problème avec certains opérateurs (ceux dans les bandes 800MHz et 900MHz).
Je vous avoue que pour les alertes radios je ne suis pas allé plus loin sauf à connaître quelqu’un à la SNCF qui peut m’envoyer la spécification. Les alertes sont si peu fréquentes (quoique, ca commence à être de moins en moins vrai) que je risque d’y passer 10 ans à trouver la bonne fréquence et le codage.
Je me suis donc intéressé à la radio audio parce que sur les trains de banlieue, la radio est toujours en analogique et risque de le rester encore pour longtemps.

Fréquences radio
Je sais qu’on ne voit toujours pas le rapport avec les avions mais on va y venir.
En sortant des transports, je passe par la station de bus, devant un parking Vinci (on dit Indigo maintenant). Chacun de ces lieux est équipé de panneaux qui affichent des informations : le prochain passage du bus, le nombre de places disponibles dans le parking… Chaque panneau est équipé d’une antenne. Références des panneaux prises, je fais une recherche google et apprend que les panneaux de bus (des Lumiplan Oscar 2) sont équipés de systèmes GSM et comme le GSM est chiffré, cela va être compliqué d’y accéder. Par contre, je tombe sur twitter sur une personne qui a réussi à écrire sur les Panneaux de Jalonnement Dynamique affichant les places de parking (des Optifib PJD). La taille de l’antenne (un quart d’onde en général) donne la fréquence.
Je me mets alors en quête d’un moyen d’écouter tout cela. Je sais que je n’aurais pas forcément le temps de tout décoder mais au moins j’aurais déjà expérimenté la chose en vrai et me rendrais compte de la difficulté/facilité qu’il y a d’accéder à ce type d’information.
Je trouve sur internet que l’on peut accéder en réception à un spectre de fréquences radio relativement large avec une simple clé USB TNT à quelques euros, de 22MHz à 2200MHz. Oui une simple clé USB pour écouter ce qui nous entoure. Plusieurs modèles sont disponibles, certains ayant un spectre plus large mais avec un trou de fréquences au milieu (entre 1100MHz et 1250MHz).
Je lis aussi que les avions diffusent des informations de postionnement par radiofréquence (ADS-B pour Automatic dependent surveillance-broadcast sur 1090MHz) et que si l’on est proche d’un aéroport, on peut entendre les directives des contrôleurs aériens .
Je m’équipe donc du dongle USB fraichement recu et j’installe un logiciel de visualisation de spectre (SDRSharp pour windows ou gqrx pour mac).

SDRSharp avec filtrage audio
Avec cette clé à 20€ j’ai pu:
- Ecouter la radio AM et FM. C’est bête mais on peut le faire directement depuis le logiciel pour vérifier que tout fonctionne bien.
- Ecouter la radio numérique terrestre, très peu répandue en France.
- Lire les messages texte de type Tatoo/Tamtam émis par des équipements industriels depuis notamment Rungis (POCSAG), les messages émis par les services de sécurité comme ceux d’un grand parc d’attraction (un monsieur s’est foulé une cheville un jour).
- Ecouter la radio interne de la SNCF sur le réseau régional. Elle émet en FM et on y entend les flash d’information des régulateurs à destination des conducteurs (ce qui est très intéressant quand les voyageurs ne sont pas prévenus d’un incident) et les prises de service.
- Ecouter la borne de taxi de mon quartier qui transmet les appels des clients en FM. Aucun intérêt.
- Ecouter les instructions d’un contrôleur aérien.
- Visualiser une partie des avions qui se trouvent dans un rayon de 300km environ autour de Paris.

Visualisation des informations ADB-S sur une carte
Je n’ai pas réussi à écouter ou à voir:
- La fréquence des panneaux de parking. Je crois avoir trouvé la fréquence, mais il faut faire du reverse engineering sur le signal et je n’ai pas trop le temps.
- La télérelève de mes compteurs. Je sais qu’ils fonctionnent par ondes radio mais je n’observe rien depuis mon compteur calorifique présent dans les parties communes. Je pense qu’il est branché à un concentrateur m-Bus dans l’immeuble qui lui est en RF. En attendant, je fais des relevé réguliers à la main pour voir ma consommation de chauffage l’hiver (oui je suis frileux) et d’eau toute l’année.
- Mes appareils domotiques. Peut-être les messages sont-ils très courts et je n’y ai pas prêté suffisamment attention.
- Les images de video semi-embarquées de la SNCF. Legifrance indique une autorisation dans les 50MHz pour la transmission des images.
- Récupérer les images envoyées par les satellites météo. Là je n’ai pas eu le temps d’aller jusque là mais ca a l’air relativement simple.

Ecoute d’une radio FM avec GQRX
Morale de l’histoireCe qui est intéressant dans tout cela, c’est qu’énormément de données circulent en clair dans les airs mais il faut du temps pour les récupérer et les analyser.
Pour les données de type télémesure, il m’a été impossible d’y accéder et ca me semble être l’usage domestique le plus intéressant. Un peu d’aide serait bienvenu.
Pour les usages plus professionnels et si l’on se projette dans une ville intelligente, on imagine pouvoir barder de capteurs nos équipements publics et les transmettre à un concentrateur pour analyser ces données et décider d’activer d’autres équipements en conséquence, comme par exemple des éclairages, de la signalisation, des indications de circulation ou de déviation, des informations de disponibilités de capacité…
[EDIT du 04/02/2016]
Conclusion provisoireTrois jours après avoir publié cet article je n’en suis toujours pas satisfait. L’objectif était de raconter sous formes d’histoires qui se sont réellement produites la manière dont il est possible d’explorer les radio-fréquences. A partir de là, j’envisageais d’aller plus loin dans mes recherches et je ne voulais pas conclure.
Je pense cependant qu’il faut une conclusion provisoire à cet article.
Ainsi, de ces premières expérimentations, j’en retire déjà trois choses :
- L’invisible devient facilement visible. Il y a 15 ans, pour explorer ce domaine, il était nécessaire d’acquérir des équipements coûteux (plus de 1000€) et avoir des compétences en informatique et en électronique d’un bon niveau. Aujourd’hui ce domaine est devenu accessible financièrement (on parle de 25€) et de nombreux logiciels existent gratuitement.
- La ville intelligente ou les services intelligents sont accessibles à n’importe qui. Il suffit d’en imaginer les usages. J’ai tenté au cours de mes histoires d’imaginer ce que l’on pourrait faire avec ces objets mais il ne s’agit que de débuts d’idées à confronter avec d’autres. Pour faire le lien avec mon article sur l’innovation dans le conseil, je pense que c’est typiquement le genre d’activité qu’il est possible de faire en groupe en incluant des ingénieurs de nos clients afin de développer de nouveaux services.
- Enfin, si l’invisible devient visible facilement, il n’est pas forcément compréhensible immédiatement. Et c’est la limite que j’ai vue quand il s’agissait d’aller plus loin. il faut encore des compétences d’une part mais surtout du temps pour traiter les signaux que l’on reçoit.
Je reviendrai plus précisément dans d’autres articles sur l’utilisation de l’un ou l’autre des capteurs et sur la manière de décoder des signaux. En attendant, je vous laisse une liste de ressources pour que vous puissiez faire vos propres expériences et les partager.
Liste des ressources- Acquérir le kit de développement de Texas Instruments
- Acquérir la clé TNT
- Comparer les capacités des différentes clés et ce que l’on peut faire avec
- Visualiser le spectre de fréquence :
- Rediriger l’audio dans un autre logiciel :
- sur windows : VB audio cable
- sur mac : essayez JackAudio
- Décoder le POCSAG : multimon-ng sur mac et pocsag-pdw sur windows
- Décoder les données ADS-B : dump1090 sur mac ou dump1090 sur windows
- Identifier un signal par sa forme
- Fréquences d’émission de la SNCF
- Carte des faisceaux hertziens (là on part au delà des capacités de la clé)
- Calculer la longueur de l’antenne en mètre : 300 000 / fréquence / 4
Et comme vous avez tout lu jusqu’au bout, voici un petit intermède musical:
Cet article Hacker le monde réel avec les ondes radio et les capteurs est apparu en premier sur Kevin Lagaisse.
La blockchain, qu’est-ce que c’est ?
On lit depuis quelques mois que la blockchain est une révolution qui va disrupter la banque. Ca a l’air cool. Mais au fait c’est qui cette chaîne de blocs ?
J’ai donc voulu faire un article pour moi-même afin de résumer les grands principes. Il est volontairement axé sur le fonctionnement de la blockchain, plus sur les cinématiques que sur les usages ou le fonctionnement technique. Pour les usages, vous avez de très nombreuses news qui circulent qui vous vantent les bienfaits de la blockchain. Pour les articles plus techniques, je n’en retiendrai qu’un seul en bas de cette page.
La blockchain qu’est-ce que c’est ?La blockchain se résume à un grand registre dupliqué sur les noeuds d’un réseau et sur lequel on inscrirait tous les événements que l’on souhaite tracer.
Chaque noeud du réseau est chargé de le tenir à jour et de vérifier les inscriptions qui y sont faites. Chaque noeud dispose du registre au complet. C’est pour cela que le démarrage de Bitcoins est un peu lent. Il faut télécharger la blockchain au complet – environ 1 Go en ce moment.
L’objectif du système de blockchain est d’assurer l’intégrité des informations qui y sont saisies. Pour bitcoin, il s’agit de transactions de monnaie. Mais on pourrait y mettre d’autres choses. skaï’z ze limit.
La transactionUne transaction, c’est un contrat entre deux personnes sur des termes définis. Afin de rendre ce contrat acceptable entre les parties, les deux représentants de ces parties le signent pour signifier leur accord.
Ainsi chaque utilisateur qui souhaite inscrire une transaction dans le registre dispose d’une clé sécrète et d’une clé publique. La clé secrète sert à apposer la notion d’émetteur – on peut le vérifier avec la clé accessible publiquement – et la clé publique la notion de propriété – seul celui en possession de la clé secrète peut lire le message.
C’est sur ce principe que repose bitcoin pour gérer les transactions. Dans un grand livre de compte réparti au travers du réseau, des transactions sont inscrites avec la date, l’objet de la transaction (le montant pour les bitcoins), l’émetteur, le bénéficiaire ainsi qu’une énigme pour pouvoir réutiliser le contenu de la transaction – les bitcoins en question dans le cas de bitcoin. Souvent il s’agit uniquement de la signature du bénéficiaire, mais on peut très bien imaginer qu’il faille aussi la signature de son conjoint pour pouvoir débloquer le contenu de la transaction et le lier à une nouvelle transaction.
Notre transaction étant constituée, elle est transmise au réseau pour être ajoutée avec d’autres transactions dans un bloc de la chaîne.
Le blocUn bloc c’est une page du livre de compte. Les pages du livre de compte sont numérotées. La page 5 est donc située après la page 4.
Techniquement, chaque bloc s’ouvre avec une transaction qui est l’empreinte du bloc précédent – c’est l’équivalent du numéro de page. Le noeud reçoit des transactions des autres noeuds au fil du temps et constitue un bloc avec ceux-ci en les rangeant dans l’ordre de leur arrivée comme on écrirait les transactions sur la page courante.
Un arbre de hashage – Arbre de Merkle – est construit de manière à obtenir la signature de toutes les transactions du bloc dont il est possible de vérifier rapidement l’intégrité.
Blockchain et Arbre de Merkel| Wikimedia, CC BY-SA 3.0
À partir de là il suffirait d’envoyer son bloc dans le réseau pour qu’il soit pris en compte. Sauf qu’avec ce principe rien n’empêche de spammer un réseau ouvert avec des blocs.
Par contre, on peut le rendre tellement coûteux que cela n’en vaut pas la peine.
Ainsi dans chaque bloc, on a introduit un “nonce” qui est un numéro que l’on ajoute dans le bloc, afin de résoudre un défi. L’objectif de ce défi est assez simple puisqu’il s’agit d’obtenir une empreinte du bloc avec beaucoup de zéros consécutifs au début. Autant dire que le processeur est mis à contribution pour arriver à ce résultat. Et c’est justement parce que le bloc a été coûteux à constituer qu’il fait foi auprès du réseau – outre le fait qu’il soit intègre.
A noter que l’opération qui consiste à trouver la “plus petite” empreinte possible s’appelle le minage – et là on raccroche les wagons avec le mining dont on nous rabâche les oreilles depuis des années sur le bitcoin.

Golden Ticket |Charlie and the Chocolate Factory, Tim Burton, Warner Bros. Pictures
A ce stade, on a réussi à prouver que le bloc a nécessité une certaine somme de travail et qu’il peut être pris en compte par réseau. il ne s’agit pas d’un spam.
La BlockchainÉvidemment, notre noeud n’est pas le seul à miner et d’autres blocs sont envoyés au réseau. Ces blocs peuvent d’ailleurs contenir des transactions contenues dans notre bloc et d’autres transactions que nous n’avons pas encore reçues. Ils peuvent aussi référencer le même bloc parent ou un autre bloc de la chaîne.
Heureusement le système de blockchains est fait pour qu’il n’y ait qu’une seule chaîne de référence qui fait foi auprès de tous les noeuds.
Quand les blocs arrivent, ils sont vérifiés. S’ils sont bien formés, ils sont ajoutés à la chaîne de bloc et le minage démarre à partir de ce nouveau noeud.
Sauf que parfois, deux ou plusieurs blocs peuvent être générés dans un lapse de temps rapproché et transmis au réseau. Une bifurcation est alors créée pour stocker le second bloc en attendant que l’anomalie soit résolue avec l’arrivée du bloc suivant. Au final c’est la branche la plus longue qui est prise comme référence par tous les noeuds. Cela se résout assez rapidement.
C’est pour cela qu’il faut attendre un peu de temps (6 blocs d’après ce qu’on lira ici et là) pour confirmer une transaction afin d’être sûr que la transaction soit présente sur la chaîne principale.
Pour aller plus loin, il y a le papier original de Satoshi Nakamoto sur le bitcoin
Mais s’il ne fallait retenir qu’un seul article je ne peux que conseiller celui-ci que je viens de découvrir :
https://www.igvita.com/2014/05/05/minimum-viable-block-chain/
On remarquera qu’il y a quelques petites différences par rapport à la blockchain de bitcoin mais tout est décrit dans le détail avec les raisons de chacun des choix. Une référence pour moi.
Image d’entête : Bitcoin Chain, BTC Keychain, CC BY 2.0
Cet article La blockchain, qu’est-ce que c’est ? est apparu en premier sur Kevin Lagaisse.
Uberization of everything : le côté pervers de l’argent d’Uber
Vous connaissez les GAFA – Google, Apple, Facebook, Amazon ? Oubliez-les ou presque. Voici Netflix, Airbnb, Tesla et Uber, les NATU.
Alors que les GAFA dominent le monde du numérique, les NATU font… la même chose.

les NATU : Netflix, Airbnb, Tesla, Uber
Comme pour les GAFA, dans les NATU, on retrouve des choux et des carottes. Dans chacun des deux groupes, nous n’avons qu’un seul constructeur, Apple d’un côté et Tesla de l’autre. Mais ce qui m’intéresse, ce sont Airbnb et Uber. Ils font le même métier : la “mise en relation”.Grâce à eux, nous avons le droit à de nouveaux mots : disruption et uberisation (airbnbisation c’était plus dur à prononcer, désolé les mecs).
On voit donc fleurir ces nouveaux concepts dans les présentations, les articles de presse et les discours des consultants. L’avenir de l’économie est à l’uberization. Uberization of everything ! Faites votre révolution digitale si vous ne voulez pas perdre votre marché ! Disrupt eveything !
Une chose est claire, Airbnb et Uber ont réussi là où les acteurs historiques ont échoué : la simplicité d’accès et la qualité de service – quoi que, pour le second point, ca commence à ne plus être si vrai.
En n’incluant pas le numérique dans leur ADN, les taxis ont laissé la porte grande ouverte à de nouveaux entrants capables répondre aux attentes clairement exprimées par les consommateurs depuis des années. Ajoutez à cela une communication léchée sur une qualité de service aux antipodes de leurs concurrents et vous avez un appel d’air mérité vers ces services.

Uberization of everything : l’application Uber | Uber
Sauf qu’il y a des côtés pervers à l’uberization L’uberization crée de la précaritéL’uberization est une forme d’esclavage moderne ou de proxénétisme car il vise à exploiter du travail d’autrui sans en assumer aucune responsabilité. l’Uberizeur c’est celui qui se place entre le client et le travailleur pour ponctionner une partie du revenu qui aura été fixé par avance par l’uberizeur. Et quand l’uberizeur décide de baisser les tarifs, le travailleur n’a plus qu’à se plier aux désirs de son maître ou à abandonner le métier.
L’uberization ne crée pas de la qualitéEn ne contrôlant pas ceux qui fournissent le service, les uberizeurs peuvent laisser entrer le loup dans la bergerie. On ne compte plus les histoires, sur airbnb, de logements très loin des photos ou des commentaires du site, de voyageurs qui se retrouvent à la rue parce que le loueur a pété un cable quand on lui dit que quelque chose n’allait pas, de jeunes femmes qui font une très mauvaise rencontre. Mais aussi sur Uber, quand le chauffeur décide de vous faire visiter trois fois Paris avant de vous amener à destination et/ou de vous casser le nez si votre tête ne lui revient pas trop.
D’ailleurs cette situation s’explique facilement. Pour avoir une certaine qualité de service, il est nécessaire d’avoir un minimum de middle management. Sauf que le middle management est de la responsabilité du client chez Uber ou airbnb. A ce titre, je vous invite à lire cet article sur le sujet.
D’un autre côté, il y a un effet pervers positif inattendu à l’uberization à savoir que :
L’uberization permet de se libérer de l’uberizationQuand Uber a baissé ses tarifs, de nombreux chauffeurs se sont collectés afin de lancer leur propre application (110 000€ tout de même). Ils ont pour ambition de proposer un service, toujours de qualité, mais plus respectueux des travailleurs qu’ils sont.

Uberization of everything : Timmy invente une nouvelle categorie de transport individuel | South Park
Des agriculteurs ont créé leur propre site internet afin de vendre leur production sans être tributaires des centrales d’achat qui leur imposaient des conditions commerciales toujours moins profitables.On retrouve là ce qu’aurait dû être l’essence même de l’uberization. Favoriser une économie du partage qui ne serait pas dans les mains de quelques groupement d’intérêts qui verrouillent les accès aux consommateurs comme le font les mafias.
En attendant, Ohlala veut devenir le Uber de la prostitution. Logique.

Cet article Uberization of everything : le côté pervers de l’argent d’Uber est apparu en premier sur Kevin Lagaisse.
Des blockchains pour gérer l’intégrité documentaire
Le système blockchains sur lequel se base Bitcoins permettrait de tracer de manière décentralisée l’intégrité des empreintes de documents ou des signatures.
Je le vois bien remplacer dans quelques temps les systèmes de gestion de preuve dans les systèmes d’archivage NFZ 42-013.
@Vieilfrance @fcauchi ça remplace la signature électronique et l'horodatage en le transférant d'un tiers2confiance à un système décentralisé
— Kevin (@kevinlagaisse) October 9, 2015
En vrai, ça remplace le scellement et horodatage.
EDIT : 03/03/2016
Allez voir mon article Une blockchain pour l’archivage à valeur probatoire pour plus de détails
Cet article Des blockchains pour gérer l’intégrité documentaire est apparu en premier sur Kevin Lagaisse.
Pagina's







")

































































")

")






























")























")







")
")
")




")
")







]")







")
")



































")






")
")

")

















")








")






")

")






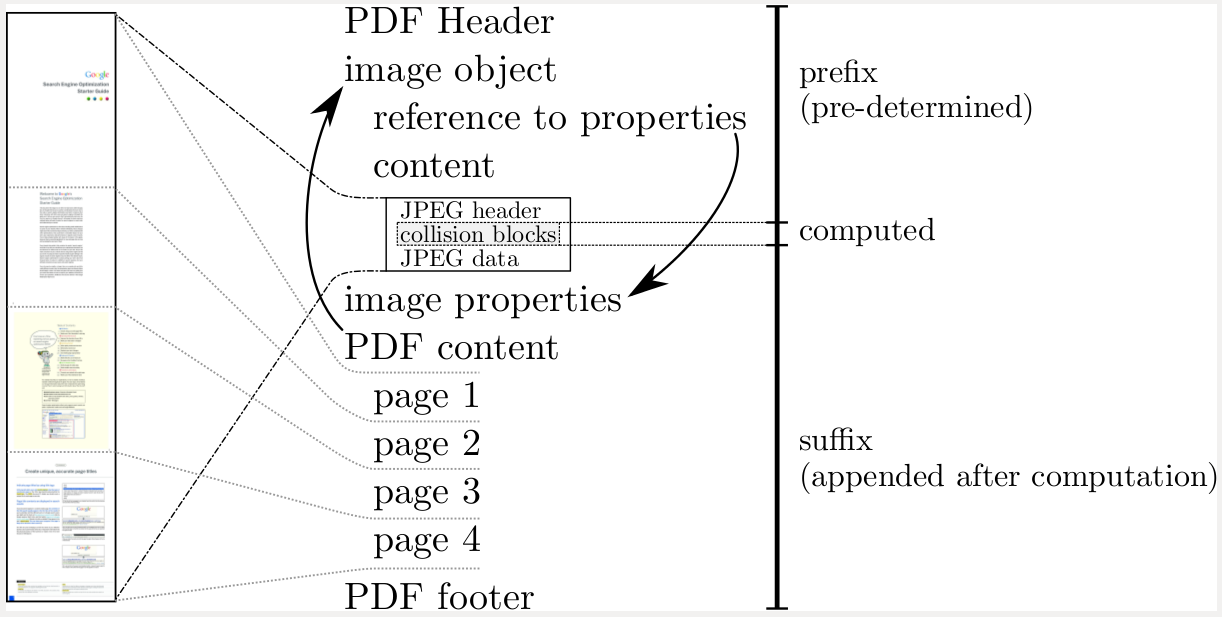{kind=link}