U bent hier
Voortbestaan
Embroidery Formats
There are certain file formats which seem to be fairly mainstream and come up frequently from a variatey for sources. Then you find one from a specialized niche industry. I recently came across a file with the HUS extension and it led me down a path of a family of formats I didn’t know existed. The world of embroidery formats has been around for quite some time and is quite confusing. There are many manufacturers of embroidery machines and over the years have merged with each other or upgraded to include new features all requiring changes to the file formats used by the systems.
Embroidery stitching designs are a unique file formats. They are images, probably vector, but with stitching information included in the file which determines the color of thread used and pattern used.
I took a data set of many different embroidery files from here and ran it through Siegfried.

That is pretty bleak. Not a single file identified except a few using an OLE container and a couple files which may be plain bitmaps. I have started to document where each of these formats come from on the File Format Wiki, but there are so many formats to research. The triple XXX format research has its other challenges…..
Today I wanted to focus on one brand, Husqvarna, a Swedish company with a long history.
 Export Formats in Premier+ Software
Export Formats in Premier+ Software
Husqvarna has made sewing machines or quite some time. In the late 1970’s machines started to enter the market which were “computerized”. It was in the early 1990’s when the embroidery machines could take a memory card full of stitching patterns, then later could take a floppy disk or USB drive full of custom made designs. Let’s take a look at a few of the formats, starting with the extension .HUS.
First a sample with a 1994 last modified date:
hexdump -C Bow.hus | head 00000000 5b af c8 00 1a 09 00 00 01 00 00 00 98 01 67 01 |[.............g.| 00000010 6f fe 9b fe 2c 00 00 00 47 00 00 00 0e 07 00 00 |o...,...G.......| 00000020 00 00 00 00 00 00 00 00 00 00 07 00 00 10 38 84 |..............8.| 00000030 81 af f8 d9 6e bc 5e c1 b4 1d fc b2 00 00 00 0c |....n.^.........| 00000040 93 03 49 98 00 e5 f0 07 41 77 75 c6 49 c6 ff e2 |..I.....Awu.I...| 00000050 80 aa aa 08 00 28 82 a8 b2 49 27 5e dd ae ba ee |.....(...I'^....| 00000060 db 78 05 bc 4b ef 00 37 f0 da db b5 d6 ee 93 9e |.x..K..7........| 00000070 55 15 01 00 44 00 05 51 01 3e 16 cf db ce 2c bc |U...D..Q.>....,.| 00000080 ad db 48 97 cb e5 f2 fe fc 63 79 e7 a3 a1 46 80 |..H......cy...F.| 00000090 5c 37 f0 10 41 43 a1 40 21 c7 a5 d2 6e 82 0a 20 |\7..AC.@!...n.. |Then one from around 1996:
hexdump -C ROSEBUD.HUS | head 00000000 5b ff c8 00 5f 0b 00 00 04 00 00 00 ce 00 69 01 |[..._.........i.| 00000010 01 ff 17 fe 3a 00 00 00 66 00 00 00 97 09 00 00 |....:...f.......| 00000020 00 6b 6e 6c 6a 6b 00 00 00 00 0a 00 19 00 1a 00 |.knljk..........| 00000030 0e 00 1a 00 05 00 a4 a2 00 10 00 19 42 88 80 35 |............B..5| 00000040 ff 4d 96 0d c1 72 49 6e 09 00 c8 72 ee 90 76 93 |.M...rIn...r..v.| 00000050 47 ca 20 00 00 4a 32 b1 d4 d4 08 e1 e7 86 d3 50 |G. ..J2........P| 00000060 20 0f 2f 1a 63 e0 09 66 7e ed f0 85 b9 37 fd 12 | ./.c..f~....7..| 00000070 2c 89 09 01 02 00 30 33 33 00 44 96 4b 36 49 65 |,.....033.D.K6Ie| 00000080 bd d7 77 7e df bb cd f4 9b db e7 6f 5b 76 ed b1 |..w~.......o[v..| 00000090 2d b6 49 08 03 31 81 8c 00 02 44 91 22 24 b2 5f |-.I..1....D."$._|And another from 1998:
hexdump -C FLOWER.HUS | head 00000000 5d fc c8 00 de 23 00 00 04 00 00 00 79 01 e5 01 |]....#......y...| 00000010 87 fe 1b fe 32 00 00 00 e0 00 00 00 51 1b 00 00 |....2.......Q...| 00000020 00 00 00 00 00 00 00 00 00 00 0e 00 03 00 0c 00 |................| 00000030 05 00 00 69 53 6d 82 36 bf f0 d8 7a 55 c1 0b b6 |...iSm.6...zU...| 00000040 fd b9 52 ff da 61 20 20 14 6a 31 1d e8 1c b0 7f |..R..a .j1.....| 00000050 92 cc 48 0c 38 59 16 49 6d 71 11 39 00 00 1e 10 |..H.8Y.Imq.9....| 00000060 4c fc 18 00 00 00 00 00 00 00 0f 68 67 e0 be 11 |L..........hg...| 00000070 17 88 d5 2b 13 c4 5b 33 a2 98 f7 b9 6e 2d dc 62 |...+..[3....n-.b| 00000080 ba 5e 8f 50 bf 09 f9 28 13 38 29 2a de 47 f4 c1 |.^.P...(.8)*.G..| 00000090 9c 3e d6 37 bc 8c ad 95 f0 b3 c1 97 bc fb 1f b5 |.>.7............|After 1998 Viking Husqvarna merged with the Pfaff brand and a new format with the extension .VIP was used. I found a couple variants of this format.
hexdump -C Magic Flower.vip | head 00000000 5d fc 90 01 0e 06 00 00 01 00 00 00 3e 01 19 01 |]...........>...| 00000010 c2 fe e7 fe 6e 00 00 00 80 00 00 00 c8 04 00 00 |....n...........| 00000020 00 00 00 00 00 00 00 00 00 00 36 00 00 00 89 bf |..........6.....| 00000030 93 fc 01 00 00 00 1a 00 00 00 46 00 6c 00 6f 00 |..........F.l.o.| 00000040 72 00 61 00 6c 00 3b 00 20 00 41 00 62 00 73 00 |r.a.l.;. .A.b.s.| 00000050 74 00 72 00 61 00 63 00 74 00 3b 00 20 00 46 00 |t.r.a.c.t.;. .F.| 00000060 61 00 73 00 68 00 69 00 6f 00 6e 00 00 00 00 0b |a.s.h.i.o.n.....| 00000070 38 68 61 2f f8 6c 9d 68 63 47 07 80 09 c0 6b e0 |8ha/.l.hcG....k.| 00000080 04 9f 6d eb 70 c5 4b 3f e0 00 7d 52 4a 45 66 6f |..m.p.K?..}RJEfo| 00000090 bf 1e f5 41 be f6 50 44 90 02 21 fd 6f 39 bd 71 |...A..PD..!.o9.q|The three HUS files and the VIP files have a similar first 4 bytes. Should make an easy signature.
With the addition of the TruE mySewnet service and software, the format went through a change and started using the .VP3 extension.
hexdump -C Magic Flower.vp3 | head 00000000 25 76 73 6d 25 00 00 38 00 50 00 72 00 6f 00 64 |%vsm%..8.P.r.o.d| 00000010 00 75 00 63 00 65 00 64 00 20 00 62 00 79 00 20 |.u.c.e.d. .b.y. | 00000020 00 56 00 53 00 4d 00 20 00 53 00 6f 00 66 00 74 |.V.S.M. .S.o.f.t| 00000030 00 77 00 61 00 72 00 65 00 20 00 4c 00 74 00 64 |.w.a.r.e. .L.t.d| 00000040 00 02 00 00 00 0d 64 00 32 00 46 00 6c 00 6f 00 |......d.2.F.l.o.| 00000050 72 00 61 00 6c 00 3b 00 20 00 41 00 62 00 73 00 |r.a.l.;. .A.b.s.| 00000060 74 00 72 00 61 00 63 00 74 00 3b 00 20 00 46 00 |t.r.a.c.t.;. .F.| 00000070 61 00 73 00 68 00 69 00 6f 00 6e 00 00 7c 38 00 |a.s.h.i.o.n..|8.| 00000080 00 6d c4 ff ff 83 c8 ff ff 92 3c 00 00 06 0e 00 |.m........<.....| 00000090 01 0c 00 01 00 03 00 00 00 0d 10 00 00 00 00 00 |................|The current version of the Premier+ software produces a file with the extension .VP4.
hexdump -C Magic Flower.vp4 | head 00000000 25 56 70 34 25 01 00 00 00 4d 73 61 0a df 74 29 |%Vp4%....Msa..t)| 00000010 3c 87 6b 44 2c 84 2f 00 3c 7c f7 e7 a0 69 6e 66 |<.kD,./.<|...inf| 00000020 6f 00 00 00 00 45 00 00 00 6e 74 74 6e 00 00 00 |o....E...nttn...| 00000030 00 27 00 00 00 02 00 6e 74 65 73 19 00 46 6c 6f |.'.....ntes..Flo| 00000040 72 61 6c 3b 20 41 62 73 74 72 61 63 74 3b 20 46 |ral; Abstract; F| 00000050 61 73 68 69 6f 6e 73 74 67 73 00 00 0c 06 00 00 |ashionstgs......| 00000060 01 00 00 00 01 00 c2 fe e7 fe 3e 01 19 01 00 00 |..........>.....| 00000070 73 62 64 73 00 00 00 00 ab 0c 00 00 01 00 73 62 |sbds..........sb| 00000080 64 6e 00 00 00 00 9d 0c 00 00 00 00 00 00 00 00 |dn..............| 00000090 00 00 00 00 00 00 00 00 00 00 00 6e 74 74 6e 00 |...........nttn.|There is a great python library which can read in many of these formats and can give us some confirmation of the format headers. It is called pyembroidery and has readers for HUS and VP3.
One other format associated with the Husqvarna Viking Designer 1 model which used a floppy disk is the SHV stitch file. This is a special format which could only be used on the embroidery machine if it was properly formatted. This would put into a structure that would look like this:

The SHV file is the design file with the MHV and PHV are used for display on the embroidery machine. This is what we find when we look at the SHV content:
hexdump -C My Designs/MENU_01/DES01_01.SHV | head 00000000 45 6d 62 72 6f 69 64 65 72 79 20 64 69 73 6b 20 |Embroidery disk | 00000010 63 72 65 61 74 65 64 20 75 73 69 6e 67 20 73 6f |created using so| 00000020 66 74 77 61 72 65 20 6c 69 63 65 6e 73 65 64 20 |ftware licensed | 00000030 66 72 6f 6d 20 56 69 6b 69 6e 67 20 53 65 77 69 |from Viking Sewi| 00000040 6e 67 20 4d 61 63 68 69 6e 65 73 20 41 42 2c 20 |ng Machines AB, | 00000050 53 77 65 64 65 6e 08 55 6e 74 69 74 6c 65 64 8f |Sweden.Untitled.| 00000060 a0 47 50 62 7c 00 00 00 00 00 00 00 00 00 00 00 |.GPb|...........| 00000070 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 000000a0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 09 99 |................|The MHV and PHV files have the same header so identification of just the SHV design file will be difficult.
I have only scratched the surface with these embroidery formats. The embroidery market was quite large with many different manufacturers. The user base seems to have been quite large, but its reach may be limited to personal collections. I have attempted a signature for the Husqvarna formats, you can find them in my GitHub repository. More to come hopefully!
RCA-VOC
I wonder sometimes what goes through a software/hardware developers mind when deciding a format to use for a new device. There are so many options our there for audio formats to choose from. I am sure there are pros and cons to using one technology over another but it seems a few decide to go ahead and make their own. I am sure there is some commercial advantage to developing a proprietary audio format, but with all the established choices it seems unnecessary.
Sony developed their own audio compression formats, which I explored in an earlier blog post. I came across a small goofy looking RCA voice recorder, model VR6320.

Many of these RCA VR series recorders can record in a WAV or a VOC file format. The WAV files are pretty run of the mill, but the VOC format is unique to RCA recorders.
The VOC format is not to be confused with another audio format with the same extension. The Creative Voice Format is a bit more well known. It was used with the Creative’s sound cards (Sound Blaster family) many folks had in their Windows computers in the 1990’s. But the RCA file format is different, and because of the same extension needs its own identification so they are not confused with each other.
sf REC00001.VOC --- siegfried : 1.10.1 scandate : 2023-11-19T23:33:47-07:00 signature : default.sig created : 2023-05-12T09:10:13Z identifiers : - name : 'pronom' details : 'DROID_SignatureFile_V112.xml; container-signature-20230510.xml' --- filename : 'REC00001.VOC' filesize : 47231 modified : 2015-01-09T20:51:10-07:00 errors : matches : - ns : 'pronom' id : 'UNKNOWN' format : version : mime : class : basis : warning : 'no match; possibilities based on extension are fmt/1736'The RCA VOC file format seems to be undocumented, there isn’t much available. You can always download a copy of the RCA Digital Voice Manager software, which may or may not run on your current system, and convert the VOC files to WAV or you can use a piece of software coded in 2008 called “devoc“. The developer used to have an online website you could upload the VOC to and it would convert it automatically, but is not longer available. The code can also be found here.
Let’s take a look at the header of a couple of the files I have:
hexdump -C REC00001.VOC | head 00000000 56 43 50 31 36 32 5f 56 4f 43 5f 46 69 6c 65 0c |VCP162_VOC_File.| 00000010 0f 01 09 14 32 1c 00 00 0b 44 03 00 00 00 00 00 |....2....D......| 00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 000001b0 00 10 00 00 00 00 00 00 00 00 00 10 00 00 00 00 |................| 000001c0 00 00 00 00 00 10 00 00 00 00 00 00 00 00 00 10 |................| 000001d0 00 00 00 00 00 00 00 ff ff ff ff ff ff ff ff ff |................| 000001e0 ef 11 14 d3 96 77 57 44 34 33 34 44 43 33 44 43 |.....wWD434DC3DC| 000001f0 43 34 44 34 43 43 34 44 43 43 33 35 43 33 43 34 |C4D4CC4DCC35C3C4| 00000200 34 43 43 24 34 43 43 33 44 51 33 42 14 44 32 43 |4CC$4CC3DQ3B.D2C| hexdump -C A0000003.VOC | head 00000000 52 50 35 31 32 30 5f 56 4f 43 5f 46 69 6c 65 78 |RP5120_VOC_Filex| 00000010 08 06 16 0a 0f 20 00 04 17 01 03 00 00 00 00 00 |..... ..........| 00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 00000180 00 03 b9 2f 00 07 62 af 00 0b 0c 2f 00 0e b5 af |.../..b..../....| 00000190 00 12 5f 2f 00 00 00 00 00 00 00 00 00 00 00 00 |.._/............| 000001a0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 00000fa0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 e1 |................| 00000fb0 ea eb ea fe df ae 4e a1 1d cd 1c cf 9f de cf 3b |......N........;|Most of samples I have show “VCP162_VOC_File” in the header, but I have one sample with “RP5120_VOC_File“. I have heard of others, one being “V432_Voice_File“. There could be more variations. One could assume the header is somehow associated with the model number of the device, but that doesn’t appear to be the case. Although there is a device with the model number “RP 5120“. It might be that the older RP series get one header and the newer VR Series get VCP? I will need more samples to confirm, if you have any send them my way. Also, according to the manuals, there is a SP and LP mode to manage the bitrate of the file to squeeze more minutes on the built in memory of these devices. This doesn’t appear to affect identification, but might be good to differentiate in the future.
For now you can take a look at the signature on my GitHub page.
Adobe Acrobat Capture
During the recent PRONOM Research Week, I noticed a file format with no description and no signature.
x-fmt/217Adobe ACDAll I had to go on was it was an Adobe format and the acronym “ACD”. One of the first results that came up in a google search was a post in the Adobe forums with someone asking what to do with some old ACD and ACI files they found on a disc, circa 2000, labeled “Adobe Capture”. The only thing I remember about Adobe Capture was some scanning tools related to Adobe Acrobat, but I didn’t remember coming across any ACD files related to Acrobat.
Initially it wasn’t easy to find more information on this format. Eventually I was able to narrow it down to stand-alone software adobe released called “Adobe Acrobat Capture”. Originally released in 1995 it was eventually discontinued in 2010. The software was marketed under the ePaper name and connected to Acrobat through the creation of a PDF from scanned images. The software was compatible with many scanner models and would process the scanned images, run Optical Character recognition, and export to a searchable PDF. These tools are built into Adobe Acrobat today.
One of the reasons the software was being so elusive is the fact it was sold with a high price tag and required the use of a hardware key, or dongle, in order to process scans. The hardware key also managed the type of license you purchased which may limit the number of pages you are allowed to scan within a certain period of time. So the software is very difficult to run today, if you do happen to find a copy out there in Internet land.
In order to document these file formats for preservation purposes I needed to find some samples. I was excited to find a demonstration CD on the Internet Archive, but unfortunately it contained no examples of the ACD file format.
A little sleuthing on the Wayback Machine helped me find a few user guides and brochures. I was also able to find there was three versions of Adobe Acrobat Capture. In a Product Brochure, you can see a screenshot of the software with a document open with the ACD extension.

If you are OCD like me you might have noticed the window in this screenshot is typical of the older Windows 3.1 or Windows NT system. So this was indeed an older product released by Adobe.
The Adobe Acrobat Capture 3.0 Demonstration CD-ROM from the Internet Archive luckily has a UserGuide PDF on the disc and was able to help me understand the ACD format a little more.
Looks like the ACD format is an intermediate format used by the software to manage the process between scanning and export to PDF. ACD was also defined as an “Acrobat Capture Document” which makes sense. They were also mentioned as being “multipage files in Acrobat Capture Document (ACD)”. The UserGuide also mentioned an ACP format which it referenced as “one-page files are in Acrobat Capture Page (ACP) format.” So more research is needed.
Lets start with Adobe Acrobat Capture 2.0 as I managed to get a few samples from an installer I found. Here is a hexdump of an ACD file and its corresponding ACI file.
hexdump -C CONTRACT.ACD | head 00000000 02 04 47 47 c9 00 86 b5 01 00 b6 27 02 00 01 00 |..GG.......'....| 00000010 f5 00 5e 00 3b 96 02 00 01 6e 63 6a 00 00 88 68 |..^.;....ncj...h| 00000020 00 00 26 00 44 3a 5c 43 4f 44 45 5c 47 47 5c 50 |..&.D:\CODE\GG\P| 00000030 52 4f 44 55 43 54 2e 33 32 53 5c 49 4e 5c 63 6f |RODUCT.32S\IN\co| 00000040 6e 74 72 61 63 74 2e 61 63 69 00 00 00 00 00 00 |ntract.aci......| 00000050 7c 33 c0 27 00 40 ff ff ff 00 03 00 03 00 00 00 ||3.'.@..........| 00000060 00 00 00 00 00 00 40 00 00 00 00 00 00 03 00 00 |......@.........| 00000070 00 00 00 00 00 00 00 40 00 00 00 00 09 00 0a ab |.......@........| 00000080 04 0b 14 b5 04 39 19 00 40 00 00 00 00 0c 14 b0 |.....9..@.......| 00000090 04 38 19 b0 04 08 00 0a 7f 06 d3 11 89 06 39 17 |.8............9.| hexdump -C CONTRACT.ACI | head 00000000 49 49 2a 00 b3 0c 02 00 35 80 78 a0 80 35 c0 78 |II*.....5.x..5.x| 00000010 a4 80 35 40 3c 54 40 01 e2 b2 01 e2 b2 01 e2 b2 |..5@<T@.........| 00000020 01 e2 b2 01 e2 b2 01 e2 b2 01 e2 b2 01 e2 b2 01 |................| 00000030 e2 b2 01 e2 b2 01 e2 b2 01 e2 b2 01 e2 b2 01 e2 |................| 00000040 b2 01 e2 b2 01 e2 b2 01 e2 b2 01 e2 b2 01 e2 b2 |................| 00000050 01 e2 b2 01 e2 b2 01 e2 b2 01 e2 b2 01 e2 b2 01 |................| 00000060 e2 b2 01 e2 b2 01 e2 b2 01 e2 b2 01 e2 b2 01 e2 |................| 00000070 b2 01 e2 b2 01 e2 b2 01 e2 b2 01 e2 b2 01 e2 b2 |................| 00000080 01 e2 b2 01 e0 b0 01 e0 b0 01 e0 b0 01 e0 b0 01 |................| 00000090 e0 b0 01 e0 b0 01 e0 b0 01 e0 b0 01 e0 b0 01 e0 |................|The ACD file is unique, PRONOM and even TrID was unaware of the format. But to the keen observer, the ACI format is very recognizable. You may have seen this header before:

Lets take a closer look at an ACI file to see if they are a true TIFF image or if there is any customization to the format.
tiffinfo CONTRACT.ACI === TIFF directory 0 === TIFF Directory at offset 0x20cb3 (134323) Subfile Type: (0 = 0x0) Image Width: 2544 Image Length: 3295 Resolution: 300, 300 Bits/Sample: 1 Compression Scheme: CCITT RLE Photometric Interpretation: min-is-white Samples/Pixel: 1 Rows/Strip: 32 Planar Configuration: single image plane Software: HALO Desktop Imager exiftool -D CONTRACT.ACI - ExifTool Version Number : 12.60 - File Name : CONTRACT.ACI - Directory : TUTORIAL/SAMPOUT - File Size : 134 kB - File Modification Date/Time : 1995:07:10 16:02:08-06:00 - File Access Date/Time : 2023:11:14 15:41:02-07:00 - File Inode Change Date/Time : 2023:11:08 08:34:18-07:00 - File Permissions : -rwxrwxrwx - File Type : TIFF - File Type Extension : tif - MIME Type : image/tiff - Exif Byte Order : Little-endian (Intel, II) 254 Subfile Type : Full-resolution image 256 Image Width : 2544 257 Image Height : 3295 258 Bits Per Sample : 1 259 Compression : CCITT 1D 262 Photometric Interpretation : WhiteIsZero 273 Strip Offsets : (Binary data 625 bytes, use -b option to extract) 277 Samples Per Pixel : 1 278 Rows Per Strip : 32 279 Strip Byte Counts : (Binary data 448 bytes, use -b option to extract) 282 X Resolution : 300 283 Y Resolution : 300 305 Software : HALO Desktop Imager - Image Size : 2544x3295 - Megapixels : 8.4Looks like a true TIFF image with no special tags or unique properties. They are 1-bit TIFF’s compressed with CCITT RLE. Not sure there would be any need to create a special signature for these ACI files.
Looking closer at the ACD file format, we can see they reference ACI files, so probably safe to assume the ACD file doesn’t contain the full raster data for each image:
hexdump -C Report.acd 00000000 02 04 47 47 c9 00 9a 8b 00 00 d4 ce 00 00 03 00 |..GG............| 00000010 f5 02 5f 00 00 61 01 00 01 6e 63 6a 01 00 30 5f |.._..a...ncj..0_| 00000020 00 00 27 00 63 3a 5c 63 61 70 74 75 72 65 32 5c |..'.c:\capture2\| 00000030 73 61 6d 70 6c 65 73 5c 6f 75 74 5c 52 65 70 6f |samples\out\Repo| 00000040 72 74 5f 30 30 30 31 2e 61 63 69 00 00 01 00 00 |rt_0001.aci.....| 00000050 00 00 00 00 00 00 00 00 00 00 e8 03 00 00 01 00 |................| 00000060 01 00 00 00 00 00 00 00 00 00 08 00 52 65 70 6f |............Repo| 00000070 72 74 30 31 00 00 00 00 70 33 d8 27 00 40 ff ff |rt01....p3.'.@..| * 00005f40 07 00 40 6f 00 09 00 40 01 6e 63 6a 02 00 52 2c |..@o...@.ncj..R,| 00005f50 00 00 27 00 63 3a 5c 63 61 70 74 75 72 65 32 5c |..'.c:\capture2\| 00005f60 73 61 6d 70 6c 65 73 5c 6f 75 74 5c 52 65 70 6f |samples\out\Repo| 00005f70 72 74 5f 30 30 30 32 2e 61 63 69 00 00 00 00 00 |rt_0002.aci.....| 00005f80 00 00 00 00 4e 0c fe ff ff ff e8 03 00 00 01 00 |....N...........| 00005f90 01 00 00 00 00 00 00 00 00 00 08 00 52 65 70 6f |............Repo| 00005fa0 72 74 30 32 00 00 00 00 4c 31 f0 27 00 40 ff ff |rt02....L1.'.@..|From the limited sample set I have access, all the ACD files begin with the same Hex values, “02044747C900”. Along with the common header we can assume there should be at least one ACI file referenced in the first part of the file. Because it is referenced as a filepath, the ACI string would be variable in its offset.
Adobe Acrobat Capture 3.0 turns out to be a different format. But looks familiar………
hexdump -C Contract.acd | head 00000000 50 4b 03 04 14 00 00 00 08 00 3b ba 6e 57 23 9d |PK........;.nW#.| 00000010 8e b8 3d 00 00 00 3e 00 00 00 09 00 40 00 46 49 |..=...>.....@.FI| 00000020 4c 45 53 2e 4c 53 54 0a 00 20 00 00 00 00 00 00 |LES.LST.. ......| 00000030 00 00 00 80 e6 e9 ca 50 17 da 01 80 e6 e9 ca 50 |.......P.......P| 00000040 17 da 01 80 e6 e9 ca 50 17 da 01 4e 55 18 00 4e |.......P...NU..N| 00000050 55 43 58 09 00 46 00 49 00 4c 00 45 00 53 00 2e |UCX..F.I.L.E.S..| 00000060 00 4c 00 53 00 54 00 8b 76 74 76 31 8c e5 e5 f2 |.L.S.T..vtv1....| 00000070 0c 76 f6 f7 0d f0 0f f6 0c 71 b5 0d 09 0a 75 e5 |.v.......q....u.| 00000080 e5 f2 0b f5 75 f3 f4 71 0d b6 35 e4 e5 02 31 fc |....u..q..5...1.| 00000090 1c 7d 5d 0d 6d 9d f3 f3 4a 8a 12 93 4b f4 12 93 |.}].m...J...K...| sf Contract.acd --- siegfried : 1.10.1 scandate : 2023-11-15T09:10:01-07:00 signature : default.sig created : 2023-10-11T15:10:17-06:00 identifiers : - name : 'pronom' details : 'DROID_SignatureFile_V114.xml; container-signature-20230822.xml' --- filename : 'Contract.acd' filesize : 79002 modified : 2023-11-14T23:17:53-07:00 errors : matches : - ns : 'pronom' id : 'x-fmt/263' format : 'ZIP Format' version : mime : 'application/zip' basis : 'byte match at [[0 4] [78886 3] [78980 4]]' warning : 'extension mismatch'Yep, its a zip container file. lets take a peek inside to see what it is composed of.
7z l Contract.acd -- Path = Contract.acd Type = zip Physical Size = 79002 Date Time Attr Size Compressed Name ------------------- ----- ------------ ------------ ------------------------ 2023-11-14 23:17:54 ....A 62 61 FILES.LST 2023-11-14 23:17:54 ....A 410 226 Contract.acd 2023-11-14 23:17:52 ....A 150213 78093 Contract.acp ------------------- ----- ------------ ------------ ------------------------ 2023-11-14 23:17:54 150685 78380 3 filesThe the Contract ACD file is like a nesting doll, an ACD within an ACD. Lets see what the ACD and ACP is made of.
hexdump -C Contract.acd | head 00000000 00 01 00 00 00 02 04 47 47 2d 01 9a 01 00 00 02 |.......GG-......| 00000010 00 00 00 02 00 01 01 00 00 00 01 00 00 00 04 04 |................| 00000020 00 00 00 09 00 57 69 6e 67 64 69 6e 67 73 05 00 |.....Wingdings..| 00000030 41 72 69 61 6c 0b 00 43 6f 75 72 69 65 72 20 4e |Arial..Courier N| 00000040 65 77 0f 00 54 69 6d 65 73 20 4e 65 77 20 52 6f |ew..Times New Ro| 00000050 6d 61 6e 05 01 00 00 00 02 00 00 00 78 01 00 00 |man.........x...| 00000060 0f 00 54 69 6d 65 73 20 4e 65 77 20 52 6f 6d 61 |..Times New Roma| 00000070 6e 00 00 00 20 0b 00 00 c0 0a 00 00 00 00 00 00 |n... ...........| 00000080 00 06 00 00 00 0f 00 54 69 6d 65 73 20 4e 65 77 |.......Times New| 00000090 20 52 6f 6d 61 6e 00 00 00 20 0c 00 00 00 0c 00 | Roman... ......| hexdump -C Contract.acp | head 00000000 25 50 44 46 2d 31 2e 33 0d 25 e2 e3 cf d3 0d 0a |%PDF-1.3.%......| 00000010 31 20 30 20 6f 62 6a 0d 3c 3c 20 0d 2f 54 79 70 |1 0 obj.<< ./Typ| 00000020 65 20 2f 43 61 74 61 6c 6f 67 20 0d 2f 50 61 67 |e /Catalog ./Pag| 00000030 65 73 20 32 20 30 20 52 20 0d 2f 53 74 72 75 63 |es 2 0 R ./Struc| 00000040 74 54 72 65 65 52 6f 6f 74 20 34 20 30 20 52 20 |tTreeRoot 4 0 R | 00000050 0d 2f 43 41 50 54 5f 49 6e 66 6f 20 3c 3c 20 2f |./CAPT_Info << /| 00000060 56 20 33 30 31 20 2f 46 53 20 5b 20 28 57 69 6e |V 301 /FS [ (Win| 00000070 67 64 69 6e 67 73 29 28 41 72 69 61 6c 29 28 43 |gdings)(Arial)(C| 00000080 6f 75 72 69 65 72 20 4e 65 77 29 28 54 69 6d 65 |ourier New)(Time| 00000090 73 20 4e 65 77 20 52 6f 6d 61 6e 29 5d 20 2f 4c |s New Roman)] /L|The ACD has some of the same hex values as the previous version, but with some extra bytes at the beginning and it looks like the ACP is a straight up PDF. But may have some interesting tags, like “CAPT_info”.
The problem we will face when trying to write a signature for this version of ACD is the container signature needs a static file name to reference, and it appears the name of the container is also the name of the ACD file within the container. So every file will be different. I wish there was a way in the PRONOM signature syntax to reference an extension and ignore the filename, but currently there no method to do this. The only thing inside the container which seems to be consistent is the file “FILES.LST”. So lets take a peek inside if it.
hexdump -C FILES.LST | head 00000000 5b 41 43 44 31 5d 0d 0a 49 53 43 4f 4d 50 4f 53 |[ACD1]..ISCOMPOS| 00000010 49 54 45 3d 54 52 55 45 0d 0a 4e 55 4d 46 49 4c |ITE=TRUE..NUMFIL| 00000020 45 53 3d 31 0d 0a 46 49 4c 45 4e 41 4d 45 31 3d |ES=1..FILENAME1=| 00000030 43 6f 6e 74 72 61 63 74 2e 61 63 70 0d 0a |Contract.acp..|Ok, there seems to be some static information that is unique to the ACD format. I bet the string “[ACD1]” would be sufficient enough to make a solid signature.
This is a good format example of a limited amount of information on the file format used by a well known company which has become obsolete and disappeared. Take a look at my signatures, maybe you have some old ACD files you were unaware of!
Multiplan
This is a follow up post to the post “EARLY MICROSOFT EXCEL” earlier this year.

I have to admit, often when I am researching file formats I can get distracted by a shinier format I come across. I often go down rabbit holes and forget the reason I started down the path I am on. I try and focus on the current needs in my life as a Digital Preservation Manager, but can get easily sidetracked. I always look forward to November every year so I can celebrate World Digital Preservation Day which sometimes comes along with a PRONOM research week. This gives me a chance to look at formats that may need attention which are not normally on my radar.
This week I a taking a look again at Multiplan. There is a PRONOM PUID for version 4, but does not have a description nor does it have a binary signature. It is was also lacking a File Format Wiki entry. So I decided to dive in. I had already bumped into the format while doing some research on early Microsoft Excel formats. This includes the SYLK format which needed a little update.
Microsoft Multiplan was the parent of Microsoft Excel. Multiplan was built for many different types of computers in the 1980’s, but was never ported to Windows. So to use Multiplan you have to be comfortable with using DOS. If you want to take Multiplan for a spin, head over to PCjs Machines and load up one of the many emulated systems they have.
In the end, Multiplan had four versions, but the last one, version 4.2, had some big changes, especially to the file format. More on that in a minute.
Mutiplan Version 1 – DOS
hexdump -C MP1.MOD | head 00000000 08 e7 00 00 58 09 01 00 08 00 01 00 00 00 0a 00 |....X...........| 00000010 40 00 00 00 2e f5 0a 80 27 07 94 00 12 00 01 00 |@.......'.......| 00000020 0a 00 01 00 0c 0a 08 00 27 00 0d 80 04 00 01 00 |........'.......| 00000030 54 00 00 00 27 00 10 00 54 52 41 4e 53 46 48 f5 |T...'...TRANSFH.| 00000040 00 80 84 0a 68 61 52 f5 58 f5 5a f5 4e f5 0c 0a |....haR.X.Z.N...| 00000050 12 00 01 00 72 f5 72 f5 0a 80 4b 0b 0f 00 12 00 |....r.r...K.....| 00000060 0c 0a 01 00 0c 00 01 00 08 00 20 4e 40 00 09 00 |.......... N@...| 00000070 8a f5 0a 80 4a 07 30 00 48 00 01 00 20 4e 00 00 |....J.0.H... N..| 00000080 28 0c 18 00 04 00 0d 80 03 00 28 0c 04 00 00 00 |(.........(.....| 00000090 26 00 00 00 54 52 d0 01 00 00 a4 f5 0a 00 62 0b |&...TR........b.|Mutiplan Version 1 – Macintosh
hexdump -C Multiplan1 | head 00000000 11 ab 00 00 13 e8 00 00 00 00 00 00 00 02 02 8c |................| 00000010 00 18 00 0e 02 a4 02 b2 00 0e 02 fe 00 03 00 0e |................| 00000020 00 bd 01 e3 2f 0f 00 08 15 5e 19 d1 03 5e 19 dd |..../....^...^..| 00000030 61 60 60 5e 16 90 00 67 60 60 60 8f 5f 03 e8 7a |a``^...g```._..z| 00000040 30 61 60 60 13 5f 03 e8 7b 90 00 67 60 60 60 8f |0a``._..{..g```.| 00000050 16 85 67 60 60 60 8f 16 6d 85 61 60 60 13 5e 10 |..g```..m.a``.^.| 00000060 7b 90 00 67 60 60 60 8f 13 7a 31 14 6a d7 16 6e |{..g```..z1.j..n| 00000070 85 14 77 60 16 6f 85 67 60 60 60 90 00 67 60 60 |..w`.o.g```..g``| 00000080 60 90 00 67 60 60 60 8f 13 7a 31 14 6a d7 16 70 |`..g```..z1.j..p| 00000090 85 14 77 60 16 71 85 67 60 60 60 90 00 67 60 60 |..w`.q.g```..g``|Mutiplan Version 2 – DOS
hexdump -C MP2.MOD | head 00000000 0c ec 00 00 08 ab 08 00 1f 00 1a 00 03 00 27 03 |..............'.| 00000010 4b 05 00 00 00 00 00 00 00 00 00 1d c8 14 03 00 |K...............| 00000020 00 00 2f 00 9a 2e b3 fc 46 02 34 04 f3 16 00 00 |../.....F.4.....| 00000030 00 00 00 00 08 00 10 22 00 00 0d 06 84 1d 08 1d |......."........| 00000040 ff 03 83 0a c8 18 48 1a 02 19 00 00 00 00 15 1b |......H.........| 00000050 98 15 85 15 03 00 2a 00 00 37 46 32 1c 00 18 00 |......*..7F2....| 00000060 00 00 01 00 01 00 a9 03 0f 80 e8 14 00 00 01 00 |................| 00000070 6a 1c 00 00 01 00 0d 00 0f 80 0a 15 00 00 77 20 |j.............w | 00000080 00 00 01 00 6e 61 6c 20 00 00 2a 00 00 00 04 00 |....nal ..*.....| 00000090 00 00 0d 00 14 19 00 00 d4 06 0e 80 24 15 00 00 |............$...|The DOS files for Version 2 begin with 0CEC0000 08AB0800, but a file for the Xenix system starts with 0AEC0000 08AB0800. So it appears the first byte may be different depending on the system.
hexdump -C MP3.MOD | head 00000000 0c ed 00 00 08 ab 08 00 1f 00 1a 00 00 00 00 00 |................| 00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 00000110 00 00 02 00 01 00 00 00 00 00 ff 0f ff 00 00 00 |................| 00000120 00 00 05 00 06 00 46 00 36 00 42 00 00 00 00 00 |......F.6.B.....| 00000130 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 00000140 00 00 00 00 00 00 00 00 00 00 00 00 00 01 00 00 |................| 00000150 00 fe 0f 00 fe 00 00 00 00 00 00 00 00 00 00 00 |................| 00000160 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|The DOS files for Version 3 begin with a similar hex pattern, 0CED0000 08AB0800. This would make sense as the documentation for Multiplan 4.2 states it supports opening of Version 2 & 3, but not Version 1.

There was also a companion product that went along with Multiplan, it was called Microsoft Chart. Here is a file from version 3:
hexdump -C EXAMPLE1.MC | head 00000000 90 01 00 00 08 ab 00 00 00 00 00 00 00 00 04 00 |................| 00000010 80 00 05 00 04 00 43 10 00 00 00 00 00 00 00 00 |......C.........| 00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 00000080 e8 ff 04 00 00 22 24 36 a4 1f 00 00 11 00 24 00 |....."$6......$.| 00000090 03 00 64 00 00 00 cc 0c cc 0c cc 0c cc 0c 00 00 |..d.............| 000000a0 00 00 00 00 ff 7f 00 00 01 f0 00 00 00 5f 00 00 |............._..| 000000b0 00 00 a2 ff a0 ff 00 00 01 f0 01 00 64 00 00 00 |............d...| 000000c0 00 00 01 f0 00 00 01 70 00 00 8e ff 8c ff 00 ff |.......p........| 000000d0 0d 00 00 00 20 14 01 00 00 00 00 00 00 00 00 00 |.... ...........|The Chart file format has a similar byte pattern with the 08AB pattern and looks similar to the BIFF format. We will have to make sure it doesn’t conflict with any signatures so it can be identified separately.
Version 4 of Multiplan was the first to use the BIFF (Binary Interchange File Format). Technically Version BIFF2, not much is know about BIFF1 or if it ever existed. BIFF2 is the exact same format as Excel 2.0 used, so there will be some problems if we want to identify them separately. They currently identify as fmt/55.
hexdump -C MP4.MOD | head 00000000 09 00 04 00 40 01 10 00 42 00 02 00 b5 01 66 00 |....@...B.....f.| 00000010 1b 00 00 00 00 00 00 00 00 00 ff ff 0f 01 00 01 |................| 00000020 00 01 00 01 00 00 00 00 00 00 00 00 00 0d 00 02 |................| 00000030 00 01 00 0e 00 02 00 01 00 0f 00 02 00 00 00 11 |................| 00000040 00 02 00 00 00 2a 00 02 00 00 00 6b 00 13 00 01 |.....*.....k....| 00000050 00 00 00 00 00 fe 0f 00 fe 40 02 e0 3d d0 2f 00 |.........@..=./.| 00000060 01 00 26 00 08 00 00 00 00 00 00 00 e0 3f 27 00 |..&..........?'.| 00000070 08 00 00 00 00 00 00 00 e0 3f 28 00 08 00 00 00 |.........?(.....| 00000080 00 00 00 00 f0 3f 29 00 08 00 00 00 00 00 00 00 |.....?).........| 00000090 f0 3f 70 00 0b 00 00 00 2e 00 02 04 f0 0a 00 f0 |.?p.............| hexdump -C EXCEL2.XLS | head 00000000 09 00 04 00 02 00 10 00 0b 00 10 00 71 02 00 00 |............q...| 00000010 01 00 29 00 06 03 00 00 dc 0d 00 00 0c 00 02 00 |..).............| 00000020 64 00 0d 00 02 00 01 00 0e 00 02 00 01 00 0f 00 |d...............| 00000030 02 00 01 00 10 00 08 00 fc a9 f1 d2 4d 62 50 3f |............MbP?| 00000040 11 00 02 00 00 00 22 00 02 00 00 00 40 00 02 00 |......".....@...| 00000050 00 00 2a 00 02 00 00 00 2b 00 02 00 00 00 25 00 |..*.....+.....%.| 00000060 02 00 2c 01 31 00 09 00 c8 00 00 00 04 48 65 6c |..,.1........Hel| 00000070 76 32 00 0e 00 00 00 00 00 00 00 90 01 00 00 00 |v2..............| 00000080 00 00 8d 31 00 09 00 c8 00 01 00 04 48 65 6c 76 |...1........Helv| 00000090 32 00 0e 00 00 00 00 00 00 00 bc 02 00 00 00 00 |2...............|You can see in the hex values above a difference of two bytes in the header. The reason the Multiplan file identifies as an Excel 2 file is the PRONOM signature ignores those two bytes and allows them to be anything. Some specifications say these aren’t used, but clearly there is a use for them. We could probably use the same signature for Multiplan, but include the two bytes, then set the priority to the Multiplan signature.
Multiplan 4.2 is very different.
 hexdump -C MP42.MOD | head
00000000 0c ef 4d 50 a4 01 00 00 00 00 00 00 00 00 00 00 |..MP............|
00000010 00 00 00 00 00 00 80 02 00 00 00 00 00 00 00 2e |................|
00000020 ff 0f ff 00 01 00 d0 02 d0 02 a0 05 a0 05 d0 2f |.............../|
00000030 e0 3d 40 02 09 00 03 00 02 04 0a 00 00 00 fe 0f |.=@.............|
00000040 00 fe 00 00 01 00 01 00 00 00 00 00 00 00 00 00 |................|
00000050 00 00 00 00 00 00 00 00 01 00 00 00 06 01 15 50 |...............P|
00000060 05 00 00 00 00 00 00 00 06 00 13 00 07 00 07 00 |................|
00000070 00 00 00 00 00 00 08 00 00 00 00 00 00 00 00 00 |................|
00000080 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
hexdump -C MP42.MOD | head
00000000 0c ef 4d 50 a4 01 00 00 00 00 00 00 00 00 00 00 |..MP............|
00000010 00 00 00 00 00 00 80 02 00 00 00 00 00 00 00 2e |................|
00000020 ff 0f ff 00 01 00 d0 02 d0 02 a0 05 a0 05 d0 2f |.............../|
00000030 e0 3d 40 02 09 00 03 00 02 04 0a 00 00 00 fe 0f |.=@.............|
00000040 00 fe 00 00 01 00 01 00 00 00 00 00 00 00 00 00 |................|
00000050 00 00 00 00 00 00 00 00 01 00 00 00 06 01 15 50 |...............P|
00000060 05 00 00 00 00 00 00 00 06 00 13 00 07 00 07 00 |................|
00000070 00 00 00 00 00 00 08 00 00 00 00 00 00 00 00 00 |................|
00000080 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
The hex values for the first 4 bytes have a similar pattern. 0CEF, Which seems to be in sequence where Version 3 left off. Microsoft calls this new format, New or Normal Binary File Format. They claim it is “the fastest loading and fastest saving file format ever“! Exciting as the new format probably was, it didn’t last long. Multiplan was phased out so Excel could shine.
When I was younger I didn’t use DOS very often because the computer my father brought home in the mid 1980’s was a Macintosh. I use DOS more now in my research then I did when I was younger. Using the DOS interface is not easy. There are a lot of key commands you need to know intuitively just to navigate, but it is fascinating to see how far software has come. Early Excel, Multiplan, and Chart were all intertwined, but hopefully combing through all of these samples can bring some clarity. Take a look at the draft signature I made and all the samples that go with it on my GitHub page.
Composite File Management System
In honor of World Digital Preservation Day, I wanted to write a little about format headers, the magic that makes some files more easily identifiable than others.
When it comes to binary file formats, some developers decide to make the format clearly identifiable in a header and others choose to make it ambiguous. Others have a little fun with leaving little clues and references to popular culture.
A couple of my favorites based on their header.
- Early CoolEdit / Audition files began with the string “COOLNESS”.
- Medi8or format with string “MatchWare Medi8or Version 3.00”
- MacCaption with string “File Format=MacCaption_MCC V2.0”
- HyperWriter format with string “HyperWriter!”
- ExpressPublisher and AnFX Java Movie with hex values “CAFEBEEF”
- TIFF format which has at bytes 2-3 a “An arbitrary but carefully chosen number (42)“
A couple of my current least favorites:
- MP3 format, which can have no header just frames and which clash with everything.
- Canvas format which the early versions (CVS) have no standard header.
- Leica Cyclone PTS format with just point cloud data, no headers.
- Adobe Flash (FLA) later versions where the ZIP container is non standard and throws a Central Directory error.
Like I said some developers make it very obvious what software created the file format and others seem to make things difficult. I understand there is a need to optimize files to keep them from getting bloated and taking up too much space, but many of the size limits from the early days of computing are not an issue anymore. Can’t we be more clear when designing a file format?
Today I want to document one format which was very easy to identify as it spelled out its format very verbosely, but because of the lack of additional documentation makes it very hard to preserve.
Meet the Composite File Management System file format:
hexdump -C sample.br4 00000000 43 43 6d 46 20 2d 20 55 6e 69 76 65 72 73 61 6c |CCmF - Universal| 00000010 20 2d 20 41 78 69 6f 6d 20 2d 20 41 47 50 20 2d | - Axiom - AGP -| 00000020 20 43 6f 6d 70 6f 73 69 74 65 20 46 69 6c 65 20 | Composite File | 00000030 4d 61 6e 61 67 65 6d 65 6e 74 20 53 79 73 74 65 |Management Syste| 00000040 6d 20 28 55 6e 69 76 65 72 73 61 6c 29 20 2d 20 |m (Universal) - | 00000050 43 72 65 61 74 65 64 20 62 79 20 41 6e 64 72 65 |Created by Andre| 00000060 61 20 50 65 73 73 69 6e 6f 2c 20 44 65 63 65 6d |a Pessino, Decem| 00000070 62 65 72 20 31 39 39 35 20 28 76 65 72 73 2e 20 |ber 1995 (vers. | 00000080 35 29 20 2d 20 43 6f 70 79 72 69 67 68 74 28 63 |5) - Copyright(c| 00000090 29 20 31 39 39 35 2d 39 36 20 62 79 20 4d 65 74 |) 1995-96 by Met| 000000a0 61 54 6f 6f 6c 73 2c 20 49 6e 63 2e 20 2d 20 50 |aTools, Inc. - P| 000000b0 72 6f 75 64 6c 79 20 6d 61 64 65 20 69 6e 20 74 |roudly made in t| 000000c0 68 65 20 55 53 41 2c 20 6c 61 6e 64 20 6f 66 20 |he USA, land of | 000000d0 74 68 65 20 66 72 65 65 2c 20 68 6f 6d 65 20 6f |the free, home o| 000000e0 66 20 74 68 65 20 62 72 61 76 65 2e 00 00 00 00 |f the brave.....| 000000f0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|Where to start? First off, this is the Bryce 4 file format. Bryce was a 3D modeling, animation software developed by MetaTools, later MetaCreations. Metacreations was also the developer of popular software Ray Dream Studio/Infini D, Fractal Design Painter, and Kai’s Power Tools.
Secondly, this format refers to a Universal File Management System or CCmF, which I have found to be the file format for many other extensions, some of which are .goo, .brc, .br3, .br4, .br5, .sfp, .shp, .obp. It doesn’t always have the verbose header, some of them have the following:
hexdump -C Tutorial.obp | head 00000000 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 | | * 00000050 20 20 20 20 20 20 20 20 20 20 20 20 20 20 43 43 | CC| 00000060 6d 46 69 6c 65 3a 3a 6b 49 64 65 6e 74 69 66 79 |mFile::kIdentify| 00000070 34 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 |4 | 00000080 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 | |Different, but still contains the CCmF identification string. Others have the verbose header, but further down inside the file.
With this format being used with so many well known software titles, I assumed information on the format would we readily available. Alas, not so much. The format even had the name of the creator! “Created by Andrea Pessino, December 1995”. So I reached out. He was on Twitter and I asked about the file format and if there was any documentation available. Twitter (X) has since deleted his responses after he deleted his account, but he told me he wasn’t sure where the documentation might be. One other developer also commented and confirmed they didn’t know where any of the documentation went after they left.
MetaCreations sold Bryce to Corel in 2000, then in 2004 sold it to Daz3D, the current owners. It’s not actively developed anymore being that it was never made into a 64bit application. A blog post explains the format a little more, but concludes it is a secret known only to Daz.
It seems there is a community who would like to see Bryce more open, maybe even open-sourced. This thread discusses the format and the underlying Axiom format used.
The creator Andrea Pessino was able to track down some documentation on the CCmF file structure for me. He explained Axiom was an entire codebase for all MetaTools/Creations applications and plugins. So the CCmF system was more than a file format. The documentation included some information on versioning of a CCmF.
There seems to be a few versions of the CCmF file structure.
- CCmFile::kIdentify which corresponds with December 1995 (vers. 5)
- CCmFile::kIdentify2 which corresponds with March 1997 (vers. 7)
- CCmFile::kIdentify3 which corresponds with October 1998 (vers. 9)
- CCmFile::kDfFormat which is a Generic Composite File
The documentation given to me was up to date for 1998, but after Corel purchased Bryce there was some updates made as many material files have the identifier “CCmFile::kIdentify4“.
Bryce 6 & 7 were released by Daz3D and have a different file header. They have the extension .BR6 & .BR7 with the header:
hexdump -C Bryce7-s01.br7 | head 00000000 42 72 79 63 65 5f 36 2e 30 5f 46 69 6c 65 00 00 |Bryce_6.0_File..| 00000010 11 00 00 00 d4 07 00 00 00 20 00 00 e5 07 00 00 |......... ......| 00000020 00 0a 00 00 00 10 00 00 00 08 78 9c 63 64 60 60 |..........x.cd``| 00000030 60 04 e2 8c cc f4 0c 85 e4 9c fc d2 14 85 92 d4 |`...............| 00000040 8a 92 d2 a2 54 86 11 05 18 a1 18 04 82 76 c8 b5 |....T........v..| 00000050 be 0e 7c 60 8f 4e 93 67 f2 07 32 f5 d1 0e 30 31 |..|`.N.g..2...01| 00000060 40 fc ca 0c c5 60 bf 33 a2 ab da e2 8c c0 70 e0 |@....`.3......p.| 00000070 00 22 58 a0 9c ff 2a 40 fc bf 16 88 ff c3 c3 2e |."X...*@........| 00000080 13 64 20 83 82 13 50 29 50 ad 17 50 ef 3c 20 ce |.d ...P)P..P.< .| 00000090 72 66 64 86 19 31 cd 09 42 57 b9 80 71 43 9d 0b |rfd..1..BW..qC..|I still need to gather more samples from the various extensions related to this format and the software related to them. More work to do understanding the different uses of the short CCmFile string and the more detailed header and the differences between objects, materials, and models. When I asked Andrea why he used such a verbose file header, his answer was basically, why not!
Apple Mail
There really is no “Macintosh Format”, but there sure are a lot of formats you only find on the MacOS. From Resource Forks and iWork formats to unique sound formats, MacOS has them all! Majority of cross-platform software vendors have done a much better job in recent years in making their file formats the same across platforms, but for Apple, they love to make things unique, just for their platform.
Take EMLX for example. Seems to be a trend to add “X” to the end of an older format to breath new life into it. The EML format, or Electronic Mail, has existed for a few decades now, but in 2005 Apple updated their Apple Mail application to use a new format, EMLX.

As far as I know, Apple hasn’t released any documentation on the EMLX format, but many folks out there have asked the question and have been able to “reverse engineer” the format. Lets take a look.
An EMLX file consists of three parts:
- bytecount on first line;
- email content in MIME format (headers, body, attachments);
- Apple property list (plist) with metadata.
The bytecount is a variable number which consists of the total bytes starting from the start of the MIME format, including HTML, to the start of the XML property list. Lets look at a simple EMLX.
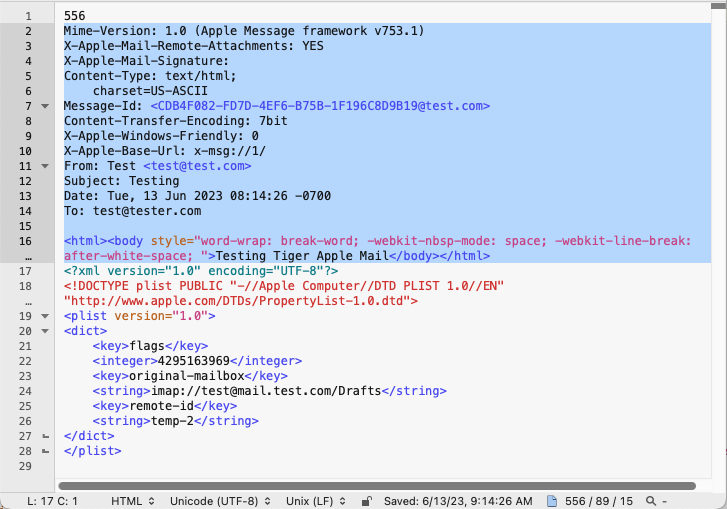
The byte count is on line 1 with the MIME email (EML) taking up the 556 bytes, then the XML plist at the end. You may ask, what is a plist? Well, it is another Apple (originally NextStep) invention which is embedded throughout the MacOS operating system. A Plist is usually an XML with keys but can also be in a binary format. The Plist can contain properties of the email within Apple Mail like special color flags, tagged as junk, date received and last reviewed.
If you do happen across an EMLX file or group of them, there are a few tools you can use to convert them to a plain old EML. There are python libraries or many other tools to do the job.
But first we need to be sure of identification beyond the extension. Adding this file format to PRONOM would help in identification for preservation purposes. If ran through PRONOM today we get:
filename : '9.emlx' filesize : 18582 modified : 2023-10-26T22:16:25-06:00 errors : matches : - ns : 'pronom' id : 'fmt/950' format : 'MIME Email' version : '1.0' mime : 'message/rfc822' class : 'Text (Structured)' basis : 'byte match at [[31 17] [599 4] [339 6] [426 6] [90 14]]' warning : 'extension mismatch'Because the format has a EML plain text format within its structure, it is assumed to be an EML file. While technically accurate, Identifying as a unique EMLX format would be beneficial in a preservation system so you can properly assign risk and choose the right tool to parse or migrate.
In looking at the three parts of an EMLX format, we know the EML file is not a good way to show the difference as they are the same structure. The byte count on the first line is variable, so there is no static byte sequence to use for identification. That leaves the Plist section at the end to distinguish the difference.
The PRONOM entry for a Plist looks for the typical XML strings present in most XML files, but then uses the root element “<plist version=”1.0″>” for identification. We could combine the existing EML signature and the Plist signature to identify an EMLX, or just take the existing EML signature and put in a small byte sequence for the closing of the </plist> tag near the EOF? There would be a need for a priority over EML, both would essentially accomplish the same thing.
Take a look at latter idea on my GitHub page and tell me which makes the most sense.
Common Ground
If digital preservation had an extension it most likely would be .DP
Unfortunately, it’s taken. Say hello to Digital Paper.
In the early 1990’s, folks started to share documents with each other through the their phone lines. The early internet, BBS, AOL, CompuServe and the like allowed people to share ideas through applications like Word/WordPerfect Documents. Most people had a copy of the popular software and that software could open documents from their competitors, but fonts were always a problem. Technically a font is software as well and needs a license to be used. Also printers at the time dictated what the document might look like when opened, so your document may look different on someone else’s computer. This lead to a few innovations in the software market Digital Paper.
The idea is simple, create a format which could be opened with a free viewer which includes all the parts to make it look and print just like it was intended to. You may have already guessed who the winner in this space tuned out to be, yes, the PDF format. You can’t tell the history of the PDF Format without mentioning others that tried their luck to be the leader in portable document formats . WordPerfect’s Envoy format was one, Common Ground Digital Paper was another.

No Hands Software which started in 1990, developed the idea of making your documents truly portable. They released the Common Ground Maker and Viewer software in 1993. By 1996 the company was doing so well they were bought for $6 million by Hummingbird Ltd. PDF soon became so ubiquitous, formats like Common Ground and Envoy fizzled out. That doesn’t mean they didn’t have a big impact and still can be found in quite a few places.
Apple was one of the bigger users for awhile, but the format can still be found floating around today.
The Common Ground Digital Paper has some similarities to the PDF format, but the biggest different is the format is proprietary and not open like PDF. Another difference is you could embed the viewer into the file, this would make an executable on both Windows and Macintosh. Very convenient for sending to those who may not have the viewer or can’t install the viewer on their system.

Common Ground had two different viewers, a pro viewer with more features and a Mini Viewer with basic features and which was free to download and distribute from their website. Unfortunately, they linked to an FTP site which no longer is available and so finding the viewers today can be difficult.

I came across a boxed version 1 for Macintosh of the software a few years back, but have yet to find other full versions. The software did change hands a bit, but seems to have topped out at Version 4 in the late 1990’s. Let’s take a look at the file format for the samples we do have.

Version 1 for the Macintosh was the first I believe, coming to Windows shortly afterwards. The format was even assigned a MimeType for use on the web and the application gives us a little insight into the format.
The commonground file format does have versions (two at the moment). They *are* internally documented with a file signature, allowing commonground viewers to automatically handle both old and new format files. Therefore, I don’t believe a ‘version’ parameter is needed.
A Content-Type of “application/commonground” indicates a document in the Common Ground portable file format, also known as Digital Paper.
Encoding considerations: Common Ground files are in a binary format. Some encoding will be necessary for MIME mailers as in application/octet-stream. Common Ground files for the Macintosh are encoded in the data fork of a Macintosh file. The file type is APPL, the creator is CGVM.
If we look at a sample from Version 1 for the Macintosh we find the follow hex values:
hexdump -C CG-s01.dp | head 00000000 00 00 03 56 00 00 04 d9 43 47 44 43 00 00 00 00 |...V....CGDC....| 00000010 96 6c 00 07 04 b4 03 de 00 00 00 00 02 da 02 28 |.l.............(| 00000020 00 11 02 ff 0c 00 ff ff ff ff 00 00 00 00 00 00 |................| 00000030 00 00 02 28 00 00 02 da 00 00 00 00 00 00 00 01 |...(............| 00000040 00 0a 00 05 00 05 00 15 02 23 00 32 00 05 80 02 |.........#.2....| 00000050 00 15 7f fe 00 2c 00 09 00 03 06 47 65 6e 65 76 |.....,.....Genev| 00000060 61 00 00 03 00 03 00 0d 00 0c 00 2e 00 04 00 00 |a...............| 00000070 00 00 00 2b 06 11 07 54 65 73 74 69 6e 67 00 01 |...+...Testing..| 00000080 00 0a ff e1 ff e2 02 f9 02 46 00 03 00 00 00 0d |.........F......| 00000090 00 00 00 28 02 d5 01 05 05 2d 20 31 20 2d 00 ff |...(.....- 1 -..|In all the samples I have the first 8 bytes are not consistent, but the next four bytes are. CGDC, which happens to be the registered type on the Macintosh. Convenient. But it appears later versions are not the same.
hexdump -C MANUAL.DP | head 00000000 00 00 00 20 00 00 b7 f4 44 50 4c 33 00 00 00 04 |... ....DPL3....| 00000010 00 00 00 00 00 00 00 00 3b 60 53 df 00 00 00 00 |........;`S.....| 00000020 00 00 00 18 00 00 b4 da 00 00 b4 c2 00 00 03 3e |...............>| 00000030 78 00 79 00 7a 00 7b 00 00 00 00 77 01 01 00 0c |x.y.z.{....w....| 00000040 00 01 02 01 00 00 00 97 fe ed f0 05 00 b7 86 04 |................| 00000050 5f 05 f7 01 00 03 ed f0 02 00 3d 00 ff 45 75 72 |_.........=..Eur| 00000060 6c 20 00 01 07 ff bf 05 9f 00 01 08 a3 05 fb ba |l ..............| 00000070 02 fa f1 00 ff ff 00 11 ff 68 74 74 70 3a 2f 2f |.........http://| 00000080 77 ff 77 77 2e 47 53 50 2e 43 b9 43 1c 0f 03 04 |w.ww.GSP.C.C....| 00000090 95 05 c8 0d 00 cc fb 05 e3 13 06 15 6d 61 69 6c |............mail| hexdump -C dpwhite.dp | head 00000000 00 00 00 18 00 01 79 17 44 50 4c 32 00 00 00 00 |......y.DPL2....| 00000010 00 00 00 00 00 00 00 00 00 00 00 18 00 01 76 de |..............v.| 00000020 00 01 76 c6 00 00 04 b2 00 00 00 00 00 00 00 00 |..v.............| 00000030 00 00 00 1e 01 01 00 0c 00 00 01 01 00 00 00 12 |................| 00000040 00 01 00 01 00 00 00 00 0c 4e 09 60 01 2c 01 2c |.........N.`.,.,| 00000050 00 64 00 00 00 02 00 00 00 00 00 a2 01 01 00 0c |.d..............| 00000060 00 01 02 01 00 00 00 e2 fa ed f0 22 ed f1 0c 4e |..........."...N| 00000070 09 60 00 ff e1 01 26 0a 83 08 3b ff ff 6a ff 6a |.`....&...;..j.j| 00000080 0c e4 09 f6 01 ff 2c 01 2c 00 08 00 64 00 df 00 |......,.,...d...| 00000090 01 01 00 03 ed f0 0f 00 79 0a 1c 0f 28 07 42 41 |........y...(.BA|These files are from a later version and have a different string at byte 8. DPL2 & DPL3. In the MiniViewer you can request document information and it provides some basic metadata for each file.

I only have one example of the DPL3, but a couple examples of DPL2, and it seems like DPL2 comes from a Version 3 DP Maker and DPL3 comes from Version 4 Maker. Need to see if I can find a Version 2 file and see if it follows the same pattern.
Two of my favorite CD-ROM’s on Internet Archive are Dr. Dobb’s The Essential Books on File Formats and Internet File Formats, both have copies of the Mini Viewer.
One of features similar to PDF is the ability to password protect certain features. This is what the document information looks like.

The header is the same, but the plain text usually seen in the file is no longer visible, so it appears the rest of the file is encrypted.
hexdump -C password.dp | head 00000000 00 00 5d 95 00 00 06 94 43 47 44 43 00 00 00 01 |..].....CGDC....| 00000010 8e 3b 18 7e c5 16 f8 e0 0f f5 6f 32 2f 34 36 81 |.;.~......o2/46.| 00000020 4b 8a 03 da 9e 1a 85 6c 36 e4 39 f2 5a 2a a2 5f |K......l6.9.Z*._| 00000030 81 83 65 ee 9c 16 d0 2d 2d c3 04 df 69 c8 06 0d |..e....--...i...| 00000040 77 df 27 19 33 59 f6 05 61 4e 2c a6 58 27 47 26 |w.'.3Y..aN,.X'G&| 00000050 fe 6b 3c 06 7e cb 7f fb 33 f8 64 ed 05 54 b4 7d |.k<.~...3.d..T.}| 00000060 c7 b5 e3 c2 df 40 53 63 ef 8e 10 1c c7 58 bd 28 |.....@Sc.....X.(| 00000070 9b 8a 2c 8f ae 82 33 f7 ff d4 3c 96 5c b4 08 69 |..,...3...<.\..i| 00000080 1f 00 af ce a7 56 93 27 07 cc 39 97 17 22 49 d7 |.....V.'..9.."I.| 00000090 5b 89 9b e6 b7 b1 5c 38 75 ba 08 ee 66 d0 9a d2 |[.....\8u...f...|This file format is not currently in PRONOM. From what I have gathered I could add three signatures. There could be some other variations out there and the password protection needs to be considered. Maybe I’ll take Nick Gault’s offer and request the format which was available starting in the middle of 1995. Think they’ll deliver?
No bad deed….
I had access to my first Macintosh computer around 1987. My father brought it home and I spent hours on it playing games and occasionally writing reports for school. The Macintosh Plus computer had one floppy drive and no hard drive. I remember playing the game Orbiter which had two floppy disks and right in the middle of game play it would pause and ask me to insert disk 2, then quickly ask for disk 1 again. The struggle was real. I spent years using many different Macintosh computers and now own more than I wish to admit. I’m preserving them!
The wild world of digital preservation has been a little lacking on the Macintosh side of things as I have come to realize. There still not a great way to manage Resource Forks in many preservation systems and the identification tools are mainly focused on the data bytetreams and not any system specific attributes Macintosh used often.
The PRONOM registry has either referenced early Macintosh specific formats or missed them entirely so I have been slowly working on a few to close that gap.
Interestingly enough, many Microsoft programs initially made their GUI debuts on the early Macintosh before making their way to Windows. Excel is one I am working on, as Version 1 is not identifiable in PRONOM, it was Macintosh only at the time.
Another is PowerPoint, I recently submitted two new signatures to PRONOM.
fmt/1747: Microsoft PowerPoint Presentation v2.x. Full entry added. fmt/1748: Microsoft PowerPoint Presentation v3.x. Full entry added. fmt/1866: Microsoft Powerpoint for Macintosh v.2. Full entry added. fmt/1867: Microsoft Powerpoint for Macintosh v.3. Full entry added.PowerPoint was initially released in 1987 on the Macintosh platform. It was developed by a company called ForeThought. Version 1.0 on the Macintosh was under this name, until it was bought by Microsoft only three months after being released. The history of PowerPoint can be discovered at Robert Gaskins, one of the original developers, website and book he wrote. The available information provided by Microsoft is only for the OLE format, covering versions 4.0 until 2003.
So, lets take a look at the Powerpoint original file format, before OLE.
 Type/Creator RF DF Date Filename
f SLDS/PPNT 0 932 Oct 10 19:10 PowerPoint-v1
Type/Creator RF DF Date Filename
f SLDS/PPNT 0 932 Oct 10 19:10 PowerPoint-v1
Luckily the early PowerPoint files did not have a Resource Fork. The Data Fork, if you haven’t noticed, has an interesting set of hex values at the beginning of the file. 0BADDEED is the first 4 bytes. If we look at a PowerPoint version 2 file from Windows.

The file format is the same, but because of the weird world of endianness, the first few bytes are in reverse order, EDDEAD0B.
Obviously we need to discuss this magic number and the meaning behind “Bad Deed”. This question was asked previously by the digital preservation community. I have a previous blog post about the use of words for the magic number CAFEBEEF as it was used with with JAVA class files and Express Publisher in the 1990’s. BADDEED looks like another clever use of the hex values that formed words. But was there a story behind the words? Joe Carrano asked if this string might be hexspeak. I wanted to know more so I asked some one who might know.
Robert Gaskins was kind enough to chat with me for a bit about the early days of PowerPoint.
I had a theory on the possible meaning behind BADDEED, so I asked him what the feeling was like between Apple and Microsoft at the time. I had heard for years that PowerPoint was originally created for the Macintosh, but Robert informed me:
In fact, PowerPoint was designed first for Microsoft Windows,
and its first spec shows that: “All the screen shots, menus, and
dialogs were set up to look like Microsoft Windows, not like
Macintosh.” (Gaskins, Sweating Bullets, p. 92) You can see that
spec here.
A year later, we concluded that we would be forced to ship
on Mac first, although we still thought that Windows was the
big opportunity and thought that Mac was risky. “We just didn’t think
we could successfully ship a product for Windows, yet, though we planned
to later. (Gaskins, Sweating Bullets, p. 105) The considerations are
summarized in my June 1986 product marketing document.
Of course, we turned out to have been right all along. PowerPoint on
Mac was much loved, but sales remained poor because Mac sales were
so poor. It was only after we shipped on Windows that PowerPoint gained
the dominant market share which has characterized it ever since, and
Windows PPT outsold Mac PPT very quickly. (Gaskins, Sweating Bullets, p. 403)
So my original thought was that there was some bad feelings around this Apple, Microsoft battle which has been the sentiment for quite some time. So when I asked if any of that influenced the use of BADDEED, I was told:
So, far from being disgruntled by expanding PowerPoint to Windows,
that had been our goal all along, and its achievement was the most
important success we had.
I judge that you are fully aware of all that, and that
your question is more, “was there any bad deed signified
by the Mac hex value chosen?” No, it was just the poverty
of choice when you only have six letters.
So there you have it. The use of the hex values 0x0BADDEED, was simply chosen from a limited set of values when looking at words hexadecimal could spell. I guess I should never let the truth get in the way of a good story.
I continued to have a wonderful conversation with Robert and also asked him for some details on the rest of the PowerPoint file format. I was hoping there might be some documentation out there explaining the early format before Microsoft took over. Robert said:
I don’t know of any such documentation apart from the official
Microsoft support files available online. I don’t have any such
information. I know that Dennis Austin deposited some of our
working files at the Computer History Museum (not online):
and it’s likely that some information is there–if nothing
else, it claims to contain a source code listing for PPT 1.0
which would contain the code to read the file format.
So there might be some information in at the Computer History Museum worth looking into.
As far as I could tell from the available online information, there is a few differences between Version 1.0 and Version 2.0, the biggest being the fact that 1.0 did not have an option to print in color, amount a few other minor things. Here is a screenshot of a page from the Microsoft PowerPoint 2.0 documentation on archive.org.

I suppose with the signature additions of the Macintosh and Windows versions 2.0 and 3.0 of the PowerPoint file format in PRONOM, that should cover most needs. Currently my PowerPoint 1.0 files identify at 2.0 files, so I may need to have them adjust the PUID to include both versions 1.0 and 2.0 as they are so similar. If I am able to find a difference or get my hands on the original source code I may find a better solution.
Quicktime MooV
During the 1990’s Apple Quicktime became the dominant digital media standard. It is the basis for the MPEG-4 format which is used everywhere now. Technically the Quicktime Movie format is a container or wrapper which can hold a variety of Video and Audio streams.
The basic unit of a Quicktime Movie is an atom. The MooV atom is the most important piece of a Quicktime Movie. Without it and the “mvhd” header atom, all the characteristics of the movie are lost.

Having the MooV atom missing from your movie file seems like it would be a rare thing, but it may happen more often than you think.
What happens when you come across a Quicktime file on an HFS disk, like one of these: https://archive.org/details/quick-clips-cd
If you try and open the movie you might see this.

MediaInfo doesn’t know what to make of the file. You can see the hex values from the beginning of the file, there clearly is no MooV atom.

Enter Macintosh Resource Forks.
Original Quicktime files stored the MOOV atom in a resource fork.

Lets take a look a closer look at one of these files.
 derez Wildebeest
data 'moov' (128) {
$"0000 0465 6D6F 6F76 0000 006C 6D76 6864" /* ...emoov...lmvhd */
$"0000 0000 E143 7EF5 E143 7EF5 0000 0258" /* ....?C~??C~?...X */
$"0000 1068 0001 0000 00FF 0000 0000 0000" /* ...h.....?...... */
$"0000 0000 0001 0000 0000 0000 0000 0000" /* ................ */
$"0000 0000 0001 0000 0000 0000 0000 0000" /* ................ */
$"0000 0000 4000 0000 0000 0000 0000 0000" /* ....@........... */
$"0000 0924 0000 0000 0000 0000 0000 0000" /* ...$............ */
$"0000 0002 0000 03D9 7472 616B 0000 005C" /* .......?trak...\ */
$"746B 6864 0000 000F A5EA 1D89 E143 7EF5" /* tkhd....??.??C~? */
$"0000 0001 0000 0000 0000 1068 0000 0000" /* ...........h.... */
$"0000 0000 0000 0000 0000 0000 0001 0000" /* ................ */
$"0000 0000 0000 0000 0000 0000 0001 0000" /* ................ */
$"0000 0000 0000 0000 0000 0000 4000 0000" /* ............@... */
$"00A0 0000 0078 0000 0000 0024 6564 7473" /* .?...x.....$edts */
$"0000 001C 656C 7374 0000 0000 0000 0001" /* ....elst........ */
$"0000 1068 0000 0000 0001 0000 0000 0351" /* ...h...........Q */
$"6D64 6961 0000 0020 6D64 6864 0000 0000" /* mdia... mdhd.... */
$"E143 7EF5 E143 7EF5 0000 0258 0000 1068" /* ?C~??C~?...X...h */
$"0000 003C 0000 003A 6864 6C72 0000 0000" /* ...<...:hdlr.... */
$"6D68 6C72 7669 6465 6170 706C 4000 0000" /* mhlrvideappl@... */
$"0001 002C 1941 7070 6C65 2056 6964 656F" /* ...,.Apple Video */
$"204D 6564 6961 2048 616E 646C 6572 0000" /* Media Handler.. */
derez Wildebeest
data 'moov' (128) {
$"0000 0465 6D6F 6F76 0000 006C 6D76 6864" /* ...emoov...lmvhd */
$"0000 0000 E143 7EF5 E143 7EF5 0000 0258" /* ....?C~??C~?...X */
$"0000 1068 0001 0000 00FF 0000 0000 0000" /* ...h.....?...... */
$"0000 0000 0001 0000 0000 0000 0000 0000" /* ................ */
$"0000 0000 0001 0000 0000 0000 0000 0000" /* ................ */
$"0000 0000 4000 0000 0000 0000 0000 0000" /* ....@........... */
$"0000 0924 0000 0000 0000 0000 0000 0000" /* ...$............ */
$"0000 0002 0000 03D9 7472 616B 0000 005C" /* .......?trak...\ */
$"746B 6864 0000 000F A5EA 1D89 E143 7EF5" /* tkhd....??.??C~? */
$"0000 0001 0000 0000 0000 1068 0000 0000" /* ...........h.... */
$"0000 0000 0000 0000 0000 0000 0001 0000" /* ................ */
$"0000 0000 0000 0000 0000 0000 0001 0000" /* ................ */
$"0000 0000 0000 0000 0000 0000 4000 0000" /* ............@... */
$"00A0 0000 0078 0000 0000 0024 6564 7473" /* .?...x.....$edts */
$"0000 001C 656C 7374 0000 0000 0000 0001" /* ....elst........ */
$"0000 1068 0000 0000 0001 0000 0000 0351" /* ...h...........Q */
$"6D64 6961 0000 0020 6D64 6864 0000 0000" /* mdia... mdhd.... */
$"E143 7EF5 E143 7EF5 0000 0258 0000 1068" /* ?C~??C~?...X...h */
$"0000 003C 0000 003A 6864 6C72 0000 0000" /* ...<...:hdlr.... */
$"6D68 6C72 7669 6465 6170 706C 4000 0000" /* mhlrvideappl@... */
$"0001 002C 1941 7070 6C65 2056 6964 656F" /* ...,.Apple Video */
$"204D 6564 6961 2048 616E 646C 6572 0000" /* Media Handler.. */
The MooV atom is in the Resource Fork. Apple explains why they did it this way.
FILE MOVIE HEADER
Note: the header is safer when stored at the beginning of the file or in the HFS resource fork as type ‘moov’; ID any. The advantage of using another file fork is that the header can be lengthened without recalculating the sample offsets or new header must be written at the end of the file.
QTM-LayoutIf you are playing back a movie on an older Macintosh using an earlier version of Quicktime, you won’t have any issues, but if you plan on playing the movie on a newer system or try and preserve the file, then we run into problems. Especially if the file is moved off of the HFS disk onto a system which doesn’t maintain the resource fork. Then you are stuck with just the data with no way to interpret the movie file.
Solutions.
One solution you can follow is to use MacBinary or AppleSingle to combine the Resource Fork and Data Fork together into one file. You are left with a different format, but one which can be preserved and reverted back to the original when needed.
Another way is to create a Single-Fork Movie file, aka a normal QuickTime file.
“single-fork movie file – A QuickTime movie file
that stores both the movie data and the movie
resource in the data fork of the movie file. You
can use single-fork movie files to ease the
exchange of QuickTime movie data between
Macintosh computers and other computer
systems.”
Creating a Single-Fork can be accomplished a couple different ways. One is to use an older version of QuickTime to “Save As” to a self contained file with the box checked to allow playback on a “non-Apple” computer.

Another method is to use a simple utility called Single Fork Flattener. I found a copy on a old QuickTime disc and uploaded to Macintosh Garden if you want to try it out. No QuickTime needed, just open the file and it updates it to include the MooV resource.

Once combined, MediaInfo now sees a complete QuickTime file which VLC can play!
mediainfo Wildebeest2 General Complete name : Wildebeest Format : QuickTime Format/Info : Original Apple specifications File size : 565 KiB Duration : 7 s 0 ms Overall bit rate : 661 kb/s Frame rate : 10.000 FPS Encoded date : 2023-10-02 14:15:15 UTC Tagged date : 2023-10-02 14:15:15 UTC Writing library : Apple QuickTime FileExtension_Invalid : braw mov qt Video ID : 0 Format : Road Pizza Codec ID : rpza Duration : 7 s 0 ms Bit rate : 659 kb/s Width : 160 pixels Height : 120 pixels Display aspect ratio : 4:3 Frame rate mode : Constant Frame rate : 10.000 FPS Bits/(Pixel*Frame) : 3.434 Stream size : 563 KiB (100%) Language : English Encoded date : 1992-03-16 09:40:25 UTC Tagged date : 2023-10-02 14:15:15 UTCI was hoping I could find a method to use a modern tool to combine into a Single-Fork file, but nothing yet. QuickTime 7 is your best bet for a tool which works on recent MacOS, but not the last couple versions. There is a reference out there to a tool called RezWack, but I have been unable to verify.
Preserving History: Manaki Brothers' Archival Collection Declared Cultural Heritage in North Macedonia
BINHEX
Working with files in todays world is much different than before. Today getting files back and forth from the cloud or through email is relatively easy, unlike the early days when we used FTP sites and needed to encode our data to properly transfer. I remember using an FTP program on my old Mac called Fetch. We had to determine if the content was to be transferred as text or binary.

Picking the right encoding was critical to getting the content transferred correctly, this was even more critical when working with Macintosh files which needed a resource fork and/or finder attributes to work properly. In those cases a MacBinary or BinHex file was required! Fetch would automatically identify those formats and decode them for you.

If you need a refresher on MacBinary and AppleSingle, you can view my iPres 2022 presentation.
One format I didn’t spend much if any time on is the BinHex format. BinHex was a format born out of necessity to move files back and forth across the World Web Web, bulletin boards, AOL, Compuserve, and the like. The FTP program Fetch glossary describes BinHex as:
BinHex (sometimes called BinHex4) is a format for representing a Macintosh file in text form.
The Macintosh file is converted to a series of lines, each made up of letters, numbers, and
punctuation. Because BinHex files are simply text, they can be sent through most electronic mail
systems and stored on most computers. However the conversion to text makes the file larger, so it
takes longer to transmit a file in BinHex format than if the file was represented some other way.
The suffix “.hqx” usually indicates a BinHex format file.
You can still find many of these HQX files floating around the interwebs and on older CDs from the 1990’s. One such CD recently came into my possession. I managed to get a copy of the book “Internet File Formats“, by Tim Kientzie. It came with a CD-ROM with lots of goodies included. Some sample files, specifications, and software. The disc itself is an ISO 9660 partitioned disc, but includes a few Macintosh formats, so the author put many of the software files in the HQX format to maintain the much needed resource fork Macintosh applications need in order to run.
I initially ran the whole disc through DROID to get an idea what was on the disc and if any sample formats were unidentified (something I do regularly), and found majority of the HQX files didn’t identify as they should have to PRONOM PUID x-fmt/416. The signature is an older one, from 2010, but since the format isn’t updated anymore it should be solid. Or so I thought.
Since BINHEX files are encoded as text, lets take a look at a couple of these from the disc which didn’t identify.

The PRONOM signature currently is:
File extension: hqx Name BinHex Binary Text Description Header: (This file must be converted with BinHex Byte sequences Position type Absolute from BOF Offset 0 Value 28546869732066696C65206D75737420626520636F6E76657274656420776974682042696E486578That “Value” listed in hexadecimal decodes to: “(This file must be converted with BinHex” as listed in the description. We can see this line in the file above, but the signature assumes the value begins at offset 0 from the beginning of the file. So its looking for that value at the start of the file, but this file seems to have some additional text before the value. What does the specs say?
The BinHex 4.0 format was created in 1985 and defined in RFC 1741.
The whole file is considered as a stream of bits. This stream will be divided in blocks of 6 bits and then converted to one of 64 characters contained in a table. The characters in this table have been chosen for maximum noise protection. The format will start with a ":" (first character on a line) and end with a ":". There will be a maximum of 64 characters on a line. It must be preceded, by this comment, starting in column 1 (it does not start in column 1 in this document): (This file must be converted with BinHex 4.0) Any text before this comment is to be ignored. The characters used is: !"#$%&'()*+,- 012345689@ABCDEFGHIJKLMNPQRSTUVXYZ[`abcdefhijklmpqrOk, so in the specs we can see the “Value” string must be there, but according to the specification, any text before this comment is to be ignored. So adding some instructions and even an email header at the beginning is ok, as long as the value string is there right before the encoded data.
We also learn a couple interesting things. The first character of the first line after the string should be a “:” and the last line should end with a “:” as well. That could help make the signature more solid. We also learn there are a maximum of 64 characters per line. The last line will probably not have full maximum, but the previous lines should…. I wonder if we could use this fixed position from the initial “:” to add even more strength to the signature.
So an updated PRONOM signature might look like:
BOF: {0-4084}28546869732066696C65206D75737420626520636F6E76657274656420776974682042696E486578{6-9}3A EOF: 3A (Max Offset 64)Adding the 4,084 bytes at the beginning allow for additional text. This value worked for my samples but there could be others out there with more. The {6-9} bytes in between the string and the colon account for the various way newlines are encoded. Sometimes is one “0A” byte, other times it is “OD”, and others its both. After testing, adding values in the signature to account for the 64 byte line can fail if the file has only one line, so I left it out.
The EOF should just be the colon (3A), but I found many of my samples had various line endings and other random characters. Hence the 64 bytes for max offset.
Also, the current PRONOM entry doesn’t include the Mime-Type, which is: “application/mac-binhex40”
Hopefully this update will add some strength to the signature and follow the specification closer. The new signature even works on files with extra content at the beginning!

There are a number of software titles you can use to encode and decode a BinHex file. On a modern Mac, try using The Unarchiver, or Stuffit Expander. From the commandline, you can use the macutil library or the CLI version of Unarchiver. Although the MacOS has a built in utility to decode BinHex files. If you are using a classic version of Macintosh OS, you can find a number of utilities on Macintosh Garden.
Oh, and also, the CD-ROM I mentioned earlier has a few “fun” features. Not sure if they are purpose or if errors were made during mastering, but a few filenames have some hidden extra characters and one folder puts any tool traversing the directory into a loop, even droid. Have fun!
Gone in a Flash
This week I am at the annual iPres digital preservation conference. It is an amazing week of meeting colleagues and old friends who share the same passion of digital preservation. Outside of this community and my co-workers, talking about file formats and digital preservation usually bores people to death and I can hear some of them mumble under their breath, “nerd”! I term I am happy to accept.
At the conference, which is in lovely Urbana-Champaign Illinois this year, I am trying to soak in all the amazing talks and conversations about the challenges facing our work. There were a couple great workshops on Persistent Identifiers and Digital Object Storage Criteria. The presentations I made were of course on File Formats, documentation, and obsolescence. One talk before my panel conversation was about the ubiquitous Adobe Flash format.
The paper, “Around for Decades, Gone in a Flash: How we dealt with Flash objects and the National Archives of the Netherlands” was presented by Lotte Wijsman and Marin Rappard. They knew they had flash objects in their web archives and wanted to go through the process of how they might be preserved and accessed. They started out looking for any files with “FLA”, “SWF”, and “FLV” as extensions. This proved problematic as there were references to those extensions within other documents and objects. They then used DROID to identify the flash formats. “SWF” has quite a number of format PUID’s.
PUIDFormat NameFormat VersionExtensionfmt/104Macromedia Flash1swf,fmt/105Macromedia Flash2swf,fmt/106Macromedia Flash3swf,fmt/107Macromedia Flash4swf,fmt/108Macromedia Flash5swf,fmt/109Macromedia Flash6swf,fmt/110Macromedia Flash7swf,fmt/505Adobe Flash8swf,fmt/506Adobe Flash9swf,fmt/507Adobe Flash10swf,fmt/757Adobe Flash11swf,fmt/758Adobe Flash12swf,fmt/759Adobe Flash13swf,fmt/760Adobe Flash14swf,fmt/761Adobe Flash15swf,fmt/762Adobe Flash16swf,fmt/763Adobe Flash17swf,fmt/764Adobe Flash18swf,fmt/765Adobe Flash19swf,fmt/766Adobe Flash20swf,fmt/767Adobe Flash21swf,fmt/768Adobe Flash22swf,fmt/769Adobe Flash23swf,fmt/770Adobe Flash24swf,fmt/771Adobe Flash25swf,fmt/772Adobe Flash26swf,fmt/773Adobe Flash27swf,fmt/774Adobe Flash28swf,fmt/775Adobe Flash29swf,fmt/776Adobe Flash30swf,Even the Macromedia/Adobe Flash Video format has a PRONOM PUID, x-fmt/382.
The format missing from PRONOM is the FLA format. FLA is the native format for Macromedia/Adobe Flash for saving the source project of your Flash document. SWF files are compiled from the FLA source. This means the the SWF will be the most common format found on the web and in public places, but the FLA format might be more often found on local drives and working folders.
The Flash format and software was actually created by Future Wave software in 1996 as FutureSplash Animator, but was shortly bought by Macromedia later that year and Flash 1.0 was born. FutureSplash used the extension .SPA, but Macromedia changed it to FLA.
The format was initially based on the Microsoft Compound File Format or the OLE container format.
oledir Flash4-S01.fla oledir 0.54 - http://decalage.info/python/oletools OLE directory entries in file Flash4-S01.fla: ----+------+-------+----------------------+-----+-----+-----+--------+------ id |Status|Type |Name |Left |Right|Child|1st Sect|Size ----+------+-------+----------------------+-----+-----+-----+--------+------ 0 |<Used>|Root |Root Entry |- |- |1 |5 |4416 1 |<Used>|Stream |Contents |2 |- |- |6 |4013 2 |<Used>|Stream |Page 1 |- |- |- |0 |329 3 |unused|Empty | |- |- |- |0 |0 ----+----------------------------+------+-------------------------------------- id |Name |Size |CLSID ----+----------------------------+------+-------------------------------------- 0 |Root Entry |- |597CAA70-72AA-11CF-831E-524153480000 1 |Contents |4013 | 2 |Page 1 |329 |The FLA format stayed with OLE until Adobe Flash CS5, which the format changed to use a ZIP container to store all the content.
Flash5.5-S01.fla Type = zip Physical Size = 216632 Date Time Attr Size Compressed Name ------------------- ----- ------------ ------------ ------------------------ 2022-07-09 11:57:46 ..... 25 25 mimetype 2022-07-09 11:57:46 ..... 9 9 Flash5.5-S01.xfl 2022-07-09 11:57:46 D.... 0 0 LIBRARY 2022-07-09 11:57:46 D.... 0 0 META-INF 2022-07-09 11:57:46 ..... 49267 3936 DOMDocument.xml 2022-07-09 11:57:48 ..... 9735 1103 META-INF/metadata.xml 2022-07-09 11:57:48 ..... 8093 2222 PublishSettings.xml 2022-07-09 11:57:48 ..... 0 0 MobileSettings.xml 2022-07-09 11:57:48 D.... 0 0 LIBRARY/Mouth shape graphic symbols 2022-07-09 11:57:48 D.... 0 0 LIBRARY/Voice 2022-07-09 11:57:48 ..... 151006 151006 bin/M 1 1252032698.dat 2022-07-09 11:57:48 ..... 99707 15311 LIBRARY/mouth.xml 2022-07-09 11:57:48 ..... 16510 4534 LIBRARY/Mouth shape graphic symbols/A I.xml 2022-07-09 11:57:48 ..... 14334 4086 LIBRARY/Mouth shape graphic symbols/C D G K N R S Th Y Z.xml 2022-07-09 11:57:48 ..... 14531 4040 LIBRARY/Mouth shape graphic symbols/E.xml 2022-07-09 11:57:48 ..... 15846 4007 LIBRARY/Mouth shape graphic symbols/F V D Th.xml 2022-07-09 11:57:48 ..... 13093 3542 LIBRARY/Mouth shape graphic symbols/L D Th.xml 2022-07-09 11:57:48 ..... 2106 751 LIBRARY/Mouth shape graphic symbols/M B P Closed.xml 2022-07-09 11:57:48 ..... 14130 3949 LIBRARY/Mouth shape graphic symbols/O.xml 2022-07-09 11:57:48 ..... 11082 2951 LIBRARY/Mouth shape graphic symbols/Open_Rest.xml 2022-07-09 11:57:48 ..... 14847 4066 LIBRARY/Mouth shape graphic symbols/U.xml 2022-07-09 11:57:48 ..... 8139 2202 LIBRARY/Mouth shape graphic symbols/W Q.xml 2022-07-09 11:57:48 ..... 15768 3914 LIBRARY/panda.xml 2022-07-09 11:57:48 ..... 10477 1064 LIBRARY/sample graph.xml 2022-07-09 11:57:48 ..... 538 538 bin/SymDepend.cache ------------------- ----- ------------ ------------ ------------------------ 2022-07-09 11:57:48 469243 213256 21 files, 4 foldersThe move to a ZIP container included a new format, XFL. This XFL file is a simple text file with the text “PROXY-CS5″. In the DOMDocument.xml file we find an XML namespace, xmlns=”http://ns.adobe.com/xfl/2008/” and a version of the XFL structure, xflVersion=”2.1″.
This ZIP compressed FLA file is still being used in the current Adobe Animate software, which no longer uses the flash technology and uses more modern web formats like HTML5 to display the animations.
I took each version and made a PRONOM signature, which you can find here with samples. These container signatures should cover all the major changes for the format, but there is a problem……..
Listing archive: Flash5.5-S01v5.fla -- Path = Flash5.5-S01v5.fla Type = zip ERRORS: Headers Error Physical Size = 216581 Embedded Stub Size = 63 Characteristics = Local Date Time Attr Size Compressed Name ------------------- ----- ------------ ------------ ------------------------ 2022-07-09 11:57:46 ..... 25 25 mimetype 2022-07-09 11:57:46 D.... 0 0 LIBRARY 2022-07-09 11:57:46 D.... 0 0 META-INF 2022-07-09 11:57:46 ..... 48556 3742 DOMDocument.xml 2022-07-09 11:57:48 ..... 10133 1112 META-INF/metadata.xml 2022-07-09 11:57:48 ..... 8115 2219 PublishSettings.xml 2022-07-09 11:57:48 ..... 0 0 MobileSettings.xml 2022-07-09 11:57:48 D.... 0 0 LIBRARY/Mouth shape graphic symbols 2022-07-09 11:57:48 D.... 0 0 LIBRARY/Voice 2022-07-09 11:57:48 ..... 151006 151006 bin/M 1 1252032698.dat 2022-07-09 11:57:48 ..... 99551 15319 LIBRARY/mouth.xml 2022-07-09 11:57:48 ..... 16580 4536 LIBRARY/Mouth shape graphic symbols/A I.xml 2022-07-09 11:57:48 ..... 14404 4089 LIBRARY/Mouth shape graphic symbols/C D G K N R S Th Y Z.xml 2022-07-09 11:57:48 ..... 14531 4044 LIBRARY/Mouth shape graphic symbols/E.xml 2022-07-09 11:57:48 ..... 15848 4008 LIBRARY/Mouth shape graphic symbols/F V D Th.xml 2022-07-09 11:57:48 ..... 13024 3546 LIBRARY/Mouth shape graphic symbols/L D Th.xml 2022-07-09 11:57:48 ..... 2106 752 LIBRARY/Mouth shape graphic symbols/M B P Closed.xml 2022-07-09 11:57:48 ..... 14200 3955 LIBRARY/Mouth shape graphic symbols/O.xml 2022-07-09 11:57:48 ..... 11152 2963 LIBRARY/Mouth shape graphic symbols/Open_Rest.xml 2022-07-09 11:57:48 ..... 14777 4069 LIBRARY/Mouth shape graphic symbols/U.xml 2022-07-09 11:57:48 ..... 8287 2228 LIBRARY/Mouth shape graphic symbols/W Q.xml 2022-07-09 11:57:48 ..... 15768 3914 LIBRARY/panda.xml 2022-07-09 11:57:48 ..... 10477 1064 LIBRARY/sample graph.xml 2022-07-09 11:57:48 ..... 538 538 bin/SymDepend.cache 2022-07-09 11:57:46 ..... 25 25 mimetype 2022-07-09 11:58:18 ..... 9 9 Flash5.5-S01v5.xfl ------------------- ----- ------------ ------------ ------------------------ 2022-07-09 11:58:18 469112 213163 22 files, 4 foldersTurns out majority of the samples I have from many versions of Adobe Flash after CS5 have a ZIP Header error. When using the new signatures in DROID, the samples with the header errors will fail in the DROID’s zip library processing. The DROID logs shows this issue:
Could not process the potential container format (ZIP): file:///Flash5.5-S01v5.fla Expected 25 more entries in the Central Directory!The Central Directory header in a ZIP file is quite important to the proper function of the ZIP container. Wikipedia has a great explanation of the header. You may notice in the listing above the file “mimetype” is shown twice which is probably the extra entries the parser wasn’t expecting.
So currently the identification of majority of these FLA formats is on hold until a way is discovered to ignore the error and continue the container identification in DROID.
The call for applications to Round 19 is now open
TIFF
Lets talk TIFF, or Tagged Image File Format. It is well documented and accepted by the community. The format has been around since 1986, first developed by Aldus as a image format for scanners. The TIFF format is now used worldwide as a preferred format for scanning and preservation of cultural heritage objects.
As amazing as the format is, there are a few features of the format which can be a preservation risk. I want to focus on three of those risks.
The Tagged Image File Format has a well known header:
A TIFF file begins with an 8-byte image file header, containing the following information: Bytes 0-1: The byte order used within the file. Legal values are: “II” (4949.H) LSB (IBM) “MM” (4D4D.H) MSB (Mac) Bytes 2-3 An arbitrary but carefully chosen number (42). Bytes 4-7 The offset (in bytes) of the first IFD.Putting this poster of the TIFF structure in your office will impress your co-workers, guaranteed. Thanks Ange!

The three risks I have been pondering lately are:
- Multiple IFD’s
- Metadata
- DNG format
TIFF version 6.0 was released in 1992 and is the most recent version. Although some vendors are free to add their own private tags. In 1995 Adobe added an addendum which added some additions for use with PageMaker.
One of the main features of the TIFF format is its ability to hold multiple pages. In Adobe’s words:
TIFF has always supported what amounts to a singly linked list of IFD’s in a single TIFF file, via the “next IFD pointer,” though most applications currently ignore any IFD beyond the first one. Probably the best use for a linked list of IFD’s is when you want to store multiple different but related images in the same file—a ‘burst’ of images from a camera, for example.
Adobe PageMaker® 6.0 TIFF Technical NotesTake note of the highlighted text, software like Adobe Photoshop will ignore any IFD beyond the first one. Even worse, Photoshop won’t even mention there are additional IFD’s. I have used many document scanners which default to multipage TIFF capture and have lost pages because of this. Because of this I have always built my workflows around single page TIFF’s for all scanning and we check against this as a rule.
What also makes this hard is how some capture software uses additional IFD’s. CaptureOne is a popular imaging software used by photographers and cultural heritage institutions. We have used it to connect to our PhaseOne cameras for capture of books and other flat objects. By default the software exports the final TIFF image with a thumbnail.

With the “No Thumbnail” unchecked we get this TIFF structure:
identify _MG_0193.tif _MG_0193.tif[0] TIFF 3456x5184 3456x5184+0+0 8-bit sRGB 51.3136MiB 0.030u 0:00.026 _MG_0193.tif[1] TIFF 107x160 107x160+0+0 8-bit sRGB 0.000u 0:00.007 <IFD0:ImageWidth>3456</IFD0:ImageWidth> <IFD0:ImageHeight>5184</IFD0:ImageHeight> <IFD1:SubfileType>Reduced-resolution image</IFD1:SubfileType> <IFD1:ImageWidth>107</IFD1:ImageWidth> <IFD1:ImageHeight>160</IFD1:ImageHeight> <IFD1:BitsPerSample>8 8 8</IFD1:BitsPerSample>So Imagemagick identifies two pages 0 and 1 with the second a much smaller resolution than the first. Exiftool reports back IFD0 and IFD1 with IFD1 having a SubfileType of a Reduced-resolution image. Makes sense, it is a thumbnail. In looking at the specifications for TIFF 6.0, I can find no mention of the word “thumbnail”, but the specification does make mention of “reduced resolution” images:
If multiple subfiles are written, the first one must be the full-resolution image. Subsequent images, such as reduced-resolution images, may be in any order in the TIFF file.
The specification also gives us this warning:
TIFF readers must be prepared for multiple images (subfiles) per TIFF file, although they are not required to do anything with images after the first one.
Scary to think about how a reader is not required to do anything, not even warn against multiple IFD’s (Subfiles).
The EXIF specifications seem to expand on this through attributes:
Attribute information can be recorded in 2 IFDs (0th IFD, 1st IFD) following the TIFF structure, including the File Header. The 0th IFD records compressed image attributes (the image itself). The 1st IFD may be used for thumbnail images.
Page 97 of EXIF SpecificationTake a look at the information and Figure 6 on page 21-22 in the EXIF specification.
Adobe early on decided to use their own tags for thumbnail data. Since Photoshop 5, Adobe has stored the thumbnail in Tag 1036.
1036 Photoshop Thumbnail : (Binary data 4625 bytes, use -b option to extract)There is another TIFF structure sometimes used in older FAX compressed multipage TIFFs and now used in the DNG Specification. The SubIFD tag was writable using the libtiff “thumbnail” tool, but is now depreciated. Originally described in the TIFF/EP specification, DNG files use SubIFD trees.
DNG files are often talked about in the same way TIFF files are, and many tools handle both seamlessly. One of the major differences is that DNG files switch their IFD use. IFD0 is often the reduced-resolution thumbnail and SubIFD the full-resolution image.
<IFD0:SubfileType>Reduced-resolution image</IFD0:SubfileType> <IFD0:ImageWidth>256</IFD0:ImageWidth> <IFD0:ImageHeight>171</IFD0:ImageHeight> <SubIFD:SubfileType>Full-resolution image</SubIFD:SubfileType> <SubIFD:ImageWidth>3516</SubIFD:ImageWidth> <SubIFD:ImageHeight>2328</SubIFD:ImageHeight>This can cause issues when trying to extract technical metadata from images, knowing which IFD to get the main image details requires a bit of work. I’ll save DNG for another blog post.
TIFF Metadata is a vital part of preservation. The metadata can provide technical properties of the file along with some descriptive information. It amazes me how much the embedded metadata can vary from a scanner or camera capture device. The digitization lab I worked in for years had scanners from Epson, Fujitu, Canon and others. Along with cameras made by Canon, PhaseOne, and Copibooks. Each one with a vastly different set of metadata using different standards. Even when each workflow produced final uncompressed TIFF images, they all varied in metadata.
The TIFF images with the leasT amount of metadata was from the Epson scanners. When using the free Epson Scan software, not a single metadata field was embedded, no dates, scanner model or manufacturer. More was embedded when you used the Silverfast professional software included with each Epson, but even then if you didn’t add any IPTC fields, the metadata was limited.
The most metadata came from the camera systems, especially the PhaseOne/CaptureOne systems. Even though it produced the most and had valuable properties, there were some issues. I already discussed the thumbnail issue, but PhaseOne decided they wanted to change how some of the tags were used.
CaptureOne has quite the list of white balance options. Which is great for the photographer, but not so great for adhering to the TIFF standard.

According to the EXIF TIFF Specification, there are only two values allowed for White Balance, Auto or Manual. A CaptureOne produced TIFF will have this value if Auto or Manual are not chosen:
41987 White Balance : Unknown (5) 37384 Light Source : OtherThe different lighting situations should be identified using the “Light Source” 37384 tag, but alas they chose to add to white balance instead. When I asked about this, they responded that they requested this update to the TIFF spec, but they weren’t willing so they took matters into their own hands. You can read the conversation on the JHOVE issues page.
The TIFF format is very accepted in the Cultural Heritage community as a preferred preservation format. The specification is well understood and documented. I just hope we can continue to openly discuss issues that arise in preservation which add risk to our collections. Some issues are minor compared to others. Sometimes it’s the tools we use to validate formats like TIFF which are wrong and need to be corrected. The talk more about these issues and how to manage them.
HighMAT
Before the days of streaming and devices likeSmart TVs, AppleTV and Fire sticks, a few companies tried their best to come up with ways to make viewing your media on your TV mainstream. In a previous blog post I touched on the Kodak PhotoCD method, but there is one you are probably even less familiar with. HighMAT. HighMAT, or High-Performance Media Access Technology was a technology co-developed by Microsoft and Panasonic. You may have at one point owned a DVD player which had the technology built-in, but may have never used it. It came on the scene around 2002, but was abandoned by 2008.
 Panasonic DVD/CD Player with HighMAT playback.
Panasonic DVD/CD Player with HighMAT playback.
There were quite a few devices stamped with the HighMAT logo. The technology allow you to playback any Audio and Images like a DVD, with a menu and everything.
There was three different types of HighMAT compatible devices, Audio, Audio-Image, and Audio-Image-Video.

Writing data to the HighMAT format could be done with a plugin for Windows which added the functionality to Windows Media Player for burning audio playlists to the HighMAT format or through the standard CD Writing Wizard built-in to Windows XP. An extra screen would come up asking if you would like to make the CD HighMAT compatible. Making video compatible HighMAT CDs could be done through Movie Maker.

When a HighMAT CD-R/CD-RW is authored we get an interesting CD. It appears to be a Mode 2 Form 1 format:
/dev/disk10 (internal, physical): #: TYPE NAME SIZE IDENTIFIER 0: CD_partition_scheme *846.4 MB disk10 1: CD_ROM_Mode_2_Form_1 Highmat02 2.7 MB disk10s0If you would like to check out a sample disc, you can grab the ISO or BIN/CUE here.
tree /Volumes/Highmat02 /Volumes/Highmat02 ├── Audio\ Samples │ ├── 17\ [no\ artist]\ -\ Speaker\ Identification\ Test.wma │ └── sine.wma ├── HIGHMAT │ ├── AUTHOR.XML │ ├── CONTENTS.HMT │ ├── IMAGES │ │ ├── T0.HMT │ │ ├── T1.HMT │ │ ├── T10.HMT │ │ ├── T11.HMT │ │ ├── T12.HMT │ │ ├── T13.HMT │ │ ├── T2.HMT │ │ ├── T3.HMT │ │ ├── T4.HMT │ │ ├── T5.HMT │ │ ├── T6.HMT │ │ ├── T7.HMT │ │ ├── T8.HMT │ │ └── T9.HMT │ ├── MENU.HMT │ ├── PLAYLIST │ │ ├── 00000001.HMT │ │ ├── 00000002.HMT │ │ ├── 00000003.HMT │ │ ├── 00000004.HMT │ │ ├── 00000005.HMT │ │ ├── 00000006.HMT │ │ └── 00000007.HMT │ └── TEXT.HMT └── My\ Pics ├── Blue\ hills.jpg ├── Sunset.jpg ├── Water\ lilies.jpg └── Winter.jpg 5 directories, 31 filesThere is a lot going on here, lets take a look at a few of the formats we find in this disc structure. The files added to the CD are converted to WMA if you checked the “Convert Files” feature and are accessible like a normal data CD. The HighMAT folder is created to make a compatible HighMAT disc. Except for one XML file the rest of the files in the HighMAT folder all have an HMT extension. The author.xml file contains the root element <HMT> with some filenames indicating some of the HMT files may be thumbnails. If we open one of the HMT thumbnail files in a hex editor we can see:

Just a plain old JPG header. Exiftool tells us it is small 160×120 pixel image, must be a thumbnail. But lets take a look at another HMT file.

Even though the Menu.hmt file has the same extension as the thumbnails, this file is definitely not a JPG file with pixel data. Same goes for the Contents and Text files as well, unique formats.

The files in the playlist folder also have a unique format.

So it seems all the HighMAT folder really does is add compatibility for hardware to provide a menu to access the original data, providing playlists and thumbnails to navigate the data on your TV screen.
I came across one of these discs while processing a collection of CD-R discs donated to our library. Normally I would copy the images and other data off the disc to our preservation system, but this disc made me stop to think about the best way to preserve the data. Is a disc image appropriate or is the HighMAT folder even worth preserving if we have the original files from the disc? Finding hardware or a software player to present the disc as intended is getting harder to do. I am curious what others think of the value of this content.
I chose not to submit any signatures to PRONOM for the moment as we assess. It would be difficult to properly identify each format with all of them having the same extension, especially the JPG thumbnails as HMT is not a valid extension for the format. Take a look at my sample files and if you have come across this format before.
Apple Package Format
Let’s talk about Apple’s iWork software. Apple’s Office Suite of applications was first released in 2005 and provided a WordProcessor (Pages), Presentations (Keynote), and a little later, Spreadsheet (Numbers). They are exclusive to the Macintosh and iOS devices.
iWork was released in a few different versions. They get a little confusing as each application has its own version which all seemed to unify and stabilize in 2020. Here is a matrix of major versions.
VersionPackage or ZIPiWork ’05PackageiWork ’06PackageiWork ’08PackageiWork ’09ZIPiWork 2013PackageiWork 2014ZIPiWork 2019ZIPiWork 2020ZIPYou may already be aware but MacOS can sometimes be weird. I use the term weird in a loving, sometimes proud way, but I admit, there was some “odd” choices made in regards to how applications and documents are used and stored files on a Mac.
On early Macintosh computers Apple used an interesting method of storing resources for applications and some file formats. The Resource Fork for an application contained all the “resources” needed to run in the operating system. It would contain all the icons, warning screens, graphics, sounds, etc. This help true until Mac OS X came along and then Apple started using a bundle or package format. Still in use today, what appears to be a single file or application is actually a folder of all the resources needed to run the application.
By right clicking or control clicking on the icon you can open the folder and see all the contents which make up the Application.
Nifty right? The MacOS which knows which extensions to treat as a package. If you were to move the application over to another system it would be a folder with the extension “.app”.
For an application I can see how this makes sense as it will only execute in the MacOS environment. The problem comes in when you use the same package method for the documents the application creates.

So instead of a single “file” with a bytestream, you get a folder of files which make up the file format. Here is Apple’s description:
Document PackagesIf your document file formats are getting too complex to manage because of several disparate types of data, you might consider adopting a package format for your documents. Document packages give the illusion of a single document to users but provide you with flexibility in how you store the document data internally. Especially if you use several different types of standard data formats, such as JPEG, GIF, or XML, document packages make accessing and managing that data much easier.
Apple actually defines two similar methods:
Although bundles and packages are sometimes referred to interchangeably, they actually represent very distinct concepts:
- A package is any directory that the Finder presents to the user as if it were a single file.
- A bundle is a directory with a standardized hierarchical structure that holds executable code and the resources used by that code.
A couple years ago a processed digital collection made its way down to me. It had been processed by a new digital archivist and when I went to prepare the collection for preservation, I found a folder with the extension .pages and inside the folder a whole directory of files. Many of which they had renamed and arranged. Needless to say, I had to track down the original disk so I could properly preserve the file.
So looking back at the earlier table, iWork switched back and forth between the package format and a ZIP container. For preservation purposes, the ZIP container is easier to maintain outside the MacOS. Lets look a little closer at each. If you would like to follow along I have copied a few samples onto a hybrid ISO.
iWork ’05 through iWork ’08 used the same package format and structure. Because they are a package format, they are difficult to preserve as original files. I suppose you could zip them up, but probably the best option is to open with a current version of Pages and save to the newer ZIP container format.
tree iWork08/Keynote-06.key ├── Contents │ └── PkgInfo ├── QuickLook │ └── Thumbnail.jpg ├── index.apxl.gz └── theme-files ├── Blue 2.jpg ├── Blue 2.tif ├── Cool Gray-2.jpg ├── Cool Gray.tif ├── Green-8.jpg ├── Green.tif ├── Headlines_bullet.pdf ├── Headlines_star.pdf ├── Orange 2.tif ├── Orange_2.jpg ├── Purple-6.jpg ├── Purple.tif ├── Red.jpg ├── Red.tif ├── endpoints.pdf └── headlines_hi-res.jpgiWork ’09 changed this practice. The documents saved from Pages, Keynote, and Numbers were contained in a ZIP file and can be identified using the PRONOM registry container signatures.
filename : 'iWork 2013/Pages2013-Sample09.pages' filesize : 105900 modified : 2019-11-21T20:36:00-07:00 matches : - ns : 'pronom' id : 'fmt/1439' format : 'Apple iWork Pages' version : '09' class : 'Word Processor' basis : 'extension match pages; container name index.xml with byte match at 195, 76' Sample09.pages Type = zip WARNINGS: Headers Error Physical Size = 105900 Date Time Attr Size Compressed Name ------------------- ----- ------------ ------------ ------------------------ 2019-11-21 20:36:00 ..... 364773 22413 index.xml 2019-11-21 20:36:00 ..... 7007 7007 Hardcover_bullet_black.png 2019-11-21 20:36:00 ..... 69176 69176 Simple_Noise_2x.jpg 2019-11-21 20:36:00 ..... 232 232 buildVersionHistory.plist 2019-11-21 20:36:00 ..... 6406 6406 QuickLook/Thumbnail.png ------------------- ----- ------------ ------------ ------------------------ 2019-11-21 20:36:00 447594 105234 5 filesThen Apple went back to a Package format with iWork 2013. For reasons unknown. But the content and structure changed. Its a package format with a Index.zip instead of index.xml
Pages2013-Sample.pages ├── Data │ └── Hardcover_bullet_black-13.png ├── Index.zip ├── Metadata │ ├── BuildVersionHistory.plist │ ├── DocumentIdentifier │ └── Properties.plist ├── preview-micro.jpg ├── preview-web.jpg └── preview.jpg 3 directories, 8 filesThe ZIP within the package contains a new Apple format. IWA
Pages2013-Sample.pages/Index.zip Type = zip Physical Size = 39361 Date Time Attr Size Compressed Name ------------------- ----- ------------ ------------ ------------------------ 2019-11-21 20:47:14 ..... 3860 3860 Index/Document.iwa 2019-11-21 20:47:14 ..... 26 26 Index/Tables/DataList.iwa 2019-11-21 20:47:14 ..... 336 336 Index/ViewState.iwa 2019-11-21 20:47:14 ..... 160 160 Index/CalculationEngine.iwa 2019-11-21 20:47:14 ..... 121 121 Index/DocumentStylesheet.iwa 2019-11-21 20:47:14 ..... 31931 31931 Index/ThemeStylesheet.iwa 2019-11-21 20:47:14 ..... 22 22 Index/AnnotationAuthorStorage.iwa 2019-11-21 20:47:14 ..... 1889 1889 Index/Metadata.iwa ------------------- ----- ------------ ------------ ------------------------ 2019-11-21 20:47:14 38345 38345 8 filesLuckily Apple came to their senses and went back to the ZIP container format for iWork 2014 and later. The container signature looks for the IWA file Apple started using with iWork 2013.
filename : 'iWork 2014/Pages2014-Sample.pages' filesize : 66256 modified : 2019-11-22T00:03:56-07:00 errors : matches : - ns : 'pronom' id : 'fmt/1441' format : 'Apple iWork Document' version : '14' class : 'Presentation, Spreadsheet, Word Processor' basis : 'extension match pages; container name Index/Document.iwa with byte match at 16, 6; name Metadata/Properties.plist with name only' Path = iWork 2014/Pages2014-Sample.pages Type = zip Physical Size = 66256 Date Time Attr Size Compressed Name ------------------- ----- ------------ ------------ ------------------------ 2019-11-22 00:03:54 ..... 3930 3930 Index/Document.iwa 2019-11-22 00:03:54 ..... 364 364 Index/ViewState.iwa 2019-11-22 00:03:54 ..... 206 206 Index/CalculationEngine.iwa 2019-11-22 00:03:54 ..... 33573 33573 Index/DocumentStylesheet.iwa 2019-11-22 00:03:54 ..... 22 22 Index/AnnotationAuthorStorage.iwa 2019-11-22 00:03:54 ..... 23 23 Index/DocumentMetadata.iwa 2019-11-22 00:03:54 ..... 8761 8761 Index/Metadata.iwa 2019-11-22 00:03:54 ..... 322 322 Metadata/Properties.plist 2019-11-22 00:03:54 ..... 36 36 Metadata/DocumentIdentifier 2019-11-22 00:03:54 ..... 273 273 Metadata/BuildVersionHistory.plist 2019-11-22 00:03:54 ..... 14611 14611 preview.jpg 2019-11-22 00:03:54 ..... 838 838 preview-micro.jpg 2019-11-22 00:03:54 ..... 1571 1571 preview-web.jpg ------------------- ----- ------------ ------------ ------------------------ 2019-11-22 00:03:54 64530 64530 13 filesNow iWork was not the only Apple software to use the Package/Bundle format for their documents. Be advised the following software may save to the package format.
- Aperture Library
- Final Cut Pro X
- Soundtrack Pro
- Apple Motion
- Garageband Project
- DVD Studio Pro
- iMovie Project
- Logic Pro Project
- RTFd document
I remember a few years ago, Trent Reznor (NIN) decided to release a few of his tracks in the Garageband format. A little harder to find these days, but the good old wayback machine kept a copy for us! Grab them here. Be warned, they may be in the package format. Thanks Apple!
Student Writing Center
When it comes to difficult file formats, one of the more difficult groups of formats are word processing text files. Difficult for many reasons, one being the shear number of them, the other is their lack of identifiable headers. Just when you think you have seen them all another pops up to add to the mix.
In a batch of other known word processing formats I came across a few files with no extension and with the following header:

The rest of the file was binary so the only thing I had to go one was the string “TLC” and “FF”. A few searches across the interwebs didn’t reveal much, seems it wasn’t a well documented format. From the names of the files and the fact they were with other word processing formats led me to assume they were also some sort of document format. The date stamps were still intact and I could see they were from the mid 1990’s. It took a few creative searches before I wondered if the “TLC” might have something to do with “The Learning Company“. If it was, I still had quite a bit of work ahead as the software developer had produced quite a few titles over the years. You probably remember the “Reader Rabbit” series of educational games.
After a bit of time I narrowed it down to a few titles and started looking for samples of each. Software was hard to find as well. I tried opening the file in a few different software until I finally came to one called “Student Writing Center”. Which may sound familiar to some of you, but there was some variations on this name out there. Some of which are:
- Student Writing Center
- Student Writing & Publishing Center
- The Children’s Writing & Publishing Center
- The Writing Center
- Ultimate Writing & Creativity Center
There were probably others, considering the budget software company started in 1980 and made titles for a few computer platforms starting with the Apple II. The story behind the company is a fun read.
The Student Writing Center was a simple word processor aimed at students 10 years old and older. It was found in many schools right along side Kid Pix, another very popular graphic program for kids. The software had a few different document types to help students get started writing their book reports or journal entries.
The Student Writing Center ran on both Macintosh and Windows allowing it to be one of the more popular writing tools for the younger crowd.
Each document type had a unique interface and save menu, which on Windows would save with the extensions, .RP, .NL, .JN, .LT, and .SG. They also had a slightly different header.
Reports: 1A544C43 01464600 0000 Newsletters: 1A544C43 00464600 0300 Journals: 1A544C43 00464600 0100 Letters: 1A544C43 00464600 0400 Signs: 1A544C43 00464600 0200The signatures submitted to PRONOM take into account endianness for Windows and Macintosh with the last two byte locations being swapped. Also every document had the values “46461A” “FF” at the end of the file.
But wait! Just when you think you had it figured out…….

This file may look similar, but they are two different formats and are not compatible with each other. The little brother to the Student Writing Center was called “Ultimate Writing & Creativity Center” and was made for younger kids, ages 6-10. It had more of a cartoon interface and a cute little fountain pen teacher to walk you through the writing process.

When you saved your file in UWCC, you could choose between formats and I guess move your documents up to the more advanced program once you turned 10! If you would like to experience or re-live the opening sequence, enjoy.
I’m not done yet………
To complicate things even more The Learning Company also released another word processor called “The Writing Center“. This gets confused with Student Writing Center frequently.

But unlike the two others, this format is very different.
We’ll have to save this format for another day.
There seems to be a never ending list of word processor formats, with no end in sight. But if you used a school computer back in the early 1990’s and still have your floppy disk from back then, hopefully now you can open that report you wrote on Abraham Lincoln.
Stampa Migrante: a Window on Multi-Lingual Egypt
DiskDoubler
A few years ago I had someone contact me with a desperate plea. They had a disk which contained years of journal entries and letters to loved ones she could no longer access. She had used a Macintosh in the late 1980’s and early 1990’s to create all these files, but wanted to convert them all to PDF so she could make a book. She said she had tried everything, contacted a lot of people and her son had told her it was a lost cause. In talking with others at my institution, they knew I had a background in older Macintosh formats and so she contacted me. I made no promises, but offered to try.
The files she provided were indeed early Macintosh files. One obvious trait was the lack of an extension. One might think a lack of an extension was poor planning for Apple, but they choose a different method for the operating system to know the relationship between files and applications. They did this through the use of a Type/Creator code. If you were a software developer for the Macintosh you could register a four character “Creator” code, then for all the different files you used with your software you could register a “Type” code. This told the Macintosh operating system exactly which software created the file and the type so it could be opened properly. Unlike today where an extension is defaulted to one application even if it isn’t the software which created the file.
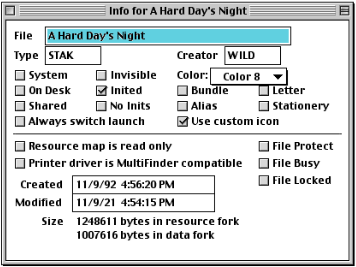 ResEdit view of Hypercard Stack Info
ResEdit view of Hypercard Stack Info
In some ways this was a superior identification method as there was many software titles which could all create the same file format, but this way the correct software would open the file and render it correctly.
Looking at the files provided to me, there was a few which at first seemed like they were damaged somehow, they were extremely small compared to the other files. About half the size. When I opened them in a hex editor this is what I saw.
Usually document formats during this time would keep the text in plain ascii, but these files were different, they had binary data. In the header was the only plain text strings in the file, “WDBNMSWD”. I had seen these codes before, a Microsoft Word Document! But they weren’t….. What are they?
The head of the file has the hex values “ABCD0054”, so I started searching the internet for some help. There were others having the same problem I was having. I finally came across a tool called the “Unarchiver“. Running the command line version of the software “unar”, suddenly I had a file twice the size and could be opened by Microsoft Word!
unar Letter Letter: DiskDoubler "./Letter" already exists. Successfully extracted to "./Letter-1".
Remember back in the 1990’s when storage was expensive? Instead of dropping another $20 for a 100MB ZIP Disk, you could use Symantec’s DiskDoubler. The software would be installed on your Macintosh and then a window would come up showing you all the files on your drive. With one click you could compress a single file or a directory of files saving you tons of space. When you needed the file, just double click and the software would uncompress on the fly and then open the correct application to edit the file.

With a few clicks I was able to uncompress all the affected files and provide a PDF of all the letters and journals my new friend had tried so desperately for years to open. She was thrilled to say the least.
But why stop there? PRONOM needs to know about this format!
Once I had DiskDoubler installed I could make a few more samples, where is where I found there was a few different compression methods used by the software. They are labeled AD 1 & 2 and DD 1, 2 & 3. Making samples of each of the different types I was able to confirm the first 4 bytes of every file was the hex values “ABCD0054”. I was able to submit the format to PRONOM and it was added and given the PUID fmt/1399.
One of the other features of DiskDoubler was an ability to create a Self Extracting Archive (SEA). An sea file could contain a compressed file but also contained the code to uncompress itself. This was mostly seen with the Stuffit software, but there were many other compression tools which could write to this format. The Stuffit formats have been added to PRONOM which include identification of an SEA created by stuffit, but the SEA created by DiskDoubler is different and needs to be added.

New online - July 2023
Pagina's







")

































































")

")






























")























")







")
")
")




")
")







]")







")
")



































")






")
")

")

















")








")






")

")






Publicatie waarin een norm is vastgelegd.